This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more. Vector Similarity Search This video explains what vector databases are and how they can be used for vector similarity searches.
The development of a Machine Learning Model can be divided into three main stages: Building your ML data pipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
This accessible approach to data transformation ensures that teams can work cohesively on data prep tasks without needing extensive programming skills. With our cleaneddata from step one, we can now join our vehicle sensor measurements with warranty claim data to explore any correlations using data science.
It detaches from the complicated and computes heavy transformations to deliver cleandata into lakes and DWHs. . Their data pipelining solution moves the business entity data through the concept of micro-DBs, which makes it the first of its kind successful solution. Data Pipeline Architecture Planning.
The key to this capability lies in the PreciselyID , a unique and persistent identifier for addresses that uses our master location data and address fabric data. We assign a PreciselyID to every address in our database, linking each location to our portfolio’s vast array of data. Easier model maintenance.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. Cleandata is important for good model performance.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. Sources of DataData can come from multiple sources.
It’s like the heavy-duty cleaning you might do before moving into a new house, where you meticulously scrub floors, remove stains, and ensure everything is spotless. It utilizes sophisticated algorithms and techniques to tackle various data imperfections. Data scrubbing is the knight in shining armour for BI.
It’s essential to ensure that data is not missing critical elements. Consistency Data consistency ensures that data is uniform and coherent across different sources or databases. Timeliness Timeliness relates to the relevance of data at a specific point in time.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
With Prep, users can easily and quickly combine, shape, and cleandata for analysis with just a few clicks. In this blog, we’ll discuss ways to make your data preparation flow run faster. These tips can be used in any of your Prep flows but will have the most impact on your flows that connect to large database tables.
With Prep, users can easily and quickly combine, shape, and cleandata for analysis with just a few clicks. In this blog, we’ll discuss ways to make your data preparation flow run faster. These tips can be used in any of your Prep flows but will have the most impact on your flows that connect to large database tables.
Technical Skills Technical skills form the foundation of a Data Scientist’s toolkit, enabling the analysis, manipulation, and interpretation of complex data sets. SQL is indispensable for database management and querying. Skills in data manipulation and cleaning are necessary to prepare data for analysis.
Video Presentation of the B3 Project’s Data Cube. Presenters and participants had the opportunity to hear about and evaluate the pros and cons of different back end technologies and data formats for different uses such as web-mapping, data visualization, and the sharing of meta-data. Data Intelligence , 2 (1–2), 199–207.
Programming languages such as Python, R, SQL, and others are widely used in Data Analytics. With coding skills, Data Analysts can automate repetitive tasks, develop custom algorithms, and implement complex statistical analyses. Python, known for its simplicity and versatility, is highly favored by Data Analysts.
Raw data often contains inconsistencies, missing values, and irrelevant features that can adversely affect the performance of Machine Learning models. Proper preprocessing helps in: Improving Model Accuracy: Cleandata leads to better predictions. Scikit-learn: For Machine Learning algorithms and preprocessing utilities.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
Key aspects of model-centric AI include: Algorithm Development: Creating and optimizing algorithms to improve a model’s performance. Data-Centric AI Data-centric AI is an approach to artificial intelligence development that focuses on improving the quality and utility of the data used to train AI models.
Key aspects of model-centric AI include: Algorithm Development: Creating and optimizing algorithms to improve a model’s performance. Data-Centric AI Data-centric AI is an approach to artificial intelligence development that focuses on improving the quality and utility of the data used to train AI models.
Raw data is processed to make it easier to analyze and interpret. Because it can swiftly and effectively handle data structures, carry out calculations, and apply algorithms, Python is the perfect language for handling data. data = data.dropna() We can also use the drop_duplicates() method to remove duplicated rows.
Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services. Database Extraction: Retrieval from structured databases using query languages like SQL. Aggregation: Summarising data into meaningful metrics or aggregates.
There are 5 stages in unstructured data management: Data collection Data integration DatacleaningData annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. We get your data RAG-ready.
Key Processes and Techniques in Data Analysis Data Collection: Gathering raw data from various sources (databases, APIs, surveys, sensors, etc.). DataCleaning & Preparation: This is often the most time-consuming step. to understand the data’s main characteristics, distributions, and relationships.
Read the full blog here — [link] Data Science Interview Questions for Freshers 1. What is Data Science? Once the data is acquired, it is maintained by performing datacleaning, data warehousing, data staging, and data architecture. It further performs badly on the test data set.
Understand the Data Sources The first step in data standardization is to identify and understand the various data sources that will be standardized. This includes databases, spreadsheets, APIs, and manual records. This could include internal databases, external APIs, and third-party data providers.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. Advanced algorithms recognize patterns in temporal data effectively. Step 2: Data Gathering Collect relevant historical data that will be used for forecasting.
It provides high-quality, curated data, often with associated tasks and domain-specific challenges, which helps bridge the gap between theoretical ML algorithms and real-world problem-solving. The data can then be explored, cleaned, and processed to be used in Machine Learning models.
The systems are designed to ensure data integrity, concurrency and quick response times for enabling interactive user transactions. In online analytical processing, operations typically consist of major fractions of large databases. The step varies slightly from process to process depending on the source of data being processed.
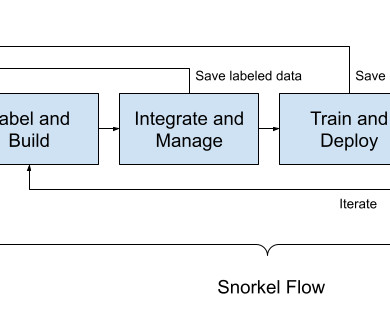
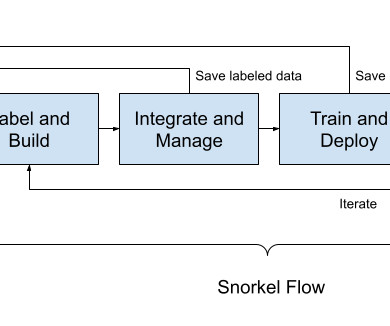
I don’t think we would have been able to write a paper about just “vector-database-plus-language-model.” The original paper that coined the term “ large language model ” was a 2007 Google paper where they used an algorithm called “Stupid Backoff.” You need data that’s labeled and curated for your use case.
I don’t think we would have been able to write a paper about just “vector-database-plus-language-model.” The original paper that coined the term “ large language model ” was a 2007 Google paper where they used an algorithm called “Stupid Backoff.” You need data that’s labeled and curated for your use case.
Often, it requires you to co-design the algorithm and also the system set. If they’re necessary, how can we create a new algorithm to accommodate it? How can we adapt the model to different scenarios as systematic and data-efficient as possible? In this case, you can also use fairness as an objective for data debugging.
Often, it requires you to co-design the algorithm and also the system set. If they’re necessary, how can we create a new algorithm to accommodate it? How can we adapt the model to different scenarios as systematic and data-efficient as possible? In this case, you can also use fairness as an objective for data debugging.
These tools leverage complex algorithms and data processing capabilities to enhance operational efficiency. Identifying appropriate data sources. Organizing and cleaningdata. It incorporates structured, unstructured, and mixed data to enhance decision-making capabilities.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content