This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction MapReduce is part of the ApacheHadoop ecosystem, a framework that develops large-scale data processing. Other components of ApacheHadoop include Hadoop Distributed File System (HDFS), Yarn, and Apache Pig.
They work at the intersection of various technical domains, requiring a blend of skills to handle data processing, algorithm development, system design, and implementation. Machine Learning Algorithms Recent improvements in machine learning algorithms have significantly enhanced their efficiency and accuracy.
Summary: This blog delves into the multifaceted world of BigData, covering its defining characteristics beyond the 5 V’s, essential technologies and tools for management, real-world applications across industries, challenges organisations face, and future trends shaping the landscape.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Programming languages like Python and R are commonly used for data manipulation, visualization, and statistical modeling. Machine learning algorithms play a central role in building predictive models and enabling systems to learn from data. Data Science, however, uses predictive and prescriptive solutions.
A generative AI company exemplifies this by offering solutions that enable businesses to streamline operations, personalise customer experiences, and optimise workflows through advanced algorithms. Data forms the backbone of AI systems, feeding into the core input for machine learning algorithms to generate their predictions and insights.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. What is ApacheHadoop?
Knowledge of visualization libraries, such as Matplotlib, Seaborn, or ggplot, and understanding design principles can help in creating compelling visual representations of data. Additionally, knowledge of model evaluation, hyperparameter tuning, and model selection is valuable.
Predictive Analytics Projects: Predictive analytics involves using historical data to predict future events or outcomes. Techniques like regression analysis, time series forecasting, and machine learning algorithms are used to predict customer behavior, sales trends, equipment failure, and more.
As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. The programming language can handle BigData and perform effective data analysis and statistical modelling. This tool may mimic difficult regression as well as classification issues.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
Java: Scalability and Performance Java is renowned for its scalability and robustness, making it an excellent choice for handling large-scale data processing. With its powerful ecosystem and libraries like ApacheHadoop and Apache Spark, Java provides the tools necessary for distributed computing and parallel processing.
Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decision trees, and support vector machines. To obtain practical expertise, run the algorithms on datasets. It is critical for knowing how to work with huge data sets efficiently.
Advanced crawling algorithms allow them to adapt to new content and changes in website structures. Precision: Advanced algorithms ensure they accurately categorise and store data. Apache Nutch A powerful web crawler built on ApacheHadoop, suitable for large-scale data crawling projects.
Data Lakes Data lakes are centralized repositories designed to store vast amounts of raw, unstructured, and structured data in their native format. They enable flexible data storage and retrieval for diverse use cases, making them highly scalable for bigdata applications.
Summary: Depth First Search (DFS) is a fundamental algorithm used for traversing tree and graph structures. Introduction Depth First Search (DFS) is a fundamental algorithm in Artificial Intelligence and computer science, primarily used for traversing or searching tree and graph data structures. What is Depth First Search?
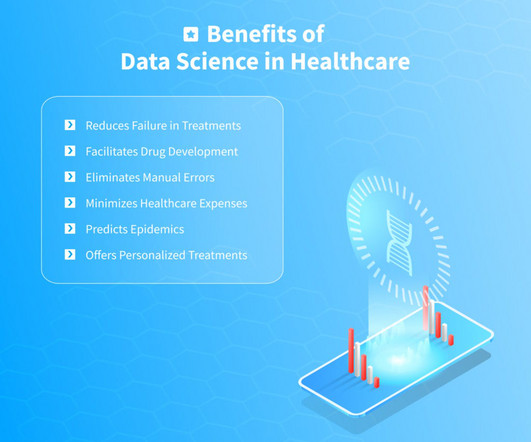
As a discipline that includes various technologies and techniques, data science can contribute to the development of new medications, prevention of diseases, diagnostics, and much more. Utilizing BigData, the Internet of Things, machine learning, artificial intelligence consulting , etc.,
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigData analytics provides a competitive advantage and drives innovation across various industries.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content