This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform bigdataanalytics and gain valuable insights from their data.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Additionally, students should grasp the significance of BigData in various sectors, including healthcare, finance, retail, and social media. Understanding the implications of BigDataanalytics on business strategies and decision-making processes is also vital.
The analysis of tons of data for your SaaS business can be extremely time-consuming, and it could even be impossible if done manually. Rather, AWS offers a variety of data movement, data storage, data lakes, bigdataanalytics, log analytics, streaming analytics, and machine learning (ML) services to suit any need.
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios.
Search engines use data mining tools to find links from other sites. They use a sophisticated data-driven algorithm to assess the quality of these sites based on the volume and quantity of inbound links. This algorithm is known as Google PageRank. These Hadoop based tools archive links and keep track of them.
The importance of BigData lies in its potential to provide insights that can drive business decisions, enhance customer experiences, and optimise operations. Organisations can harness BigDataAnalytics to identify trends, predict outcomes, and make informed decisions that were previously unattainable with smaller datasets.
Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it. This can cause limitations if you need to consider more metrics than this.
Next-generation sequencing (NGS) platforms have dramatically increased the speed and reduced the cost of DNA sequencing, leading to the generation of vast amounts of genomic data. Developing benchmark datasets and standardized evaluation metrics is necessary to assess algorithm performance and facilitate comparisons between other methods.
Key Takeaways BigData originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. What is BigData?
Key Takeaways BigData originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. What is BigData?
The programming language can handle BigData and perform effective data analysis and statistical modelling. Hence, you can use R for classification, clustering, statistical tests and linear and non-linear modelling. How is R Used in Data Science?
Predictive Analytics Projects: Predictive analytics involves using historical data to predict future events or outcomes. Techniques like regression analysis, time series forecasting, and machine learning algorithms are used to predict customer behavior, sales trends, equipment failure, and more.
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
We use data-specific preprocessing and ML algorithms suited to each modality to filter out noise and inconsistencies in unstructured data. NLP cleans and refines content for text data, while audio data benefits from signal processing to remove background noise. Such algorithms are key to enhancing data.
Its speed and performance make it a favored language for bigdataanalytics, where efficiency and scalability are paramount. This environment allows users to write, execute, and debug code in a seamless manner, facilitating rapid prototyping and exploration of algorithms. Q: Is C++ relevant in Data Science?
They store structured data in a format that facilitates easy access and analysis. Data Lakes: These store raw, unprocessed data in its original format. They are useful for bigdataanalytics where flexibility is needed.
Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigDataAnalytics market, valued at $307.51 Turning raw data into meaningful insights helps businesses anticipate trends, understand consumer behaviour, and remain competitive in a rapidly changing world.
Consider a scenario where a doctor is presented with a patient exhibiting a cluster of unusual symptoms. Rules Engine This is the brain of the CDSS, employing complex algorithms to analyze patient data against the knowledge base. BigDataAnalytics The ever-growing volume of healthcare data presents valuable insights.
The type of data processing enables division of data and processing tasks among the multiple machines or clusters. Distributed processing is commonly in use for bigdataanalytics, distributed databases and distributed computing frameworks like Hadoop and Spark.
Data scientists train multiple ML algorithms to examine millions of consumer data records, identify anomalies, and evaluate if a person is eligible for credit. Best Egg trains multiple credit models using classification and regression algorithms. Valerio Perrone is an Applied Science Manager at AWS.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigDataanalytics provides a competitive advantage and drives innovation across various industries. Use Cases : Yahoo!
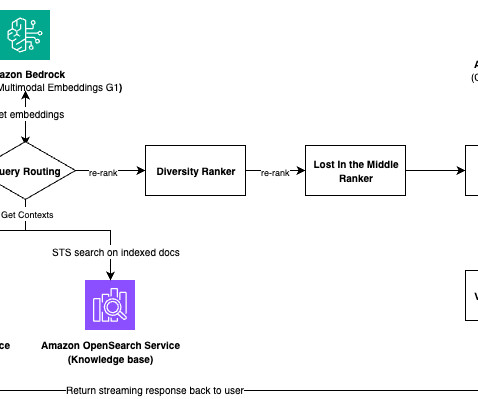
We’re planning to migrate to Amazon Bedrock Knowledge Bases to eliminate cluster management and add extensibility to our pipeline. Because these scores merely use word-matching algorithms and ignore the semantic meaning of the text, they aren’t aligned with the SME scores. generated_answer – This is the answer generated by the bot.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content