This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
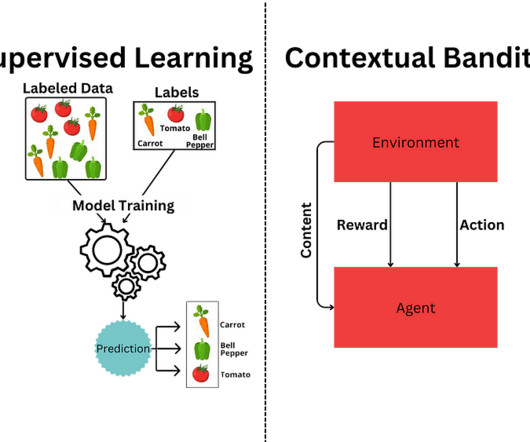
SupervisedLearning: Train once, deploy static model; Contextual Bandits: Deploy once, allow the agent to adapt actions based on content and its corresponding reward. Supervisedlearning is a staple in machine learning for well-defined problems, but it struggles to adapt to dynamic environments: enter contextual bandits.
In this blog, we will explore the details of both approaches and navigate through their differences. A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. What is Generative AI?
Summary: Machine Learningalgorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learningalgorithms.
Thats the motto of Unsupervised Learning a fascinating branch of machine learning where algorithmslearn patterns from unlabeled data. Unsupervised learning helps you automatically discover patterns or groupings or clustering in the data, like identifying clusters of customers with similar behaviors or preferences.
In this blog, we will focus on these embeddings in LLM and explore how they have evolved over time within the world of NLP, each transformation being a result of technological advancement and progress. The two main approaches of interest for embeddings include unsupervised and supervisedlearning.
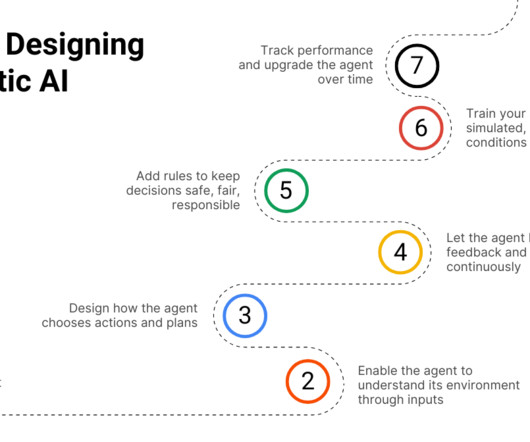
In this blog, we will break down what agentic AI is, how it works, where its being used, and what it means for the future. By basing decisions on data and algorithms rather than gut feelings, businesses can reduce the influence of bias in critical systems. You will need to implement algorithms that let it choose actions on its own.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. This week, we continue that metaphorical (learning) journey with a fun fact. To the rescue (!): IoT, Web 3.0,
Accordingly, Machine Learning allows computers to learn and act like humans by providing data. Apparently, ML algorithms ensure to train of the data enabling the new data input to make compelling predictions and deliver accurate results. Therefore, SupervisedLearning vs Unsupervised Learning is part of Machine Learning.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
That world is not science fiction—it’s the reality of machine learning (ML). In this blog post, we’ll break down the end-to-end ML process in business, guiding you through each stage with examples and insights that make it easy to grasp. Formatting the data in a way that ML algorithms can understand.
This is a guest blog post co-written with Jordan Knight, Sara Reynolds, George Lee from Travelers. Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset.
In this blog, we will focus on these embeddings in LLM and explore how they have evolved over time within the world of NLP, each transformation being a result of technological advancement and progress. The two main approaches of interest for embeddings include unsupervised and supervisedlearning.
Let’s discuss two popular ML algorithms, KNNs and K-Means. They are both ML Algorithms, and we’ll explore them more in detail in a bit. K-Nearest Neighbors (KNN) is a supervised ML algorithm for classification and regression. This member-only story is on us. Upgrade to access all of Medium.
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the Decision Tree. Image by Author There are other types of learning in Machine Learning, such as semi-supervised and… Read the full blog for free on Medium.
These figures underscore the pressing need for awareness and solutions regarding the challenges faced by Machine Learning professionals. Key Takeaways Data quality is crucial; poor data leads to unreliable Machine Learning models. Algorithmic bias can result in unfair outcomes, necessitating careful management.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. What is machine learning? Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Introduction Machine Learning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
In this blog, we will focus on one such developed aspect of AI called adaptive AI. It is a form of AI that learns, adapts, and improves as it encounters changes, both in data and the environment. Some key characteristics that make AI adaptive are: Ability to Learn Continuously The AI system can process and analyze new information.
Summary: This blog highlights ten crucial Machine Learningalgorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Each algorithm is explained with its applications, strengths, and weaknesses, providing valuable insights for practitioners and enthusiasts in the field.
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions. This is the k-nearest neighbor (k-NN) algorithm. The following figure illustrates how this works.
First, there is a lack of scalability with conventional supervisedlearning approaches. In contrast, self-supervisedlearning can leverage audio-only data, which is available in much larger quantities across languages. This requires the learningalgorithm to be flexible, efficient, and generalizable.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. The BlazingText algorithm expects a single preprocessed text file with space-separated tokens. Set the learning mode hyperparameter to supervised. For instructions, see Create your first S3 bucket.
Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models. Sometimes the unsupervised algorithm will happen to produce the output you want, but other times it won’t.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learningalgorithms. You might be using machine learningalgorithms from everything you see on OTT or everything you shop online.
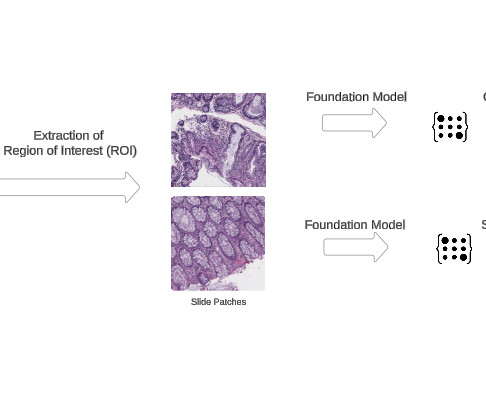
These models are trained using self-supervisedlearningalgorithms on expansive datasets, enabling them to capture a comprehensive repertoire of visual representations and patterns inherent within pathology images.
Summary: This comprehensive guide covers the basics of classification algorithms, key techniques like Logistic Regression and SVM, and advanced topics such as handling imbalanced datasets. It also includes practical implementation steps and discusses the future of classification in Machine Learning. What is Classification?
These complex algorithms are the backbone upon which our modern technological advancements rest and which are doing wonders for natural language communication. PaLM 2 stands for “ Progressive and Adaptive Language Model 2 ” and Llama 2 is short for “ Language Learning and Mastery Algorithm 2 ”.
This blog aims to explain associative classification in data mining, its applications, and its role in various industries. Classification: How it Differs from Association Rules Classification is a supervisedlearning technique that aims to predict a target or class label based on input features.
One of the most popular algorithms in Machine Learning are the Decision Trees that are useful in regression and classification tasks. Decision trees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning. What is Decision Tree in Machine Learning?
By Jeremy Arancio This blog details the deployment of an in-house Vision Language Model (VLM), specifically Qwen-2.5-VL, A Novel and Practical MetaBooster for SupervisedLearning By Shenggang Li This article introduced Meta-Booster, an ensemble framework for supervisedlearning tasks.
Amazon Forecast is a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts. Calculating courier requirements The first step is to estimate hourly demand for each warehouse, as explained in the Algorithm selection section.
Amazon SageMaker JumpStart provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
Table 2 and Figure 2 show performance results of PORPOISE and HEEC, which show that HEEC is the only algorithm that outperforms the results of the best-performing single modality by combining multiple modalities. This location can be visually highlighted on the histology slide to be presented to expert pathologists for verification.
This powerful self-supervisedlearning method is poised to transform the way businesses use computer vision in various applications, from e-commerce to manufacturing and beyond. In this blog post, we’ll explore what DINOv2 is, how it works, and the exciting possibilities it opens up for businesses.
A demonstration of the RvS policy we learn with just supervisedlearning and a depth-two MLP. It uses no TD learning, advantage reweighting, or Transformers! Offline reinforcement learning (RL) is conventionally approached using value-based methods based on temporal difference (TD) learning.
The answer lies in the various types of Machine Learning, each with its unique approach and application. In this blog, we will explore the four primary types of Machine Learning: SupervisedLearning, UnSupervised Learning, semi-SupervisedLearning, and Reinforcement Learning.
Welcome to ALT Highlights, a series of blog posts spotlighting various happenings at the recent conference ALT 2021 , including plenary talks, tutorials, trends in learning theory, and more! To reach a broad audience, the series will be disseminated as guest posts on different blogs in machine learning and theoretical computer science.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. There are two types of Machine Learning techniques, including supervised and unsupervised learning.
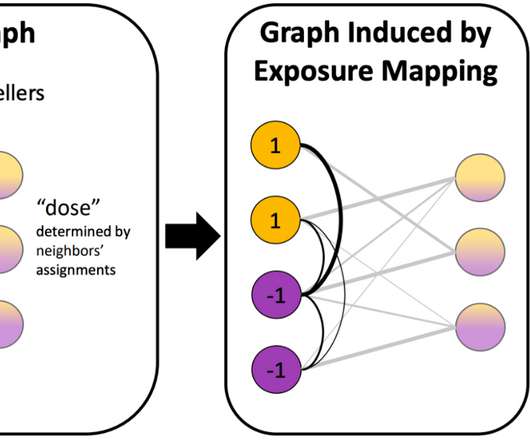
The closest analogue in academia is interactive imitation learning (IIL) , a paradigm in which a robot intermittently cedes control to a human supervisor and learns from these interventions over time. Using this formalism, we can now instantiate and compare IFL algorithms (i.e., allocation policies) in a principled way.
To keep up with the pace of consumer expectations, companies are relying more heavily on machine learningalgorithms to make things easier. This blog post will clarify some of the ambiguity. How do artificial intelligence, machine learning, deep learning and neural networks relate to each other?
With these fairly complex algorithms often being described as “giant black boxes” in news and media, a demand for clear and accessible resources is surging. Fine-tuning may involve further training the pre-trained model on a smaller, task-specific labeled dataset, using supervisedlearning.
It includes supervised and unsupervised learning. SupervisedLearning deals with labels data and unsupervised learning deals with unlabelled data. Supervisedlearning can be classified into classification and regression where regression deals with continuous values and the former deals with discrete values.
The emergence of transformers and self-supervisedlearning methods has allowed us to tap into vast quantities of unlabeled data, paving the way for large pre-trained models, sometimes called “ foundation models.” Learn more about watsonx.ai But this is starting to change.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content