This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS SageMaker is transforming the way organizations approach machine learning by providing a comprehensive, cloud-based platform that standardizes the entire workflow, from datapreparation to model deployment. What is AWS SageMaker?
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe. Check out the Cohere on AWS GitHub repo.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. For Elastic Inference , choose none.
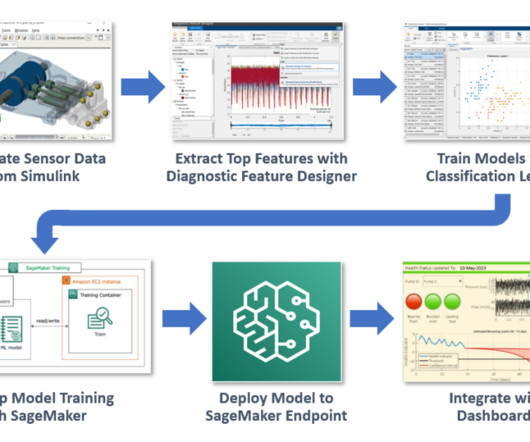
In recent years, MathWorks has brought many product offerings into the cloud, especially on Amazon Web Services (AWS). We have access to a large repository of labeled data generated from a Simulink simulation that has three possible fault types in various possible combinations (for example, one healthy and seven faulty states).
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
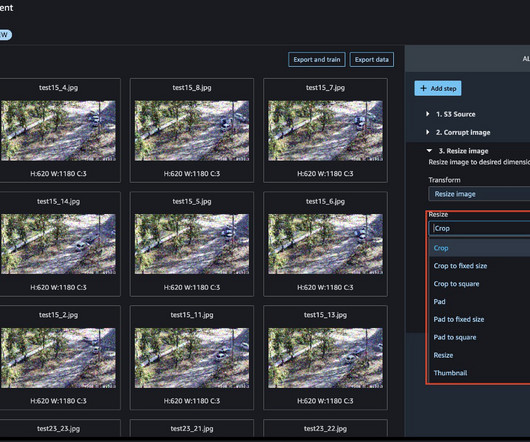
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import.
Amazon Personalize provisions the necessary infrastructure and manages the entire machine learning (ML) pipeline, including processing the data, identifying features, using the most appropriate algorithms, and training, optimizing, and hosting the models. An interaction is an event that you record and then import as training data.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
Sagemaker provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment.
Through ML EBA, experienced AWS ML subject matter experts work side by side with your cross-functional team to provide prescriptive guidance, remove blockers, and build organizational capability for a continued ML adoption. Additionally, AWS can offer financial incentives to help offset the costs for your first ML use case.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. Across 180 countries, millions of developers and hundreds of thousands of businesses use Twilio to create magical experiences for their customers.
Boomi funded this solution using the AWS PE ML FastStart program, a customer enablement program meant to take ML-enabled solutions from idea to production in a matter of weeks. However, the underlying algorithm for Step Suggest is complicated and proprietary. Boomi had significant success with their application of Markov chains.
Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. He focuses on developing scalable machine learning algorithms.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. Prerequisites Before diving into this use case, complete the following prerequisites: Set up an AWS account. The BlazingText algorithm expects a single preprocessed text file with space-separated tokens.
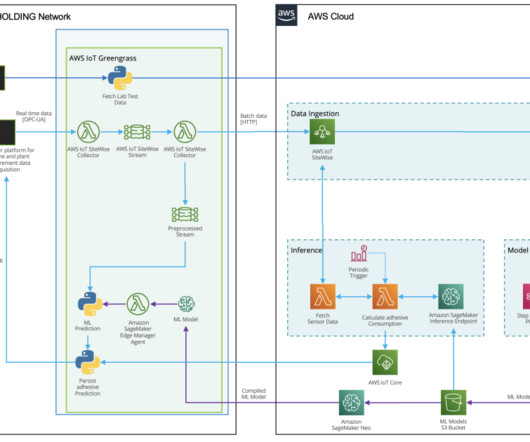
Input data is streamed from the plant via OPC-UA through SiteWise Edge Gateway in AWS IoT Greengrass. Model training and optimization with SageMaker automatic model tuning Prior to the model training, a set of datapreparation activities are performed. Samples are sent to a laboratory for quality tests.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as data quality, algorithm, scalability, and domain knowledge, to mention a few. We will introduce a custom classifier training pipeline that can be deployed in your AWS account with few clicks.
While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. This will land on a data flow page. Choose your domain.
The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. The system is developed by a team of dedicated applied machine learning (ML) scientists, ML engineers, and subject matter experts in collaboration between AWS and Talent.com.
The Ranking team at Booking.com plays a pivotal role in ensuring that the search and recommendation algorithms are optimized to deliver the best results for their users. One of the several challenges faced was adapting the existing on-premises pipeline solution for use on AWS.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. Prerequisites For this walkthrough, you should have the following prerequisites: An AWS account set up.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
We finish with a case study highlighting the benefits realize by a large AWS and PwC customer who implemented this solution. Solution overview AWS offers a comprehensive portfolio of cloud-native services for developing and running MLOps pipelines in a scalable and sustainable manner.
In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload. Datapreparation LLM developers train their models on large datasets of naturally occurring text.
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
Be sure to check out his talk, “ Build Classification and Regression Models with Spark on AWS ,” there! In the unceasingly dynamic arena of data science, discerning and applying the right instruments can significantly shape the outcomes of your machine learning initiatives. A cordial greeting to all data science enthusiasts!
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. An AWS Glue crawler creates or updates the AWS Glue Data Catalog from the uploaded file in the S3 bucket for an Amazon Athena table.
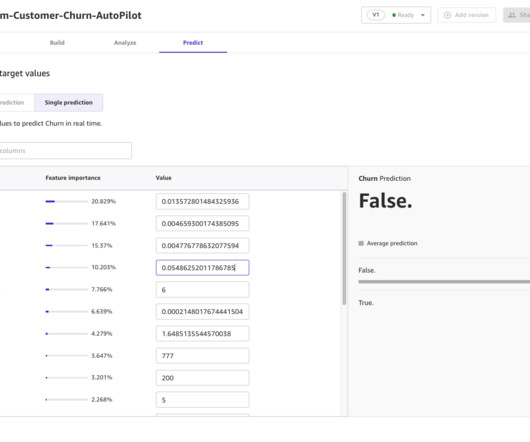
We explain the metrics and show techniques to deal with data to obtain better model performance. Prerequisites If you would like to implement all or some of the tasks described in this post, you need an AWS account with access to SageMaker Canvas. Let’s try to improve the model performance using a data-centric approach.
This helps with datapreparation and feature engineering tasks and model training and deployment automation. One benefit of this step is the ability to use built-in algorithms for common data transformations and automatic scaling of resources. The following diagrams illustrates the high-level architecture of the solution.
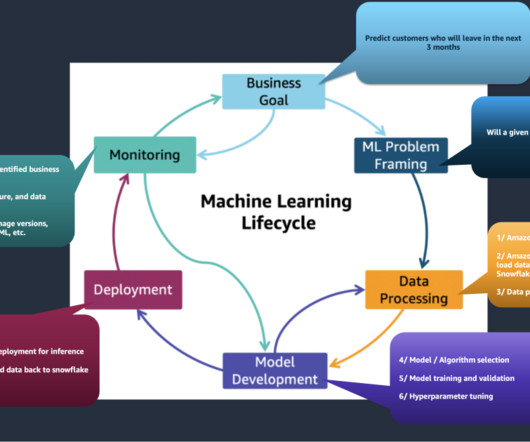
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
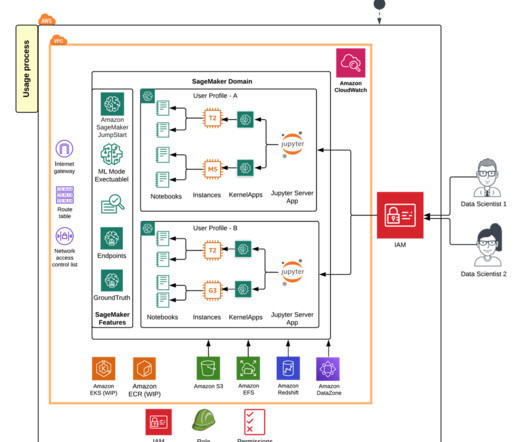
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. Select Other type of secret. Save the secret and note the ARN of the secret.
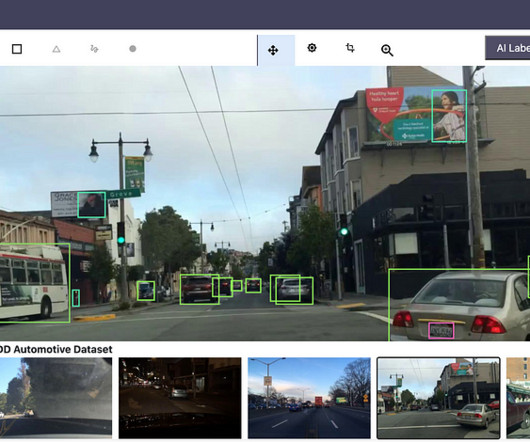
Machine learning algorithms use these sets of visual data to look for statistical patterns to identify which image features allow you to assume that it is worthy of a particular label or diagnosis. Veda technologies enable faster data processing, task automation, and organization of patient information. Indium Software.
80% of the time goes in datapreparation ……blah blah…. In short, the whole datapreparation workflow is a pain, with different parts managed or owned by different teams or people distributed across different geographies depending upon the company size and data compliances required. What is the problem statement?
With AWS ML, organizations can accelerate the value creation from months to days. Now let’s assume the role of a data scientist who is looking to train, build, deploy, and share ML models with a business analyst for each of these three architectural patterns. Let’s assume the role of a data scientist.
This means empowering business analysts to use ML on their own, without depending on data science teams. Canvas helps business analysts apply ML to common business problems without having to know the details such as algorithm types, training parameters, or ensemble logic. Happy innovating!
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content