This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Google Cloud Platform is a great option for businesses that need high-performance computing, such as data science, AI, machine learning, and financial services. Microsoft Azure Machine Learning Microsoft Azure Machine Learning is a set of tools for creating, managing, and analyzing models.
For instance, a Data Science team analysing terabytes of data can instantly provision additional processing power or storage as required, avoiding bottlenecks and delays. The cloud also offers distributed computing capabilities, enabling faster processing of complex algorithms across multiple nodes.
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Introduction Machine learning can seem overwhelming at first – from choosing the right algorithms to setting up infrastructure. Together with Azure by Microsoft, and Google Cloud Platform from Google, AWS is one of the three mousquetters of Cloud based platforms, and a solution that many businesses use in their day to day.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. NLTK is appreciated for its broader nature, as it’s able to pull the right algorithm for any job. There’s even a more specific version, Spark NLP, which is a devoted library for language tasks.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. This will lead to algorithm development for any machine or deep learning processes.
Snowflake Snowflake is a cloud-based data warehousing platform that offers a highly scalable and efficient architecture designed for performance and ease of use. It features Synapse Studio, a collaborative workspace for data integration, exploration, and analysis, allowing users to manage datapipelines seamlessly.
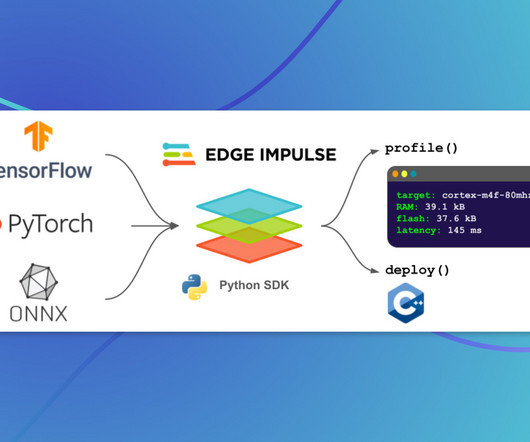
With their groundbreaking web-based Studio platform, engineers have been able to collect data, develop and tune ML models, and deploy them to devices. This has empowered teams to quickly create and optimize models and algorithms that run at peak performance on any edge device. The Edge Impulse SDK is designed to be one of them.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Some of our most popular in-person sessions were: MLOps: Monitoring and Managing Drift: Oliver Zeigermann | Machine Learning Architect ODSC Keynote: Human-Centered AI: Peter Norvig, PhD | Engineering Director, Education Fellow | Google, Stanford Institute for Human-Centered Artificial Intelligence (HAI) The Cost of AI Compute and Why AI Clouds Will (..)
Data Visualization : Techniques and tools to create visual representations of data to communicate insights effectively. Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning.
This unified schema streamlines downstream consumption and analytics because the data follows a standardized schema and new sources can be added with minimal datapipeline changes. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data. The process includes activities such as anomaly detection, event correlation, predictive analytics, automated root cause analysis and natural language processing (NLP).
MLOps helps these organizations to continuously monitor the systems for accuracy and fairness, with automated processes for model retraining and deployment as new data becomes available. You can consider this stage as the most code-intensive stage of the entire ML pipeline. It is designed to leverage hardware acceleration (e.g.,
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. Implementation of metadata-driven datapipelines for governance and reporting. This is where AI truly shines.
Whatever your approach may be, enterprise data integration has taken on strategic importance. Artificial intelligence (AI) algorithms are trained to detect anomalies. Today’s enterprises need real-time or near-real-time performance, depending on the specific application. Timing matters.
Pinecone and Weaviate are popular managed vector database platforms that can efficiently scale to handle billions of documents and return relevant embeddings using an approximate nearest neighbor (ANN) algorithm. Chroma is a popular open-source vector database with an ANN algorithm; however, it currently does not support hybrid search.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition.
Just as a writer needs to know core skills like sentence structure and grammar, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and soon. Data Engineering Data engineering remains integral to many data science roles, with workflow pipelines being a key focus.
This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. Parallelism is suited for workloads that are repetitive, fixed tasks, involving little conditional branching and often large amounts of data.
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
There is a VSCode Extension that enables its integration into traditional development pipelines. How to use the Codex models to work with code - Azure OpenAI Service Codex is the model powering Github Copilot. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Whatever your approach may be, enterprise data integration has taken on strategic importance. Artificial intelligence (AI) algorithms are trained to detect anomalies. Today’s enterprises need real-time or near-real-time performance, depending on the specific application. Timing matters.
Adhering to data protection laws is not as complex if we focus less on the internal structure of the algorithms and more on the practical contexts of use. To keep data secure throughout the models lifecycle, implement these practices: data anonymization, secure model serving and privacy penetration tests.
Python has long been the favorite programming language of data scientists. Historically, Python was only supported via a connector, so making predictions on our energy data using an algorithm created in Python would require moving data out of our Snowflake environment.
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. ML models, in turn, require significant volumes of adequate data to ensure accuracy. What does Snowflake do?
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The Cloud Data Migration Challenge. Datapipeline orchestration.
Whether you rely on cloud-based services like Amazon SageMaker , Google Cloud AI Platform, or Azure Machine Learning or have developed your custom ML infrastructure, Comet integrates with your chosen solution. It goes beyond compatibility with open-source solutions and extends its support to managed services and in-house ML platforms.
The Complexity of ML Projects ML models usually have many iterations, each one with its unique data sets, preprocessing steps, hyperparameters, and algorithm adjustments. Regular backups can be done using the automated metrics that periodically copy the data and model files to remote storage such as cloud storage (eg.
Data Science Dojo is offering Memphis broker for FREE on Azure Marketplace preconfigured with Memphis, a platform that provides a P2P architecture, scalability, storage tiering, fault-tolerance, and security to provide real-time processing for modern applications suitable for large volumes of data. Try Memphis Now !
With language models and NLP , you’d likely need your data component to also cater for unstructured text and speech data and extract real-time insights and summaries from them. The most important requirement you need to incorporate into your platform for this vertical is the regulation of data and algorithms.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. The default value is 360 seconds.
Let’s break down why this is so powerful for us marketers: Data Preservation : By keeping a copy of your raw customer data, you preserve the original context and granularity. Both persistent staging and data lakes involve storing large amounts of raw data. Your customer data game will never be the same.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content