This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
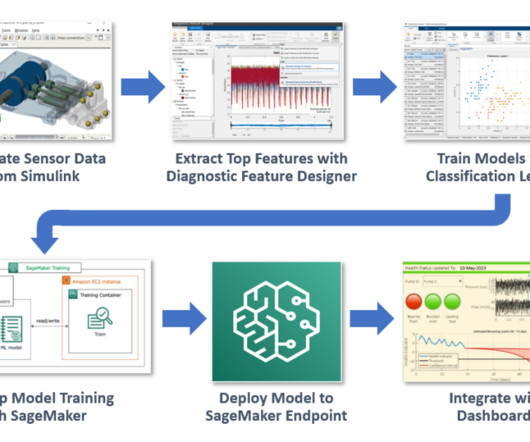
In recent years, MathWorks has brought many product offerings into the cloud, especially on Amazon Web Services (AWS). Because we have a model of the system and faults are rare in operation, we can take advantage of simulated data to train our algorithm. Here is a quick guide on how to run MATLAB on AWS. Either Ubuntu or Linux.
These tools leverage advanced algorithms and methodologies to process large datasets, uncovering valuable insights that can drive strategic decision-making. Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. It offers an AWS CloudFormation template for straightforward deployment in an AWS account.
To achieve this, our process uses a synchronization algorithm that is trained on a labeled dataset. This algorithm robustly associates each shot with its corresponding tracking data. Shot speed calculation The heart of determining shot speed lies in a precise timestamp given by our synchronization algorithm.
Different algorithms and techniques are employed to achieve eventual consistency. Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS). They use redundancy and replication to ensure data availability.
We use Amazon SageMaker to train a model using the built-in XGBoost algorithm on aggregated features created from historical transactions. Apache Flink is a popular framework and engine for processing data streams. Prerequisites We provide an AWS CloudFormation template to create the prerequisite resources for this solution.
It utilises Amazon Web Services (AWS) as its main data lake, processing over 550 billion events daily—equivalent to approximately 1.3 Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs. petabytes of data.
The field has evolved significantly from traditional statistical analysis to include sophisticated Machine Learning algorithms and Big Data technologies. Issues such as algorithmic bias, data privacy, and transparency are becoming critical topics of discussion within the industry.
Techniques like regression analysis, time series forecasting, and machine learning algorithms are used to predict customer behavior, sales trends, equipment failure, and more. Use machine learning algorithms to build a fraud detection model and identify potentially fraudulent transactions.
ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing. Tooling : Apache Tika , ElasticSearch , Databricks , and AWS Glue for metadata extraction and management. It allows unstructured data to be moved and processed easily between systems.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Also, while it is not a streaming solution, we can still use it for such a purpose if combined with systems such as ApacheKafka.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content