This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Introduction Machine learning can seem overwhelming at first – from choosing the right algorithms to setting up infrastructure. Hey dear reader!
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Leave us a comment and we will be glad to collaborate.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. A provisioned or serverless Amazon Redshift data warehouse. Choose Create stack. Sohaib Katariwala is a Sr.
Spark is well suited to applications that involve large volumes of data, real-time computing, model optimization, and deployment. Read about Apache Zeppelin: Magnum Opus of MLOps in detail AWS SageMaker AWS SageMaker is an AI service that allows developers to build, train and manage AI models.
Previously, OfferUps search engine was built with Elasticsearch (v7.10) on Amazon Elastic Compute Cloud (Amazon EC2), using a keyword search algorithm to find relevant listings. The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture.
For instance, a Data Science team analysing terabytes of data can instantly provision additional processing power or storage as required, avoiding bottlenecks and delays. The cloud also offers distributed computing capabilities, enabling faster processing of complex algorithms across multiple nodes.
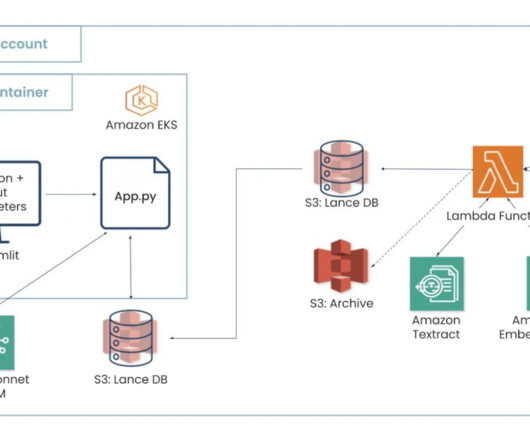
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). Control plane and data plane implementation SnapLogic’s Agent Creator platform follows a decoupled architecture, separating the control plane and data plane for enhanced security and scalability.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it. Subscribe an AWS Lambda function to the SQS queue.
Sagemaker provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment.
Swallow training Experiment management We discuss topics relevant to machine learning (ML) researchers and engineers with experience in distributed LLM training and familiarity with cloud infrastructure and AWS services. The base infrastructure stack is available as an AWS CloudFormation template for seamless deployment and replication.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
Based on our experiments using best-in-class supervised learning algorithms available in AutoGluon , we arrived at a 3,000 sample size for the training dataset for each category to attain an accuracy of 90%. AWS SDKs and authentication Verify that your AWS credentials (usually from the SageMaker role) have Amazon Bedrock access.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
This process significantly benefits from the MLOps features of SageMaker, which streamline the data science workflow by harnessing the powerful cloud infrastructure of AWS. The following diagram illustrates the inference pipeline. Click here to open the AWS console and follow along.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. NLTK is appreciated for its broader nature, as it’s able to pull the right algorithm for any job. There’s even a more specific version, Spark NLP, which is a devoted library for language tasks.
AWS is especially well suited to provide enterprises the tools necessary for deploying LLMs at scale to enable critical decision-making. In their implementation of generative AI technology, enterprises have real concerns about data exposure and ownership of confidential information that may be sent to LLMs.
Apart from supporting explanations for tabular data, Clarify also supports explainability for both computer vision (CV) and natural language processing (NLP) using the same SHAP algorithm. We also provide a general design pattern that you can use while using Clarify with any of the SageMaker algorithms.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. This will lead to algorithm development for any machine or deep learning processes.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
When answering a new question in real time, the input question is converted to an embedding, which is used to search for and extract the most similar chunks of documents using a similarity metric, such as cosine similarity, and an approximate nearest neighbors algorithm. The search precision can also be improved with metadata filtering.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
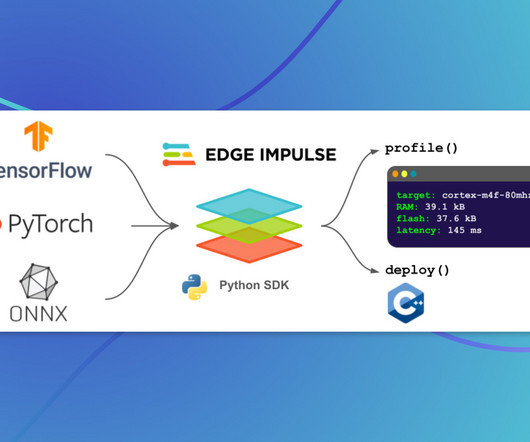
With their groundbreaking web-based Studio platform, engineers have been able to collect data, develop and tune ML models, and deploy them to devices. This has empowered teams to quickly create and optimize models and algorithms that run at peak performance on any edge device. The Edge Impulse SDK is designed to be one of them.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Role of Data Transformation in Analytics, Machine Learning, and BI In Data Analytics, transformation helps prepare data for various operations, including filtering, sorting, and summarisation, making the data more accessible and useful for Analysts. Why Are Data Transformation Tools Important?
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data. Implement high-quality AIOps and MLOps with IBM Turbonomic AIOps and MLOps are integral to maintaining a competitive edge in a big data world.
Pinecone and Weaviate are popular managed vector database platforms that can efficiently scale to handle billions of documents and return relevant embeddings using an approximate nearest neighbor (ANN) algorithm. Chroma is a popular open-source vector database with an ANN algorithm; however, it currently does not support hybrid search.
Researchers rely on its rich content to experiment with novel architectures, fine-tune domain-specific applications, and benchmark new algorithms. The dataset has also been instrumental in advancing multilingual NLP models and enhancing AI ethics research by exposing biases in training data.
Data Versioning Data is often considered the lifeblood that fuels the algorithms in an ML pipeline. Tracking changes and lineage ensures traceability for downstream components of the ML pipeline ingesting the data. This helps manage data drift and maintain the integrity of training and test sets.
And that includes data. Given that the whole theory of machine learning assumes today will behave at least somewhat like yesterday, what can algorithms and models do for you in such a chaotic context ? 3 To redesign and rewrite the architecture as Infrastructure as Code (using AWS Cloudformation).
Just as a writer needs to know core skills like sentence structure and grammar, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and soon. Environments Data science environments encompass the tools and platforms where professionals perform their work.
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. Implementation of metadata-driven datapipelines for governance and reporting. This is where AI truly shines.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition.
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
Python has long been the favorite programming language of data scientists. Historically, Python was only supported via a connector, so making predictions on our energy data using an algorithm created in Python would require moving data out of our Snowflake environment.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do data analysis BI report generation/data analysis In BI/data analysis world, people usually need to query data (small/large).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content