This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you have a large-scale production workload and want to take the time to tune for the best price-performance and the most flexibility, you can use an OpenSearch Service managed cluster. For more details on best practices for operating an OpenSearch Service managed cluster, see Operational best practices for Amazon OpenSearch Service.
By developing an algorithm that transforms natural language propositions into structured coherence graphs, the researchers benchmark AI models’ ability to reconstruct logical relationships. To maximize coherence by separating true and false statements into different clusters. What is coherence-driven inference? The problem?
A right-sized cluster will keep this compressed index in memory. Disk mode uses the HNSW algorithm to build indexes, so m is one of the algorithm parameters, and it defaults to 16. Dylan holds a BSc and MEng degree in ComputerScience from Cornell University. His primary interests include distributed systems.
Posted by Vincent Cohen-Addad and Alessandro Epasto, Research Scientists, Google Research, Graph Mining team Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. When clustering is applied to personal data (e.g.,
In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise. The purpose is to improve accuracy by either training a global model that contains the cluster configuration or have local models specific to each cluster.
One of the simplest and most popular methods for creating audience segments is through K-means clustering, which uses a simple algorithm to group consumers based on their similarities in areas such as actions, demographics, attitudes, etc. In this tutorial, we will work with a data set of users on Foursquare’s U.S.
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
However, these studies used small datasets, had overfitting problems, lacked generalizability, or used complex algorithms that may require additional computational resources. In this study, we collected and analyzed center-based data and used a recursive embedding and clustering technique to reduce their dimensionality.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Machine Learning is a subset of Artificial Intelligence and ComputerScience that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification.
As industries increasingly adopt AI solutions, professionals without a technical background can now step into the realm of machine learning, leveraging powerful algorithms to automate tasks and improve decision-making. Algorithms utilize large datasets to learn patterns and make predictions. What is machine teaching?
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clusteringalgorithm. The other popular clusteringalgorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering.
This work proposes a robust solution for identifying and classifying a wide spectrum of materials through an iterative technique, called symmetry-based clustering (SBC). Instead, it identifies clusters in atomistic systems by automatically recognizing common unit cells.
Andrew Wilson (Associate Professor of ComputerScience and Data Science) “ A Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning ” by Valeriia Cherepanova, Roman Levin, Gowthami Somepalli, Jonas Geiping, C.
During the iterative research and development phase, data scientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. ML is a computerscience, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. What is machine learning?
Machine learning is a field of computerscience that uses statistical techniques to build models from data. Some of the most popular Python libraries for data science include: NumPy is a library for numerical computation. SciPy is a library for scientific computing. Pandas is a library for data analysis.
With technological developments occurring rapidly within the world, ComputerScience and Data Science are increasingly becoming the most demanding career choices. Moreover, with the oozing opportunities in Data Science job roles, transitioning your career from ComputerScience to Data Science can be quite interesting.
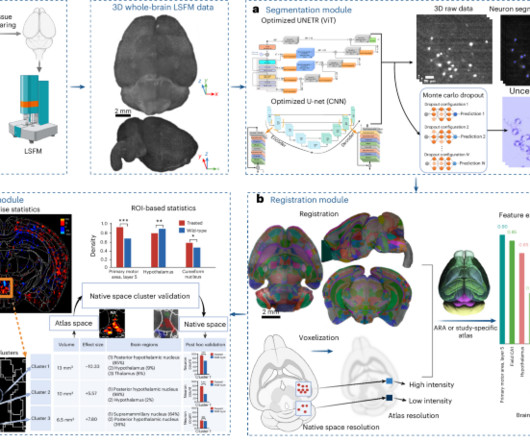
Here, we present artficial intelligence-based cartography of ensembles (ACE), an end-to-end pipeline that employs three-dimensional deep learning segmentation models and advanced cluster-wise statistical algorithms, to enable unbiased mapping of local neuronal activity and connectivity.
Professional certificate for computerscience for AI by HARVARD UNIVERSITY Professional certificate for computerscience for AI is a 5-month AI course that is inclusive of self-paced videos for participants; who are beginners or possess intermediate-level understanding of artificial intelligence.
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme. Shall we unravel the true meaning of machine learning algorithms and their practicability?
Amazon SageMaker HyperPod offers an effective solution for provisioning resilient clusters to run ML workloads and develop state-of-the-art models. Additionally, its modular design and integration of cutting-edge algorithms, such as FlashAttention-2 and GaLore , facilitate high performance and scalability. He holds an M.Sc.
This integration can help you better understand the traffic impact on your distributed deep learning algorithms. Set up the CloudWatch Observability EKS add-on Refer to Install the Amazon CloudWatch Observability EKS add-on for instructions to create the amazon-cloudwatch-observability add-on in your EKS cluster.
You will likely find that the histogram is bell-shaped, with most of the students clustered around the average height and fewer students at the extremes. Information theory is used in many different areas of communication, computerscience, and statistics. Learn about Top Machine Learning Algorithms for Data Science 11.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. He holds a Bachelors degree in ComputerScience and Bioinformatics.
Graph visualization: Information visualization is a branch of mathematics and computerscience that exists at the intersection of geometric graph theory and computerscience. Graph clustering: The visualization of data in the form of graphs is referred to as clustering. How do Graph Neural Networks work?
To put it another way, a data scientist turns raw data into meaningful information using various techniques and theories drawn from many fields within the broad areas of mathematics, statistics, information science, and computerscience. Machine learning Machine learning is a key part of data science.
Data Science Fundamentals Going beyond knowing machine learning as a core skill, knowing programming and computerscience basics will show that you have a solid foundation in the field. Computerscience, math, statistics, programming, and software development are all skills required in NLP projects.
In this piece, we shall look at tips and tricks on how to perform particular GIS machine learning algorithms regardless of your expertise in GIS, if you are a fresh beginner with no experience or a seasoned expert in geospatial machine learning. Load required librarieslibrary(sf) # spatial datalibrary(raster) # for raster manipulation 1.
To mitigate these risks, the FL model uses personalized training algorithms and effective masking and parameterization before sharing information with the training coordinator. Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking.
To identify factors predictive of BT during the perioperative period of THA, we employed LASSO regression and the random forest (RF) algorithm as part of supervised machine learning (SML). Furthermore, we utilized unsupervised machine learning (UML) techniques to cluster THA patients who required BT based on similar clinical features.
Although GraphStorm can run efficiently on single instances for small graphs, it truly shines when scaling to enterprise-level graphs in distributed mode using a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances or Amazon SageMaker. Today, AWS AI released GraphStorm v0.4.
Data retrieval and augmentation – When a query is initiated, the Vector Database Snap Pack retrieves relevant vectors from OpenSearch Service using similarity search algorithms to match the query with stored vectors. He focuses on Deep learning including NLP and Computer Vision domains.
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. And Why Anomaly Detection?
Algorithms: AI algorithms are used to process the data and extract insights from it. There are several types of AI algorithms, including supervised learning, unsupervised learning, and reinforcement learning. Develop AI models using machine learning or deep learning algorithms.
These computerscience terms are often used interchangeably, but what differences make each a unique technology? To keep up with the pace of consumer expectations, companies are relying more heavily on machine learning algorithms to make things easier. Technology is becoming more embedded in our daily lives by the minute.
The networking layer is complemented by a high-performance Amazon FSx for Lustre file system, alongside an Amazon Simple Storage Service (Amazon S3) bucket configured to store lifecycle scripts, which are used to configure the SageMaker HyperPod cluster.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Parallel computing uses these multiple processing elements simultaneously to solve a problem. PBAs, such as graphics processing units (GPUs), have an important role to play in both these phases.
Summary: Hash function are essential algorithms that convert input data into fixed-size outputs. Introduction Hash functions are crucial in computerscience and cryptography. A hash function is a mathematical algorithm that transforms input data into a fixed-size string of characters. What is a Hash Function?
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. By analyzing how users have interacted with items in the past, we can use algorithms to approximate the utility function and make personalized recommendations that users will love.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Tools like Tableau, Power BI, and Python libraries such as Matplotlib and Seaborn are commonly taught. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content