This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the recent discussion and advancements surrounding artificial intelligence, there’s a notable dialogue between discriminative and generative AI approaches. These methodologies represent distinct paradigms in AI, each with unique capabilities and applications. What is Generative AI?
Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. For geographical analysis, Random Forest, SupportVectorMachines (SVM), and k-nearestNeighbors (k-NN) are three excellent methods. So, Who Do I Have?
SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space. Example: Training an AI agent to play chess by exploring different moves and receiving rewards for winning games while penalising losses.
Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. R has become ideal for GIS, especially for GIS machine learning as it has topnotch libraries that can perform geospatial computation. R has simplified the most complex task of geospatial machine learning and data science. data = trainData) 5.
LaMDA, GPT, and more… Nowadays, everyone talking about AI models and what they are capable of. The use of AI models is expanding rapidly across all industries. AI’s capacity to find solutions to difficult issues with minimal human input is a major selling point for the technology. What is an AI model?
LaMDA, GPT, and more… Nowadays, everyone talking about AI models and what they are capable of. The use of AI models is expanding rapidly across all industries. AI’s capacity to find solutions to difficult issues with minimal human input is a major selling point for the technology. What is an AI model?
Last Updated on January 29, 2024 by Editorial Team Author(s): Shivamshinde Originally published on Towards AI. SupportVectorMachine Classification and Regression C: This hyperparameter decides the regularization strength. It can have values: [‘l1’, ‘l2’, ‘elasticnet’, ‘None’]. C can take any positive float value.
Last Updated on April 17, 2023 by Editorial Team Author(s): Kevin Berlemont, PhD Originally published on Towards AI. The prediction is then done using a k-nearestneighbor method within the embedding space. Photo by Artem Maltsev on Unsplash Who hasn’t been on Stack Overflow to find the answer to a question?
That’s why diversifying enterprise AI and ML usage can prove invaluable to maintaining a competitive edge. What is machine learning? ML is a computer science, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions.
SupportVectorMachines (SVM) : SVM is a powerful Eager Learning algorithm used for both classification and regression tasks. Popular examples of Eager Learning algorithms include Logistic Regression, Decision Trees, Random Forests, SupportVectorMachines (SVM), and Neural Networks.
Examples include Logistic Regression, SupportVectorMachines (SVM), Decision Trees, and Artificial Neural Networks. Instead, they memorise the training data and make predictions by finding the nearest neighbour. Examples include K-NearestNeighbors (KNN) and Case-based Reasoning.
This harmonization is particularly critical in algorithms such as k-NearestNeighbors and SupportVectorMachines, where distances dictate decisions. Scaling steps in as a guardian, harmonizing the scales and ensuring that algorithms treat each feature fairly.
This type of machine learning is useful in known outlier detection but is not capable of discovering unknown anomalies or predicting future issues. Isolation forest models can be found on the free machine learning library for Python, scikit-learn. Through fast and comprehensive analysis, IBM watson.ai
But I also want truly define that ML isn’t represent some kind of unsecured AI technologies, super brain or dark magic, it’s clear combination of programming skills, enough amount of data, cloud solutions, theory of algorithms and math — that’s all we should have to be able to work in this branch. In this article, I will cover all of them.
For larger datasets, more complex algorithms such as Random Forest, SupportVectorMachines (SVM), or Neural Networks may be more suitable. In contrast, for datasets with low dimensionality, simpler algorithms such as Naive Bayes or K-NearestNeighbors may be sufficient. Thanks for your support!
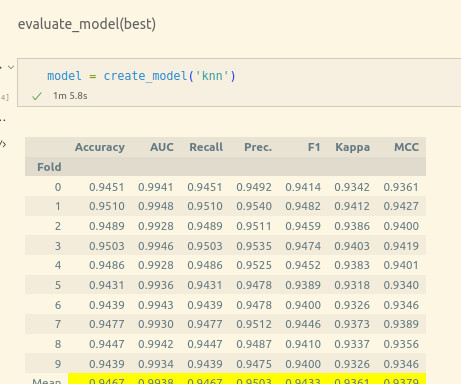
With the preprocessed data in hand, we can now employ pyCaret, a powerful machine learning library, to build our predictive models. pyCaret simplifies the machine learning pipeline by automating various steps, such as feature selection, model training, hyperparameter tuning, and model evaluation.
With the explosion of AI across industries TensorFlow has also grown in popularity due to its robust ecosystem of tools, libraries, and community that keeps pushing machine learning advances. As expected with the rise of AI, machine learning libraries and data science-focused libraries will become the most popular ones of 2023.
Last Updated on July 19, 2023 by Editorial Team Author(s): Anirudh Chandra Originally published on Towards AI. among supervised models and k-nearestneighbors, DBSCAN, etc., Photo by Jair Lázaro on Unsplash The second part of the step-by-step walk-through to analyze and predict the survival of heart failure patients.
In 2023, the expected reach of the AI market is supposed to reach the $500 billion mark and in 2030 it is supposed to reach $1,597.1 49% of companies in the world that use Machine Learning and AI in their marketing and sales processes apply it to identify the prospects of sales.
K-NearestNeighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance. A smaller k implies the model is influenced by a limited number of neighbours, causing predictions to be more sensitive to noise in the training data.
Ethical considerations are crucial in developing fair Machine Learning solutions. Basics of Machine Learning Machine Learning is a subset of Artificial Intelligence (AI) that allows systems to learn from data, improve from experience, and make predictions or decisions without being explicitly programmed. Random Forests).
Every Machine Learning algorithm, whether a decision tree, supportvectormachine, or deep neural network, inherently favours certain solutions over others. k-NearestNeighbors (k-NN) The k-NN algorithm assumes that similar data points are close to each other in feature space.
Artificial Intelligence (AI): A branch of computer science focused on creating systems that can perform tasks typically requiring human intelligence. Association Rule Learning: A rule-based Machine Learning method to discover interesting relationships between variables in large databases.
The time has come for us to treat ML and AI algorithms as more than simple trends. We are no longer far from the concepts of AI and ML, and these products are preparing to become the hidden power behind medical prediction and diagnostics. SVM classifiers work by finding a hyperplane that separates the data points into two classes.
This allows organizations to grow their AI capabilities more efficiently without needing to rebuild their entire data collection and labeling process for each new use case. They are: Based on shallow, simple, and interpretable machine learning models like supportvectormachines (SVMs), decision trees, or k-nearestneighbors (kNN).
AI now plays a pivotal role in the development and evolution of the automotive sector, in which Applus+ IDIADA operates. In this post, we showcase the research process undertaken to develop a classifier for human interactions in this AI-based environment using Amazon Bedrock.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content