This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dear readers, In this blog, we will be discussing how to perform image classification using four popular machine learning algorithms namely, Random Forest Classifier, KNN, DecisionTree Classifier, and Naive Bayes classifier. This article was published as a part of the Data Science Blogathon.
It involves developing algorithms and models to analyze, understand, and generate human language, enabling computers to perform sentiment analysis, language translation, text summarization, and tasks. The post Top 10 blogs on NLP in Analytics Vidhya 2022 appeared first on Analytics Vidhya.
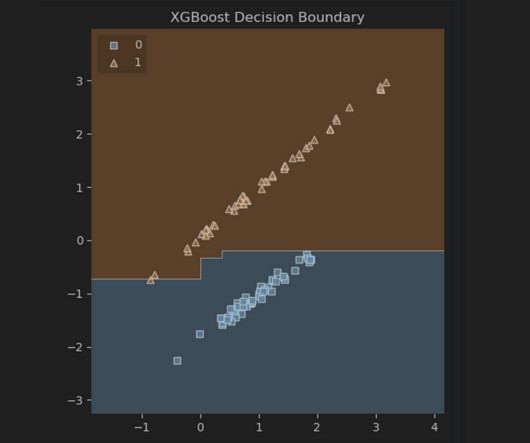
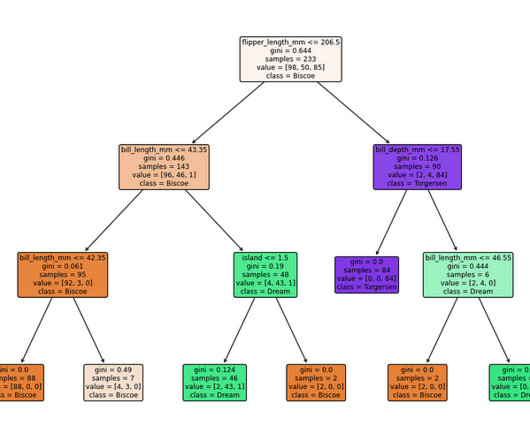
Visual geneated by sample code provided in this blog tutorial. This is the essence of a decisiontree—one of today’s most intuitive and powerful machine learning algorithms. A decisiontree is a step-by-step guide that asks questions about the data and splits it into increasingly homogeneous groups.
By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machine learning and pave the way for innovation and success. In this blog, we focus on machine learning practices—the essential steps that unlock the potential of this transformative technology.
Photo by Nicole Wolf on Unsplash Today we will talk about DecisionTrees, a powerful tool in machine learning and data science. You might be thinking of how a tree will help you make a decision. Not your backyard tree but an algorithm that resembles such trees for guiding choices in an unordered manner.
Fall in Love with DecisionTrees with dtreeviz’s Visualization This member-only story is on us. DecisionTrees, also known as CART (Classification and Regression Trees), are undoubtedly one of the most intuitive algorithms in the machine learning space, thanks to their simplicity. Why am I saying this?
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. These intelligent predictions are powered by various Machine Learning algorithms.
In data science and machine learning, decisiontrees are powerful models for both classification and regression tasks. This blog will explore what these metrics are, and how they are used with the help of an example. This blog will explore what these metrics are, and how they are used with the help of an example.
In this post, I will show how to develop, deploy, and use a decisiontree model in a Db2 database. Using examples from the dataset, we’ll build a classification model with decisiontreealgorithm. I extract the hour part of these values to create, hopefully, better features for the learning algorithm.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. To the rescue (!): IoT, Web 3.0,
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
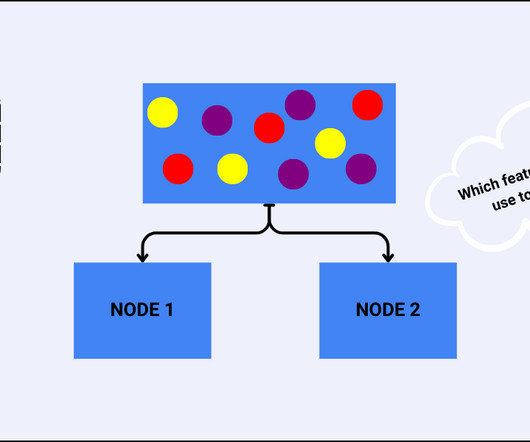
One of the most popular algorithms in Machine Learning are the DecisionTrees that are useful in regression and classification tasks. Decisiontrees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning. How DecisionTreeAlgorithm works?
In this blog, we will explore the details of both approaches and navigate through their differences. A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. What is Generative AI?
In the world of Machine Learning and Data Analysis , decisiontrees have emerged as powerful tools for making complex decisions and predictions. These tree-like structures break down a problem into smaller, manageable parts, enabling us to make informed choices based on data. What is a DecisionTree?
Imagine a world where your business could make smarter decisions, predict customer behavior with astonishing accuracy, and automate tasks that used to take hours of manual labor. Formatting the data in a way that ML algorithms can understand. Unsupervised learning algorithms like clustering solve problems without labeled data.
These features can be used to improve the performance of Machine Learning Algorithms. The figure below shows a quick representation of feature scaling techniques that we will discuss in this blog. Here, we can observe a drastic improvement in our model accuracy when we apply the same algorithm to standardized features.
Introduction Alpha beta pruning in Artificial Intelligence is a technique that speeds up decision-making by systematically ignoring unproductive branches during a search. This blog aims to explain how alpha-beta pruning works, highlight its importance in everyday applications, and show why it remains vital in advancing AI.
This blog aims to explain associative classification in data mining, its applications, and its role in various industries. It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive.
Instead, it leverages a combination of different algorithms — or even the same algorithm applied to varied data or configurations — to make smarter decisions. But here’s the twist: ensemble learning doesn’t just combine random models willy-nilly. Join thousands of data leaders on the AI newsletter.
Explained from scratch, step by step Some time ago, I found myself having to explain the tree-based algorithms to a person who was into mathematics… but with zero knowledge of data science. Last Updated on March 30, 2023 by Editorial Team Author(s): Andrea Ianni Originally published on Towards AI.
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the DecisionTree. Image by Author There are other types of learning in Machine Learning, such as semi-supervised and… Read the full blog for free on Medium.
So, instead of relying on one model to do all the work, you decide to use Gradient Boosting, an algorithm that cleverly combines the predictions of multiple models to get closer to the truth. To minimize the residual errors, or the difference between predicted and actual values, one step… Read the full blog for free on Medium.
Create by author Following up on my previous topic on 4 algorithms for precision agriculture, I want to narrow it down and focus on how to utilize random forest algorithm for precision agriculture, this topic is timely as random forest seems to be the most ideal algorithm for precision agriculture.
The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Below, we highlight a panoply of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
Selecting the right algorithm There are several data mining algorithms available, each with its strengths and weaknesses. When selecting an algorithm, consider factors such as the size and type of your dataset, the problem you’re trying to solve, and the computational resources available.
In this blog, we will explore the basics of categorical data. Model Compatibility Most machine learning algorithms work with numerical data, making it essential to transform categorical variables into numerical values. Learn about 101 ML algorithms for data science with cheat sheets 5. What is Categorical Data?
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Each algorithm is explained with its applications, strengths, and weaknesses, providing valuable insights for practitioners and enthusiasts in the field.
Summary: This comprehensive guide covers the basics of classification algorithms, key techniques like Logistic Regression and SVM, and advanced topics such as handling imbalanced datasets. Classification algorithms are crucial in various industries, from spam detection in emails to medical diagnosis and customer segmentation.
However, with a wide range of algorithms available, it can be challenging to decide which one to use for a particular dataset. ⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ?
Predictive AI blends statistical analysis with machine learning algorithms to find data patterns and forecast future outcomes. These adversarial AI algorithms encourage the model to generate increasingly high-quality outputs. Decisiontrees implement a divide-and-conquer splitting strategy for optimal classification.
In this blog post, we will thoroughly understand what Gradient Boosting is and understand the math behind this beautiful concept. To refresh your memory, we recommend going through the first blog post of this series once again. Throughout this series, we have investigated algorithms by applying them to decisiontrees.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
We chose to compete in this challenge primarily to gain experience in the implementation of machine learning algorithms for data science. Summary of approach: Our solution for Phase 1 is a gradient boosted decisiontree approach with a lot of feature engineering. What motivated you to compete in this challenge?
This blog post features a predictive maintenance use case within a connected car infrastructure, but the discussed components and architecture are helpful in any industry. A very common pattern for building machine learning infrastructure is to ingest data via Kafka into a data lake. Contact: kai.waehner@confluent.io / Twitter / LinkedIn.
If you spend even a few minutes on KNIME’s website or browsing through their whitepapers and blog posts, you’ll notice a common theme: a strong emphasis on data science and predictive modeling. In this blog post, we will visit a few types of predictive models that are available in either the base KNIME installation or via a free extension.
Boosting ensemble algorithm in machine learning This member-only story is on us. Weak learners or base models: These are the different algorithms used in a collection of machine learning base models in the ensemble, these models can be logistic regression, SVM, decisiontrees, linear regression, random forest, etc.
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification. What is Classification?
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
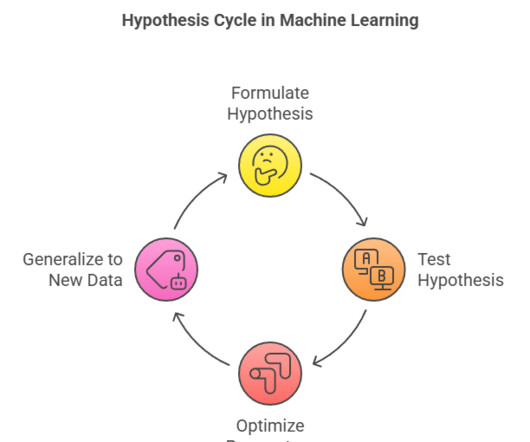
It guides algorithms in testing assumptions, optimizing parameters, and minimizing errors. hypothesis form the foundation for diverse applications, from predictive analytics and recommendation engines to autonomous systems, enabling accurate, data-driven decision-making and improved model performance.
DecisionTrees ? is actually just a bunch of DecisionTrees ? We need to talk about trees before we can get into forests. You just evaluated a decisiontree in your head: That’s a simple decisiontree with one decision node that tests x < 2 x < 2 x < 2. Let’s dive in.
Among the different techniques used in Machine Learning, it also incorporates creating algorithms and models that can learn from the data, improvise and make decisions. In this blog, we will focus on bagging vs boosting in machine learning. Random Forest is a popular algorithm that uses bagging.
This blog aims to clarify the concept of inductive bias and its impact on model generalisation, helping practitioners make better decisions for their Machine Learning solutions. Types of inductive bias include prior knowledge, algorithmic bias, and data bias. Thus, effective model design is more important than ever.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content