This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Today, we’ll explore why Amazon’s cloud-based machine learning services could be your perfect starting point for building AI-powered applications.
Alternatives to Rekognition people pathing One alternative to Amazon Rekognition people pathing combines the open source ML model YOLOv9 , which is used for object detection, and the open source ByteTrack algorithm, which is used for multi-object tracking. About the Authors Fangzhou Cheng is a Senior Applied Scientist at AWS.
Large-scale deeplearning has recently produced revolutionary advances in a vast array of fields. is a startup dedicated to the mission of democratizing artificial intelligence technologies through algorithmic and software innovations that fundamentally change the economics of deeplearning.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Key Skills: Mastery in machine learning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods.
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Cloud Computing: AWS, Google Cloud, Azure (for deploying AI models) Soft Skills: 1. Adaptability and Continuous Learning 4.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
There are several ways AWS is enabling ML practitioners to lower the environmental impact of their workloads. Inferentia and Trainium are AWS’s recent addition to its portfolio of purpose-built accelerators specifically designed by Amazon’s Annapurna Labs for ML inference and training workloads. times higher inference throughput.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Machine learning (ML), especially deeplearning, requires a large amount of data for improving model performance. Customers often need to train a model with data from different regions, organizations, or AWS accounts. Federated learning (FL) is a distributed ML approach that trains ML models on distributed datasets.
AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Prerequisites If youre new to AWS, you first need to create and set up an AWS account. We use Amazon S3 to store sample documents that are used in this solution.
They work at the intersection of various technical domains, requiring a blend of skills to handle data processing, algorithm development, system design, and implementation. Machine LearningAlgorithms Recent improvements in machine learningalgorithms have significantly enhanced their efficiency and accuracy.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. The example extracts and contextualizes the buildspec-1-10-2.yml
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
Source: [link] This article describes a solution for a generative AI resume screener that got us 3rd place at DataRobot & AWS Hackathon 2023. You can also set the environment variables on the notebook instance for things like AWS access key etc. Source: author’s screenshot on AWS We used Anthropic Claude 2 in our solution.
AWS and NVIDIA have come together to make this vision a reality. AWS, NVIDIA, and other partners build applications and solutions to make healthcare more accessible, affordable, and efficient by accelerating cloud connectivity of enterprise imaging. AHI provides API access to ImageSet metadata and ImageFrames.
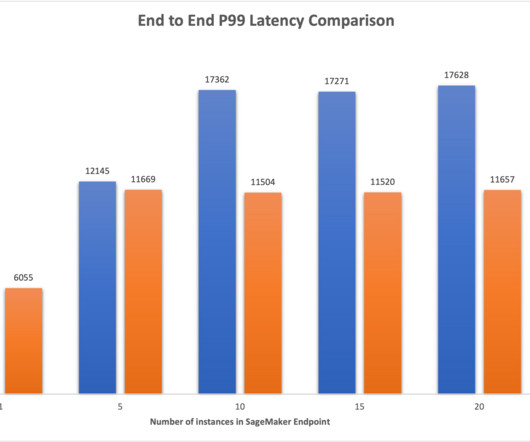
In this post, we focus on how you can take advantage of the AWS Graviton3 -based Amazon Elastic Compute Cloud (EC2) C7g instances to help reduce inference costs by up to 50% relative to comparable EC2 instances for real-time inference on Amazon SageMaker. 4xlarge (AWS Graviton3) is about 50% of the c5.4xlarge and 40% of c6i.4xlarge;
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
To achieve this, the Rufus team is using multiple AWS services and AWS AI chips, AWS Trainium and AWS Inferentia. Inferentia and Trainium are purpose-built chips developed by AWS that accelerate deeplearning workloads with high performance and lower overall costs.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services.
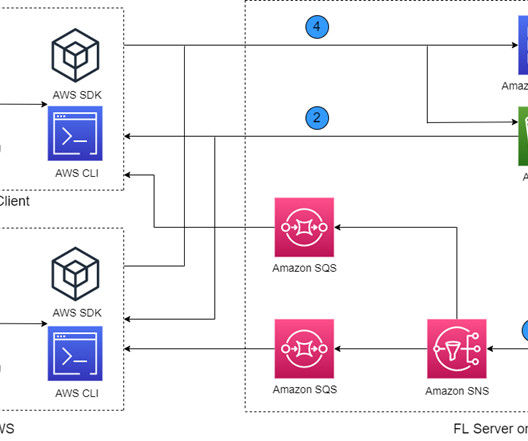
In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. We have developed an FL framework on AWS that enables analyzing distributed and sensitive health data in a privacy-preserving manner. In this post, we showed how you can deploy the open-source FedML framework on AWS.
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS).
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
Therefore, we decided to introduce a deeplearning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships. Recommendation model using NCF NCF is an algorithm based on a paper presented at the International World Wide Web Conference in 2017.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. It involves training a global machine learning (ML) model from distributed health data held locally at different sites. Request a VPC peering connection.
Source: Author Introduction Deeplearning, a branch of machine learning inspired by biological neural networks, has become a key technique in artificial intelligence (AI) applications. Deeplearning methods use multi-layer artificial neural networks to extract intricate patterns from large data sets.
To address customer needs for high performance and scalability in deeplearning, generative AI, and HPC workloads, we are happy to announce the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P5e instances, powered by NVIDIA H200 Tensor Core GPUs. Karthik Venna is a Principal Product Manager at AWS.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). To address customers’ requirements about data privacy and sovereignty, SnapLogic deploys the data plane within the customer’s VPC on AWS.
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
Data is the foundation for machine learning (ML) algorithms. Canvas provides connectors to AWS data sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. In this post, we describe how to query Parquet files with Athena using AWS Lake Formation and use the output Canvas to train a model.
The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. The system is developed by a team of dedicated applied machine learning (ML) scientists, ML engineers, and subject matter experts in collaboration between AWS and Talent.com.
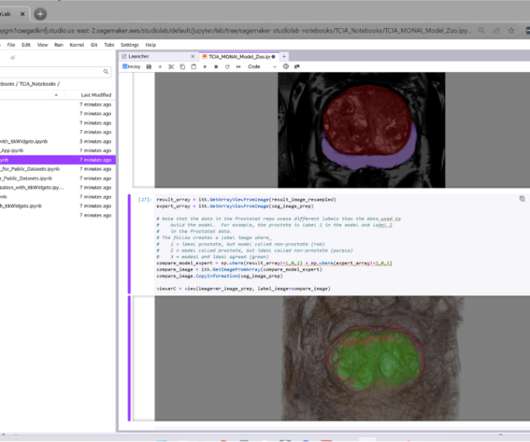
The second notebook shows how the expert annotations that are available for hundreds of studies on TCIA can be downloaded as DICOM SEG and RTSTRUCT objects, visualized in 3D or as overlays on 2D slices, and used for training and evaluation of deeplearning systems. Gang Fu is a Healthcare Solution Architect at AWS.
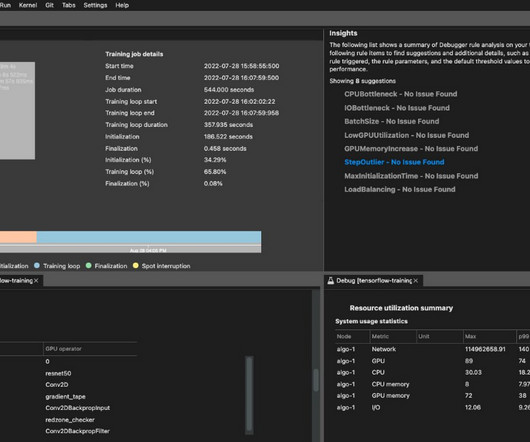
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. Since its introduction, we’ve helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage.
Amazon Personalize makes it straightforward to personalize your website, app, emails, and more, using the same machine learning (ML) technology used by Amazon, without requiring ML expertise. For Recipe , choose the new aws-user-personalization-v2 recipe. Rishabh Agrawal is a Senior Software Engineer working on AI services at AWS.
Amazon SageMaker provides an end-to-end set of services that allow Amazon Music to build, train, and deploy on the AWS Cloud with minimal effort. By taking care of the undifferentiated heavy lifting, SageMaker allows you to focus on working on your machine learning (ML) models, and not worry about things such as infrastructure.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
KT used AWS and Amazon SageMaker to train this AI Food Tag model 29 times faster than before and optimize it for production deployment with a model distillation technique. To accelerate training and generate a student model in less time, KT partnered with AWS. Together, the teams significantly reduced model training time.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deeplearning. Thirdly, the presence of GPUs enabled the labeled data to be processed.
The Ranking team at Booking.com plays a pivotal role in ensuring that the search and recommendation algorithms are optimized to deliver the best results for their users. One of the several challenges faced was adapting the existing on-premises pipeline solution for use on AWS.
In the context of deeplearning, the predominant numerical format used for research and deployment has so far been 32-bit floating point, or FP32. However, the need for reduced bandwidth and compute requirements of deeplearning models has driven research into using lower-precision numerical formats.
Amazon SageMaker makes it straightforward to deploy machine learning (ML) models for real-time inference and offers a broad selection of ML instances spanning CPUs and accelerators such as AWS Inferentia. The endpoint uniformly distributes incoming requests to ML instances using a round-robin algorithm.
The model diverges from traditional embedding models by employing deeplearning to evaluate the alignment between each document and the query directly. An AWS Identity and Access Management (IAM) role with the AmazonSageMakerFullAccess policy attached.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content