This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. For example, you can give users access permission to download popular packages and customize the development environment.
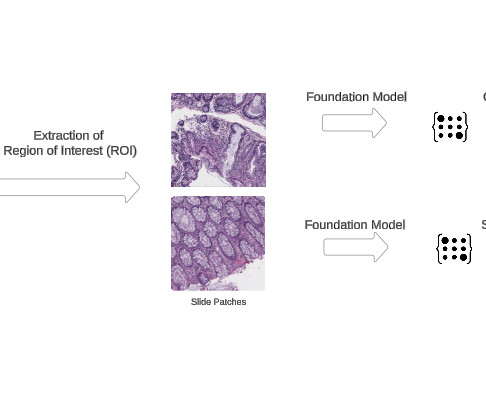
These models are trained using self-supervised learning algorithms on expansive datasets, enabling them to capture a comprehensive repertoire of visual representations and patterns inherent within pathology images. Prerequisites We assume you have access to and are authenticated in an AWS account.
AWS has always provided customers with choice. In terms of hardware choice, in addition to NVIDIA GPUs and AWS custom AI chips, CPU-based instances represent (thanks to the latest innovations in CPU hardware) an additional choice for customers who want to run generative AI inference, like hosting small language models and asynchronous agents.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
The integrated approach and ease of use of Amazon Bedrock in deploying large language models (LLMs), along with built-in features that facilitate seamless integration with other AWS services like Amazon Kendra, made it the preferred choice. This workflow integrates AWS services to extract, process, and make content available for querying.
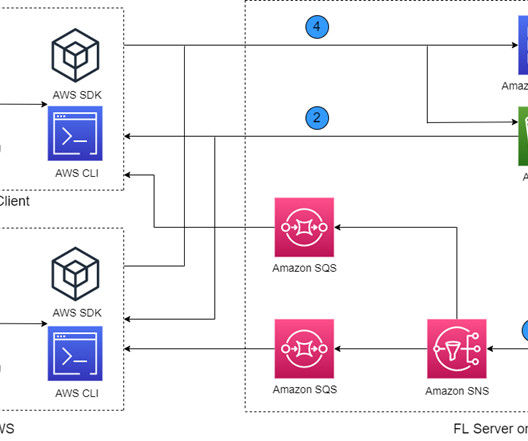
Customers often need to train a model with data from different regions, organizations, or AWS accounts. Existing partner open-source FL solutions on AWS include FedML and NVIDIA FLARE. These open-source packages are deployed in the cloud by running in virtual machines, without using the cloud-native services available on AWS.
You can then export the model and deploy it on Amazon Sagemaker on Amazon Web Server (AWS). If you are set up with the required systems, you can download the sample project and complete the steps for hands-on learning. The example model predicts how likely a customer is to enroll in a Demand Response Program of a Utilities Company.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. Open the AWS Management Console, go to Amazon Bedrock, and choose Model access in the navigation pane.
Data scientists and developers can use the SageMaker integrated development environment (IDE) to access a vast array of pre-built algorithms, customize their own models, and seamlessly scale their solutions. You may be prompted to subscribe to this model through AWS Marketplace. If so, skip to the next section in this post.
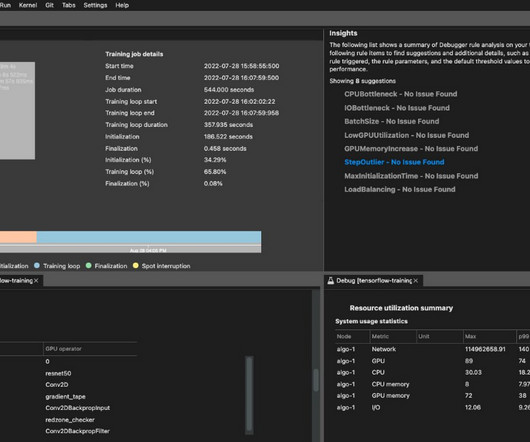
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Today, AWS AI released GraphStorm v0.4. Prerequisites To run this example, you will need an AWS account, an Amazon SageMaker Studio domain, and the necessary permissions to run BYOC SageMaker jobs. Using SageMaker Pipelines to train models provides several benefits, like reduced costs, auditability, and lineage tracking. million edges.
Solution overview The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. Click here to open the AWS console and follow along. The endpoint lifecycle is orchestrated through dedicated AWS Lambda functions that handle creation and deletion.
To mitigate these risks, the FL model uses personalized training algorithms and effective masking and parameterization before sharing information with the training coordinator. Therefore, ML creates challenges for AWS customers who need to ensure privacy and security across distributed entities without compromising patient outcomes.
AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Prerequisites If youre new to AWS, you first need to create and set up an AWS account. We download the documents and store them under a samples folder locally.
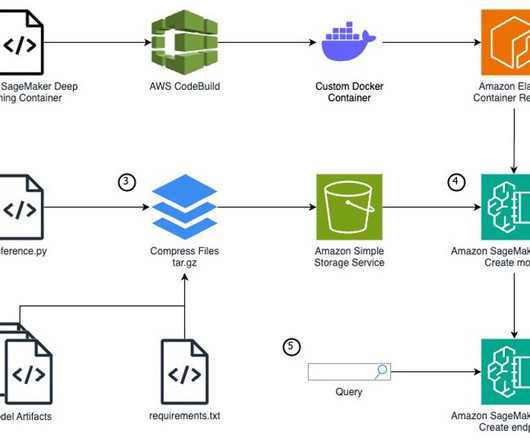
Although SageMaker offers a wide range of built-in algorithms and pre-trained models through Amazon SageMaker JumpStart , there are scenarios where you might need to bring your own custom model or use specific software dependencies not available in SageMaker managed container images. Record the repository URI as an environment variable.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
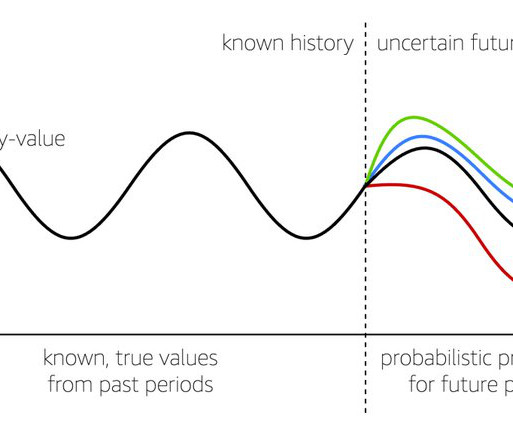
In this post, we show you how Amazon Web Services (AWS) helps in solving forecasting challenges by customizing machine learning (ML) models for forecasting. To learn more about these algorithms visit Algorithms support for time-series forecasting in the Amazon SageMaker documentation. To download a copy of this dataset, visit.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. b64encode(img).decode('utf-8') b64encode(response.content).decode('utf-8')
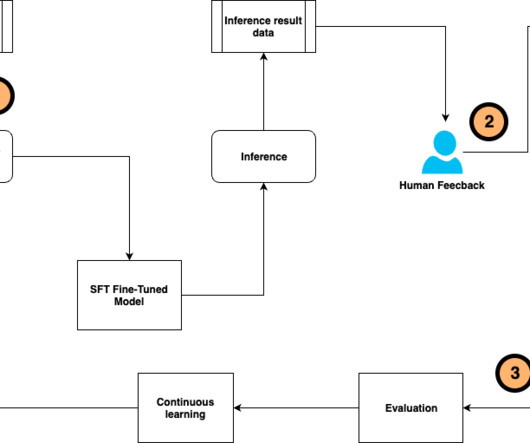
The application exchanges the Amazon Cognito token for an AWS IAM Identity Center token, granting scoped access to Amazon Q Business. This architecture uses AWS services to deliver a scalable, secure, and efficient evaluation solution for Amazon Q Business, combining automated and human-driven evaluations. An AWS account.
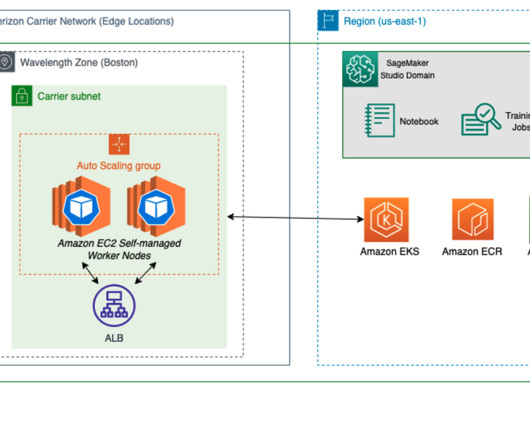
To reduce the barrier to entry of ML at the edge, we wanted to demonstrate an example of deploying a pre-trained model from Amazon SageMaker to AWS Wavelength , all in less than 100 lines of code. In this post, we demonstrate how to deploy a SageMaker model to AWS Wavelength to reduce model inference latency for 5G network-based applications.
To improve factual accuracy of large language model (LLM) responses, AWS announced Amazon Bedrock Automated Reasoning checks (in gated preview) at AWS re:Invent 2024. For example, AWS customers have direct access to automated reasoning-based features such as IAM Access Analyzer , S3 Block Public Access , or VPC Reachability Analyzer.
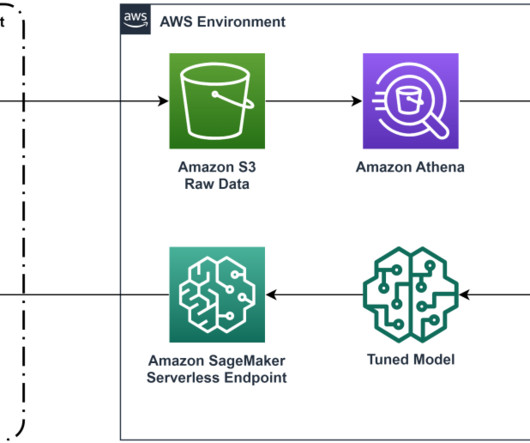
Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. The following diagram presents the overall solution workflow.
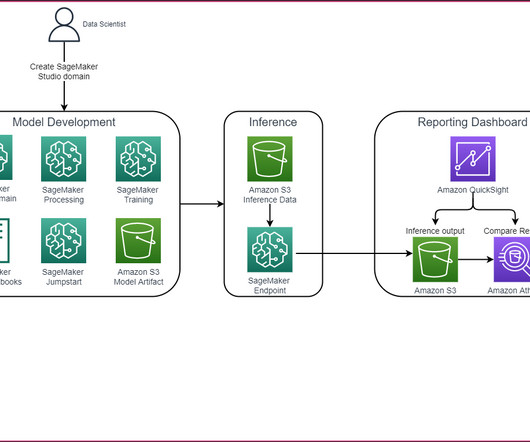
This post demonstrates a strategy for fine-tuning publicly available LLMs for the task of radiology report summarization using AWS services. Our solution uses the FLAN-T5 XL FM, using Amazon SageMaker JumpStart , which is an ML hub offering algorithms, models, and ML solutions. The following screenshot shows our example dashboard.
It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment. This post shows a way to do this using Snowflake as the data source and by downloading the data directly from Snowflake into a SageMaker Training job instance. AWS Region Link us-east-1 (N.
Prerequisites First-time users need an AWS account and AWS Identity and Access Management (IAM) role with SageMaker, Amazon Bedrock, and Amazon Simple Storage Service (Amazon S3) access. Prepare your dataset Complete the following steps to prepare your dataset: Download the following CSV dataset of question-answer pairs.
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. With SageMaker training jobs, you can bring your own algorithm or choose from more than 25 built-in algorithms. From a pricing perspective, you are charged for Downloading, Training, and Uploading phases.
VIIRS is similar to MODIS, and its snow cover and sea ice algorithms are designed to be the newer continuation of MODIS data. VIIRS has higher spatial resolution for certain spectral bands, while MODIS has higher resolution for others. For example, VIIRS has higher resolution for the thermal bands that are useful for detecting forest fires.
Prerequisties The proposed solution can be implemented in a personal AWS environment using the code that we provide. Before running the labs in this post, ensure you have the following: An AWS account. The appropriate AWS Identity and Access Management (IAM) permissions to access services used in the lab.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. With the BlazingText algorithm, you can scale to large datasets.
There are various techniques of preference alignment, including proximal policy optimization (PPO), direct preference optimization (DPO), odds ratio policy optimization (ORPO), group relative policy optimization (GRPO), and other algorithms, that can be used in this process. Set up a SageMaker notebook instance.
Amazon Transcribe is an AWS service that allows customers to convert speech to text in either batch or streaming mode. AWS is responsible for protecting the global infrastructure that runs all of the AWS Cloud. This content includes the security configuration and management tasks for the AWS services that you use.
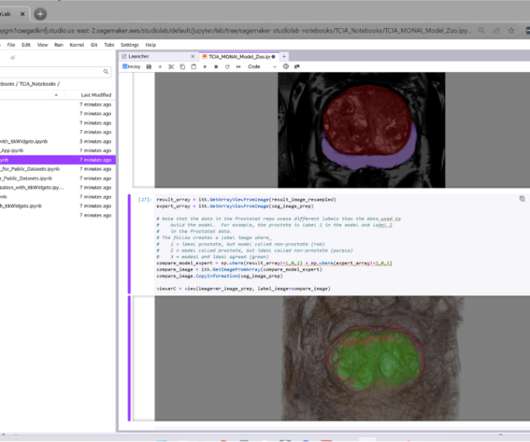
The following example illustrates Studio Lab running a Jupyter notebook that downloads TCIA prostate MRI data, segments it using MONAI, and displays the results using itkWidgets. The first SageMaker notebook shows how to download DICOM images from TCIA and visualize those images using the cinematic volume rendering capabilities of itkWidgets.
The algorithm trained in this blog post is called “ Conservative Q Learning ” (CQL). Measurement data is produced at the edge by a piece of industrial equipment (here simulated by an AWS Lambda function). AWS Glue catalogs the data and makes it queryable using Amazon Athena. Train the algorithm on that data.
Amazon SageMaker JumpStart provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
Amazon Forecast is an ML-based time series forecasting service that includes algorithms that are based on over 20 years of forecasting experience used by Amazon.com , bringing the same technology used at Amazon to developers as a fully managed service, removing the need to manage resources. A deployed template is referred to as a stack.
SageMaker JumpStart is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. models are available in SageMaker JumpStart initially in the US East (Ohio) AWS Region. An AWS Identity and Access Management (IAM) role to access SageMaker.
Therefore, we decided to introduce a deep learning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships. Recommendation model using NCF NCF is an algorithm based on a paper presented at the International World Wide Web Conference in 2017.
Chronos models have been downloaded over 120 million times from Hugging Face and are available for Amazon SageMaker customers through AutoGluon-TimeSeries and Amazon SageMaker JumpStart. Before joining AWS, he worked in the management consulting industry as a data scientist, serving the financial services and telecommunications sectors.
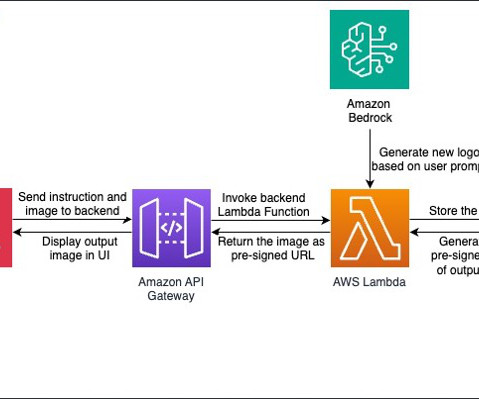
Integrating it with the range of AWS serverless computing, networking, and content delivery services like AWS Lambda , Amazon API Gateway , and AWS Amplify facilitates the creation of an interactive tool to generate dynamic, responsive, and adaptive logos. We recommend using the us-east-1 Obtain access to the Stability SDXL 1.0
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content