This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
Learn how to apply state-of-the-art clusteringalgorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. This is called clustering. In Data Science, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset.
Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit. They are both ML Algorithms, and we’ll explore them more in detail in a bit.
Reverse Engineering The SciKit ImplementationPhoto by Mel Poole on Unsplash Understanding how an algorithm works is interesting as it provides some insights into why an implementation may not be as one would expect. This is not always easy to do as some algorithms have stochastic components. Let’s dive deeper into the algorithm.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
In this blog post, we explore Spotify's journey from using the Fisher-Yates shuffle to a more sophisticated song shuffling algorithm that prevents clustering of tracks by the same artist. We then connect this challenge to Fibonacci hashing, and propose a novel, evenly distributed artist shuffling method.
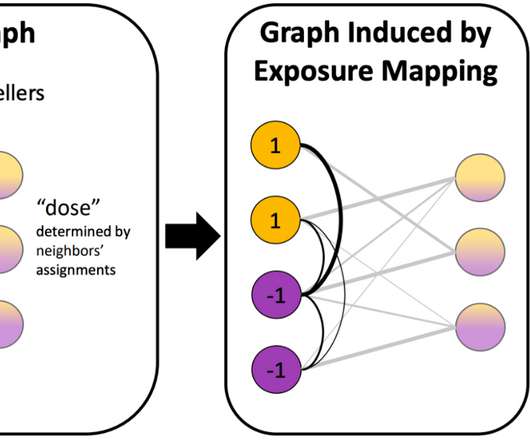
Posted by Vincent Cohen-Addad and Alessandro Epasto, Research Scientists, Google Research, Graph Mining team Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. When clustering is applied to personal data (e.g.,
It excels in soft clustering, handling overlapping clusters, and modelling diverse cluster shapes. Its ability to model complex, multimodal data distributions makes it invaluable for clustering , density estimation, and pattern recognition tasks. EM algorithm iteratively optimizes GMM parameters for best data fit.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. To the rescue (!): IoT, Web 3.0,
In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise. The purpose is to improve accuracy by either training a global model that contains the cluster configuration or have local models specific to each cluster.
Thats the motto of Unsupervised Learning a fascinating branch of machine learning where algorithms learn patterns from unlabeled data. Unsupervised learning helps you automatically discover patterns or groupings or clustering in the data, like identifying clusters of customers with similar behaviors or preferences. No worries!
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
Using n_init and K-Means++ image by Flo K-Means is a widely-used clusteringalgorithm in Machine Learning, boasting numerous benefits but also presenting significant challenges. K-Means is a clusteringalgorithm that partitions data into K clusters. Each cluster is represented by a color.
In this blog post, we’ll break down the end-to-end ML process in business, guiding you through each stage with examples and insights that make it easy to grasp. Formatting the data in a way that ML algorithms can understand. Unsupervised learning algorithms like clustering solve problems without labeled data.
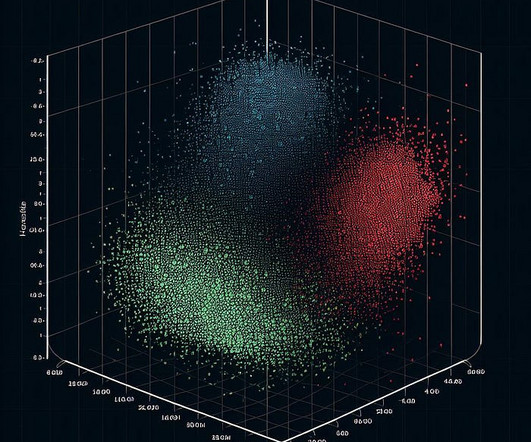
However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions. The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The AML feature store standardizes variable definitions using scientifically validated algorithms.
In this blog, we’ll show you how to boost your MLOps efficiency with 6 essential tools and platforms. It provides a large cluster of clusters on a single machine. AWS SageMaker is useful for creating basic models, including regression, classification, and clustering. Are you struggling with managing MLOps tools?
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the Decision Tree. This often occurs in Cluster Analysis, where we identify clusters without prior information. Before we start, please consider following me on Medium or LinkedIn.
Summary: Hierarchical clustering categorises data by similarity into hierarchical structures, aiding in pattern recognition and anomaly detection across various fields. Introduction This blog delves into hierarchical clustering, a pivotal Machine Learning technique. What is Hierarchical Clustering?
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification. What is Classification?
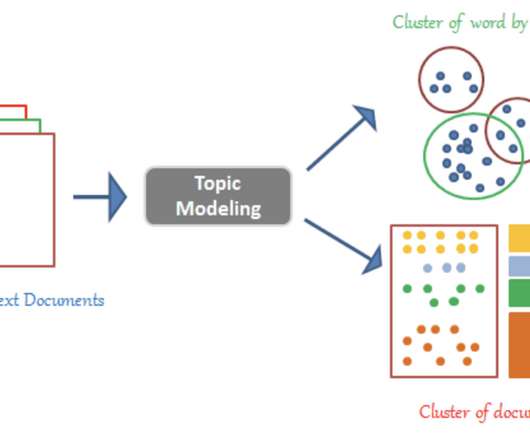
Topic Modeling In this blog, we walk you through the popular Open Source Latent Dirichlet Allocation (LDA) Topic Modeling from conventional algorithms and Watson NLP Topic Modeling. Latent Dirichlet Allocation (LDA) Topic Modeling LDA is a well-known unsupervised clustering method for text analysis.
In this blog post, we’ll explore five project ideas that can help you build expertise in computer vision, natural language processing (NLP), sales forecasting, cancer detection, and predictive maintenance using Python. One project idea in this area could be to build a facial recognition system using Python and OpenCV.
This blog delves into the technical details of how vec t o r d a ta b a s e s empower patient sim i l a r i ty searches and pave the path for improved diagnosis. Exploring Disease Mechanisms : Vector databases facilitate the identification of patient clusters that share similar disease progression patterns.
This blog lists down-trending data science, analytics, and engineering GitHub repositories that can help you with learning data science to build your own portfolio. What is GitHub? It provides a range of algorithms for classification, regression, clustering, and more.
You can also read this article on Kablamo Engineering Blog. Since we lack knowledge of the exact field boundaries, we can use the unsupervised machine learning algorithm, K-means clustering, to partition unlabelled data points into K clusters predicated on their similarity.
In this blog, we will focus on these embeddings in LLM and explore how they have evolved over time within the world of NLP, each transformation being a result of technological advancement and progress. Using this information Word2Vec creates a unique vector representation of each word, creating improved clusters for similar words.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
During the iterative research and development phase, data scientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise.
Selecting the right algorithm There are several data mining algorithms available, each with its strengths and weaknesses. When selecting an algorithm, consider factors such as the size and type of your dataset, the problem you’re trying to solve, and the computational resources available.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
In this blog, we will focus on one such developed aspect of AI called adaptive AI. Unlike traditional AI, which follows set rules and algorithms and tends to fall apart when faced with obstacles, adaptive AI systems can modify their behavior based on their experiences. What is Adaptive AI?
By using sophisticated ML algorithms, the platform efficiently scans billions of videos each day. About the Authors Wangpeng An, Principal Algorithm Engineer at TikTok, specializes in multimodal LLMs for video understanding, advertising, and recommendations. To learn more about Inf2 instances, refer to Amazon EC2 Inf2 Architecture.
Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. The following screenshot shows the top rows of the dataset.
In this blog post, we’ll explain how Multichannel transcription and Speaker Diarization work, what their outputs look like, and how you can implement them using AssemblyAI. Both traditional clustering methods like K-means, or more advanced algorithms employing neural networks are common.
Posted by Haim Kaplan and Yishay Mansour, Research Scientists, Google Research Differential privacy (DP) machine learning algorithms protect user data by limiting the effect of each data point on an aggregated output with a mathematical guarantee. Two adjacent datasets that differ in a single outlier. are both close to a third point ?
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service. For data handling, 24 data nodes (r6gd.2xlarge.search
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. It is a cloud-based platform, so it can be accessed from anywhere.
In the next sections of this blog, we will delve deeper into the technical aspects of Distributed Systems in Big Data Engineering, showcasing code snippets to illustrate how these systems work in practice. Different algorithms and techniques are employed to achieve eventual consistency.
This blog aims to explain associative classification in data mining, its applications, and its role in various industries. For instance, a classification algorithm could predict whether a transaction is fraudulent or not based on various features. As the data mining tools market grows, valued at US$ 1014.05
If you haven’t set up a SageMaker Studio domain, see this Amazon SageMaker blog post for instructions on setting up SageMaker Studio for individual users. To search against the database, you can use a vector search, which is performed using the k-nearest neighbors (k-NN) algorithm. The model will then be available for use.
The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer. The implementation included a provisioned three-node sharded OpenSearch Service cluster.
In this blog, we will focus on these embeddings in LLM and explore how they have evolved over time within the world of NLP, each transformation being a result of technological advancement and progress. Using this information Word2Vec creates a unique vector representation of each word, creating improved clusters for similar words.
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Integrating tensor parallelism to enable training on massive clusters This release of SMP also expands PyTorch FSDP’s capabilities to include tensor parallelism techniques.
Predictive AI blends statistical analysis with machine learning algorithms to find data patterns and forecast future outcomes. These adversarial AI algorithms encourage the model to generate increasingly high-quality outputs. Similarly, random forest algorithms combine the output of multiple decision trees to reach a single result.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content