This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. To the rescue (!): IoT, Web 3.0,
These features can be used to improve the performance of Machine Learning Algorithms. The figure below shows a quick representation of feature scaling techniques that we will discuss in this blog. Here, we can observe a drastic improvement in our model accuracy when we apply the same algorithm to standardized features.
In this blog, we will explore the details of both approaches and navigate through their differences. A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. What is Generative AI?
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit. K-NearestNeighbors (KNN) is a supervised ML algorithm for classification and regression.
This blog delves into the technical details of how vec t o r d a ta b a s e s empower patient sim i l a r i ty searches and pave the path for improved diagnosis. The search involves a combination of various algorithms, like approximate nearestneighbor optimization, which uses hashing, quantization, and graph-based detection.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
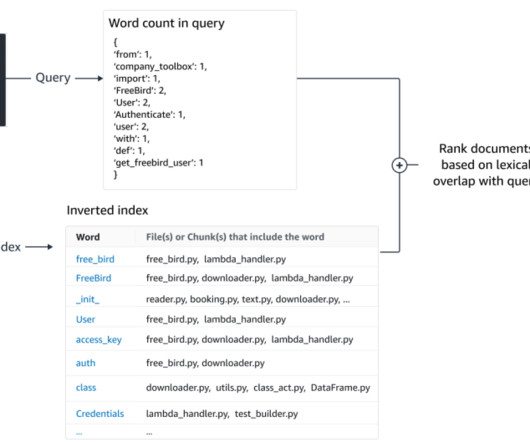
In this blog post, well dive into the various scenarios for how Cohere Rerank 3.5 improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. In this approach, the query and document encodings are generated with the same embedding algorithm.
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Unlocking the Power of KNN Algorithm in Machine Learning Machine learning algorithms are significantly impacting diverse fields.
However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions. This is the k-nearestneighbor (k-NN) algorithm.
If you haven’t set up a SageMaker Studio domain, see this Amazon SageMaker blog post for instructions on setting up SageMaker Studio for individual users. To search against the database, you can use a vector search, which is performed using the k-nearestneighbors (k-NN) algorithm.
The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer. The CRAG dataset also provides top five search result pages for each query.
What Is the KNN Classification Algorithm? The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel. It is useful for recognizing patterns […].
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service.
Summary: This comprehensive guide covers the basics of classification algorithms, key techniques like Logistic Regression and SVM, and advanced topics such as handling imbalanced datasets. Classification algorithms are crucial in various industries, from spam detection in emails to medical diagnosis and customer segmentation.
KNearest Neighbour is an algorithm that stores all the available observations and classifies the new data based on a similarity measure. The post Using KNearest Neighbours algorithm in scenario tuning appeared first on SAS Blogs.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
However, with a wide range of algorithms available, it can be challenging to decide which one to use for a particular dataset. ⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ?
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module.
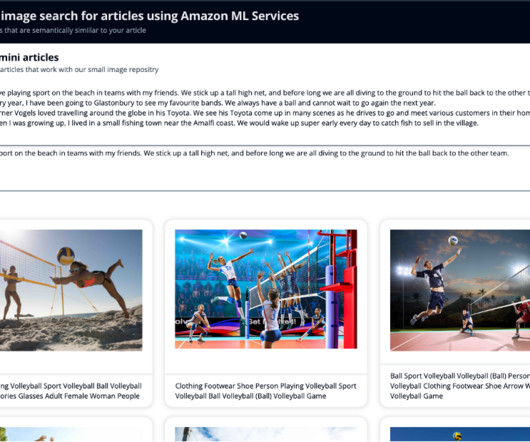
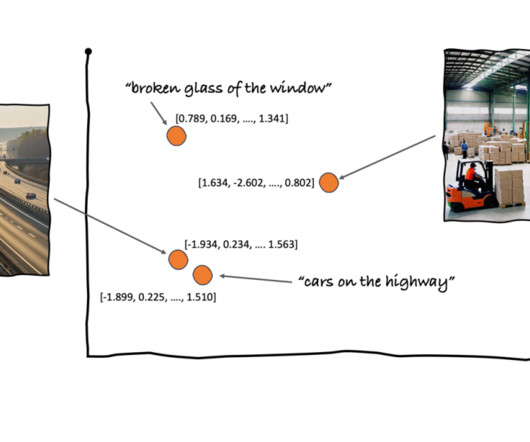
You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results.
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
Random Projection The first step in the algorithm is to sample random vectors in the same -dimensional space as input vector. Setting Up Baseline with the k-NN Algorithm With our word embeddings ready, let’s implement a -NearestNeighbors (k-NN) search. -NN
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
In this short blog, were diving deep into vector databases what they are, how they work, and, most importantly, how to use them like a pro. But heres the catch scanning millions of vectors one by one (a brute-force k-NearestNeighbors or KNN search) is painfully slow. Traditional databases? They tap out. 💡 Why?
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. By analyzing how users have interacted with items in the past, we can use algorithms to approximate the utility function and make personalized recommendations that users will love.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). Conversely, a smaller K leads to faster search times and lower costs, but may lower result quality.
This retrieval can happen using different algorithms. Formally, often k-nearestneighbors (KNN) or approximate nearestneighbor (ANN) search is often used to find other snippets with similar semantics. Semantic retrieval BM25 focuses on lexical matching.
Hey guys, we will see some of the Best and Unique Machine Learning Projects with Source Codes in today’s blog. Source code projects provide valuable hands-on experience and allow you to understand the intricacies of machine learning algorithms, data preprocessing, model training, and evaluation. This is going to be a very short blog.
Hey guys, we will see some of the Best and Unique Machine Learning Projects for final year engineering students in today’s blog. This is going to be a very interesting blog, so without any further due, let’s do it… 1. Self-Organizing Maps In this blog, we will see how we can implement self-organizing maps in Python.
Introducing GraphStorm Graph algorithms and graph ML are emerging as state-of-the-art solutions for many important business problems like predicting transaction risks, anticipating customer preferences, detecting intrusions, optimizing supply chains, social network analysis, and traffic prediction. on the test set of the constructed graph.
The following blog will provide you a thorough evaluation on how Anomaly Detection Machine Learning works, emphasising on its types and techniques. The specific techniques and algorithms used can vary based on the nature of the data and the problem at hand. This algorithm is efficient and effective for high-dimensional datasets.
In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick. Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many data scientists.
We developed the STUDY algorithm in partnership with Learning Ally , an educational nonprofit, aimed at promoting reading in dyslexic students, that provides audiobooks to students through a school-wide subscription program. Experiments We used the Learning Ally dataset to train the STUDY model along with multiple baselines for comparison.
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. The user input is converted into embeddings using the Amazon Titan Text Embeddings model accessed using Amazon Bedrock. An OpenSearch Service vector search is performed using these embeddings.
Introduction In the world of machine learning, where algorithms learn from data to make predictions, it’s important to get the best out of our models. Steps to Perform Hyperparameter Tuning Hyperparameter Tuning process (Image by author) Select Hyperparameters to Tune: Different algorithms have different hyperparameters.
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. Key steps involve problem definition, data preparation, and algorithm selection. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. Doctor-Patient Appointment System in Python using Flask Hey guys, in this blog we will see a Doctor-Patient Appointment System for Hospitals built in Python using Flask. I myself made this as my final year major project.
This blog aims to clarify the concept of inductive bias and its impact on model generalisation, helping practitioners make better decisions for their Machine Learning solutions. Types of inductive bias include prior knowledge, algorithmic bias, and data bias. Thus, effective model design is more important than ever.
find_similar_items performs semantic search using the k-nearestneighbors (kNN) algorithm on the input image prompt. See this announcement blog post for information about the Amazon Titan Image Generator and Amazon Titan Multimodal Embeddings model. The following code snippet shows the implementation of this step.
Spotify’s Discover Weekly ( Figure 3 ) is an algorithm-generated playlist released every Monday to offer its listeners custom, curated music recommendations. to train their algorithm. Alternating Least Squares The matrices and are optimized using alternate least squares algorithm as follows: Step 1: Initialize and randomly.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters. The results show that most of them were indeed labeled incorrectly.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content