This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hype Cycle for Emerging Technologies 2023 (source: Gartner) Despite AI’s potential, the quality of input data remains crucial. Inaccurate or incomplete data can distort results and undermine AI-driven initiatives, emphasizing the need for cleandata. Cleandata through GenAI!
By improving data quality, preprocessing facilitates better decision-making and enhances the effectiveness of data mining techniques, ultimately leading to more valuable outcomes. Key techniques in data preprocessing To transform and cleandata effectively, several key techniques are employed.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction “Data is the fuel for Machine Learning algorithms” Real-world. The post How to Handle Missing Values of Categorical Variables? appeared first on Analytics Vidhya.
Introduction Datacleaning is one area in the Data Science life cycle that not even data analysts have to do. Still, data scientists and their daily task are to clean the data so that machine learning algorithms will have the data good enough to […].
The development of a Machine Learning Model can be divided into three main stages: Building your ML data pipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
The Power of Embeddings with Vector Search Embeddings are a powerful tool for representing data in an easy-to-understand way for machine learning algorithms. ChatGPT is a large language model that can be used for a variety of tasks, including data analysis and visualization.
In this article, we will discuss how Python runs data preprocessing with its exhaustive machine learning libraries and influences business decision-making. Data Preprocessing is a Requirement. Data preprocessing is converting raw data to cleandata to make it accessible for future use.
Machine learning algorithms require the use of various parameters that govern the learning process. This includes datacleaning, data normalization, and feature selection. These parameters are called hyperparameters, and their optimal values are often unknown a priori.
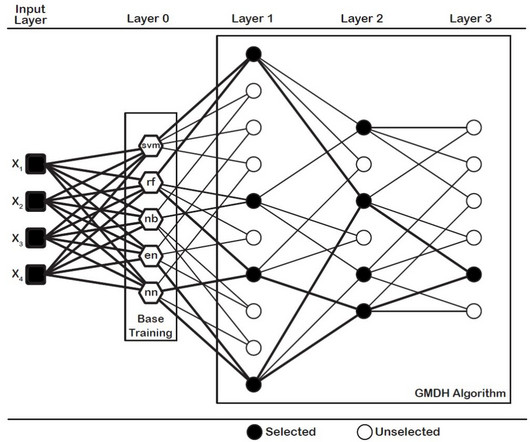
The dce-GMDH type neural network algorithm is a heuristic self-organizing algorithm to assemble the well-known classifiers. Find out how to apply dce-GMDH algorithm for binary classification in R. Architecture of GMDH Algorithm (Dag et al., Before we go ahead, we load dataset and start to process the data.
The following blog is a complete guide on Algorithmic Bias- What is it and How to Avoid it?, What is Algorithmic Bias? Algorithmic bias refers to the presence of unfair or discriminatory outcomes produced by algorithms or machine learning models due to biased data or design choices.
Methodologies in Deploying Data Analytics The application of data analytics in fast food legal cases requires a thorough understanding of the methodologies involved. This involves data collection , datacleaning, data analysis, and data interpretation.
This accessible approach to data transformation ensures that teams can work cohesively on data prep tasks without needing extensive programming skills. With our cleaneddata from step one, we can now join our vehicle sensor measurements with warranty claim data to explore any correlations using data science.
The Best YouTube Downloader for ML Enthusiasts Before we dive into the how-to, let me introduce you to an awesome tool that’s about to become your new best friend in data collection. Y2Mate is the fastest YouTube downloader tool available, working like a well-optimized algorithm to convert and download videos in record time!
These chatbots use natural language processing (NLP) algorithms to understand user queries and offer relevant solutions. AI-Enhanced Troubleshooting and Issue Resolution AI algorithms can analyze historical data to identify past solutions to similar technical problems.
Cleanlab is an open-source software library that helps make this process more efficient (via novel algorithms that automatically detect certain issues in data) and systematic (with better coverage to detect different types of issues). How does cleanlab work?
Introduction Data annotation plays a crucial role in the field of machine learning, enabling the development of accurate and reliable models. In this article, we will explore the various aspects of data annotation, including its importance, types, tools, and techniques.
Their expertise lies in designing algorithms, optimizing models, and integrating them into real-world applications. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on data analysis and interpretation to extract meaningful insights.
Data scientists are the master keyholders, unlocking this portal to reveal the mysteries within. They wield algorithms like ancient incantations, summoning patterns from the chaos and crafting narratives from raw numbers. At the heart of the matter lies the query, “What does a data scientist do?”
Its underlying Singer framework allows the data teams to customize the pipeline with ease. It detaches from the complicated and computes heavy transformations to deliver cleandata into lakes and DWHs. . Algorithms make predictions by using statistical methods and help uncover several key insights in data mining projects.
A generative AI company exemplifies this by offering solutions that enable businesses to streamline operations, personalise customer experiences, and optimise workflows through advanced algorithms. Data forms the backbone of AI systems, feeding into the core input for machine learning algorithms to generate their predictions and insights.
The course covers the basics of Deep Learning and Neural Networks and also explains Decision Tree algorithms. Lesson #2: How to clean your data We are used to starting analysis with cleaningdata. Surprisingly, fitting a model first and then using it to clean your data may be more effective.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for data preparation before analysis. Data Analysis and Modeling This stage is focused on discovering patterns, trends, and insights through statistical methods, machine-learning models, and algorithms. And Why did it happen?).
We assign a PreciselyID to every address in our database, linking each location to our portfolio’s vast array of data. From a data science perspective, this offers tremendous advantages. High-integrity data avoids the introduction of noise, resulting in more robust models. Cleandata reduces the need for data prep.
With this invaluable guide, we unravel the intriguing capabilities of Janitor AI API, demonstrating how its seamless integration, model training, performance evaluation, and continuous monitoring can be harnessed to unlock a new era of interactive communication and efficient data management. What is Janitor AI?
It’s like the heavy-duty cleaning you might do before moving into a new house, where you meticulously scrub floors, remove stains, and ensure everything is spotless. It utilizes sophisticated algorithms and techniques to tackle various data imperfections. Data scrubbing is the knight in shining armour for BI.
The quality of your training data in Machine Learning (ML) can make or break your entire project. This article explores real-world cases where poor-quality data led to model failures, and what we can learn from these experiences. By the end, you’ll see why investing in quality data is not just a good idea, but a necessity.
The MLOps process can be broken down into four main stages: Data Preparation: This involves collecting and cleaningdata to ensure it is ready for analysis. The data must be checked for errors and inconsistencies and transformed into a format suitable for use in machine learning algorithms.
The daily life of an ML engineer includes among others: Manual inspection and exploration of data Training models and evaluating model results Managing model deployments and model monitoring processes. Writing custom algorithms and scripts.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Rather than solely focusing on model architecture, hyperparameters, and training tricks as the sole drivers of model improvement, data-centric AI utilizes the model itself to systematically improve the dataset (such that a better version of the model can be produced even without any change in the modeling code).
While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. Cleandata is important for good model performance.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. DataCleaningDatacleaning is crucial for data integrity.
AI assists in suggesting what data to acquire from specific sources and establishing connections within the data. Algorithms for Data Quality Enhancement Choosing the right algorithms and queries is imperative for companies dealing with extensive datasets. How to Use AI in Quality Assurance?
However, despite being a lucrative career option, Data Scientists face several challenges occasionally. The following blog will discuss the familiar Data Science challenges professionals face daily. Data Pre-processing is a necessary Data Science process because it helps improve the accuracy and reliability of data.
ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. Sophisticated ML algorithms drive the intelligence behind conversational AI, enabling it to learn and enhance its capabilities through experience. Cleandata is fundamental for training your AI.
Raw data often contains inconsistencies, missing values, and irrelevant features that can adversely affect the performance of Machine Learning models. Proper preprocessing helps in: Improving Model Accuracy: Cleandata leads to better predictions. Scikit-learn: For Machine Learning algorithms and preprocessing utilities.
Technical Skills Technical skills form the foundation of a Data Scientist’s toolkit, enabling the analysis, manipulation, and interpretation of complex data sets. Machine Learning Algorithms Understanding and implementing Machine Learning Algorithms is a core requirement.
We asked the community to bring its best and most recent research on how to further the field of data-centric AI, and our accepted applicants have delivered. Those approved so far cover a broad range of themes—including datacleaning, data labeling, and data integration.
We asked the community to bring its best and most recent research on how to further the field of data-centric AI, and our accepted applicants have delivered. Those approved so far cover a broad range of themes—including datacleaning, data labeling, and data integration.
Here’s a real-world cautionary tale from popular real estate platform, Zillow: the company made headlines after purchasing 9,680 homes in a single quarter – based on suggestions from its AI algorithm. This is what makes the breadth and depth of your AI data so essential. The problem? Effective feature engineering. Reduced overfitting.
She is working on research and development of Machine Learning algorithms for high-impact customer applications in a variety of industrial verticals to accelerate their AI and cloud adoption. Her research interest includes model interpretability, causal analysis, human-in-the-loop AI and interactive data visualization.
Raw data, such as images or text, often contain irrelevant or redundant information that hinders the model’s performance. By extracting key features, you allow the Machine Learning algorithm to focus on the most critical aspects of the data, leading to better generalisation. What is Feature Extraction?
Datacleaning identifies and addresses these issues to ensure data quality and integrity. Data Analysis: This step involves applying statistical and Machine Learning techniques to analyse the cleaneddata and uncover patterns, trends, and relationships.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content