This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
Photo by Avi Waxman on Unsplash What is KNN Definition K-NearestNeighbors (KNN) is a supervised algorithm. The basic idea behind KNN is to find Knearest data points in the training space to the new data point and then classify the new data point based on the majority class among the knearest data points.
In the recent discussion and advancements surrounding artificialintelligence, there’s a notable dialogue between discriminative and generative AI approaches. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world. What is Generative AI?
The K-NearestNeighborsAlgorithm Math Foundations: Hyperplanes, Voronoi Diagrams and Spacial Metrics. Throughout this article we’ll dissect the math behind one of the most famous, simple and old algorithms in all statistics and machine learning history: the KNN. Photo by Who’s Denilo ? Photo from here 2.1
Technicalities of vector databases Using a vector database enables the incorporation of advanced functionalities into our artificialintelligence, such as semantic information retrieval and long-term memory. Nearestneighbor search algorithms : Efficiently retrieving the closest patient vec t o r s to a given query.
Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit. K-NearestNeighbors (KNN) is a supervised ML algorithm for classification and regression.
Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme. Shall we unravel the true meaning of machine learning algorithms and their practicability?
Choose an Appropriate Algorithm As with all machine learning processes, algorithm selection is also crucial. K-nearestneighbors are sufficient for detecting specific medialike in copyright protectionbut less reliable when analyzing a broad range of factors.
Photo Mosaics with NearestNeighbors: Machine Learning for Digital Art In this post, we focus on a color-matching strategy that is of particular interest to a data science or machine learning audience because it utilizes a K-nearestneighbors (KNN) modeling approach.
Leveraging a comprehensive dataset of diverse fault scenarios, various machine learning algorithms—including Random Forest (RF), K-NearestNeighbors (KNN), and Long Short-Term Memory (LSTM) networks—are evaluated.
However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions. This is the k-nearestneighbor (k-NN) algorithm.
Artificialintelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. An AI model is a crucial part of artificialintelligence. What is an AI model?
Artificialintelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. An AI model is a crucial part of artificialintelligence. What is an AI model?
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. ML is a computer science, data science and artificialintelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. What is machine learning?
In this blog we’ll go over how machine learning techniques, powered by artificialintelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
However, with a wide range of algorithms available, it can be challenging to decide which one to use for a particular dataset. In this article, we will discuss some of the factors to consider while selecting a classification & Regression machine learning algorithm based on the characteristics of the data.
Basically, Machine learning is a part of the Artificialintelligence field, which is mainly defined as a technic that gives the possibility to predict the future based on a massive amount of past known or unknown data. ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module.
Machine Learning is a subset of artificialintelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples.
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. By analyzing how users have interacted with items in the past, we can use algorithms to approximate the utility function and make personalized recommendations that users will love.
But heres the catch scanning millions of vectors one by one (a brute-force k-NearestNeighbors or KNN search) is painfully slow. Instead, vector databases rely on Approximate NearestNeighbors (ANN) techniques, which trade a tiny bit of accuracy for massive speed improvements. 💡 Why?
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. The user input is converted into embeddings using the Amazon Titan Text Embeddings model accessed using Amazon Bedrock. An OpenSearch Service vector search is performed using these embeddings.
Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many data scientists. It is easy to use, with a well-documented API and a wide range of tutorials and examples available.
Key steps involve problem definition, data preparation, and algorithm selection. Basics of Machine Learning Machine Learning is a subset of ArtificialIntelligence (AI) that allows systems to learn from data, improve from experience, and make predictions or decisions without being explicitly programmed.
This retrieval can happen using different algorithms. Formally, often k-nearestneighbors (KNN) or approximate nearestneighbor (ANN) search is often used to find other snippets with similar semantics. Semantic retrieval BM25 focuses on lexical matching.
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. ArtificialIntelligence (AI): A branch of computer science focused on creating systems that can perform tasks typically requiring human intelligence.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Looking for the source code to this post?
Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. For some applications, such as fraud detection or cancer prediction, we may need to configure our model carefully or artificially balance the dataset, such as by undersampling or oversampling each class.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters. The results show that most of them were indeed labeled incorrectly.
HOGs are great feature detectors and can also be used for object detection with SVM but due to many other State of the Art object detection algorithms like YOLO, SSD, present out there, we don’t use HOGs much for object detection. This is a simple project. I have used Boston Housing Data for this use case.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science? Let us see some examples.
improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases.
Machine learning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificialintelligence.
Causal AI refers to a specialized field of artificialintelligence that focuses on identifying cause-and-effect relationships within data. Discover causal relationships: Algorithms sift through data, uncovering connections that signify causality rather than simply correlation. What is causal AI?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























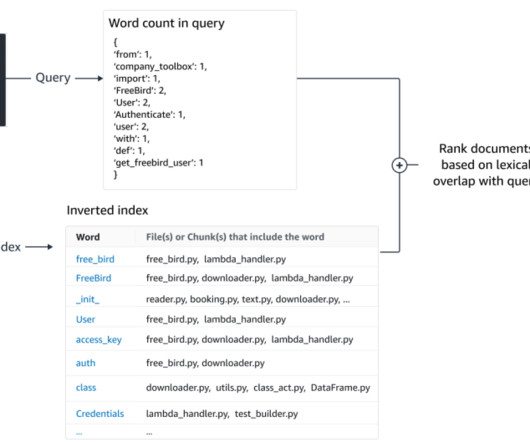















Let's personalize your content