This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Improve Cluster Balance with the CPD Scheduler — Part 1 The default Kubernetes (“k8s”) scheduler can be thought of as a sort of “greedy” scheduler, in that it always tries to place pods on the nodes that have the most free resources. It became apparent that the default Kubernetes scheduler algorithm was the culprit.
It’s an integral part of data analytics and plays a crucial role in data science. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics. Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, data modeling, and data visualization.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? By leveraging anomaly detection, we can uncover hidden irregularities in transaction data that may indicate fraudulent behavior.
Applied Data Science However, Applied Data Science, a subset of Data Science, offers a more practical and industry-specific approach. But what are the key concepts and methodologies involved in Applied Data Science? Machine learning algorithms Machine learning forms the core of Applied Data Science.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects.
One of the most popular algorithms in Machine Learning are the Decision Trees that are useful in regression and classification tasks. In Supervised Learning, Decision Trees are the Machine Learning algorithms where you can split data continuously based on a specific parameter. How Decision Tree Algorithm works?
Introduction to Deep Learning Algorithms: Deep learning algorithms are a subset of machine learning techniques that are designed to automatically learn and represent data in multiple layers of abstraction. This process is known as training, and it relies on large amounts of labeled data. How Deep Learning Algorithms Work?
This helps with datapreparation and feature engineering tasks and model training and deployment automation. Moreover, they require a pre-determined number of topics, which was hard to determine in our data set. The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method.
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. And Why Anomaly Detection?
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. Another way can be to use an AllReduce algorithm.
Datapreparation For this example, you will use the South German Credit dataset open source dataset. The following code demonstrates how to track your experiments when executing your code on a SageMaker ephemeral cluster using the @remote decorator. In both cases, you can track your experiments using MLflow.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Importance of Data in AI Quality data is the lifeblood of AI models, directly influencing their performance and reliability.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering. This can cause limitations if you need to consider more metrics than this.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. For more information about fine tuning Sentence Transformer, see Sentence Transformer training overview.
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis. With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
For many years, Philips has been pioneering the development of data-driven algorithms to fuel its innovative solutions across the healthcare continuum. Also in patient monitoring, image guided therapy, ultrasound and personal health teams have been creating ML algorithms and applications.
The Data Scientist’s responsibility is to move the data to a data lake or warehouse for the different data mining processes. DataPreparation: the stage prepares the data collected and gathered for preparation for data mining. are the various data mining tools.
The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. Standard feature engineering Our datapreparation process begins with standard feature engineering. A crucial step in our datapreparation is the application of a pre-trained NER model.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Here are the steps involved in predictive analytics: Collect Data : Gather information from various sources like customer behavior, sales, or market trends. Clean and Organise Data : Prepare the data by removing errors and making it ready for analysis. Test the Model : Ensure that the model is accurate and works well.
Lesson 1: Mitigating data sparsity problems within ML classification algorithms What are the most popular algorithms used to solve a multi-class classification problem? So, the model might not have a sufficient number of data samples to learn the pattern for each class. Let’s take a look at some of them.
The two most common types of supervised learning are classification , where the algorithm predicts a categorical label, and regression , where the algorithm predicts a numerical value. Unsupervised Learning In this type of learning, the algorithm is trained on an unlabeled dataset, where no correct output is provided.
The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more. It provides high-quality, curated data, often with associated tasks and domain-specific challenges, which helps bridge the gap between theoretical ML algorithms and real-world problem-solving.
5 Industries Using Synthetic Data in Practice Here’s an overview of what synthetic data is and a few examples of how various industries have benefited from it. How to Use Machine Learning for Algorithmic Trading Machine learning has proven to be a huge boon to the finance industry. Here’s how.
Domain knowledge is crucial for effective data application in industries. What is Data Science and Artificial Intelligence? Data Science is an interdisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data.
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform Exploratory Data Analysis to uncover patterns and insights hidden within the data. This phase entails meticulously selecting and training algorithms to ensure optimal performance.
The platform can assign specific roles to team members involved in the packaging process and grant them access to relevant aspects such as datapreparation, training, deployment, and monitoring. Developers can deploy their models on a cluster of servers and use Kubernetes to manage the resources needed for training and inference.
The Ranking team at Booking.com plays a pivotal role in ensuring that the search and recommendation algorithms are optimized to deliver the best results for their users. Training optimization The rise of deep learning (DL) has led to ML becoming increasingly reliant on computational power and vast amounts of data.
Applications : Stock price prediction and financial forecasting Analysing sales trends over time Demand forecasting in supply chain management Clustering Models Clustering is an unsupervised learning technique used to group similar data points together. Popular clusteringalgorithms include k-means and hierarchical clustering.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. It is designed to leverage hardware acceleration (e.g.,
Some CUDA versions may require a minimum CC to be available, and CUDA versions may be required for certain frameworks and algorithms. The formula: [ AI = frac{text{FLOPs}}{text{Bytes Transferred to/from Memory}} ] FLOPs - The number of floating-point operations required by your algorithm. This is the just foundation.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
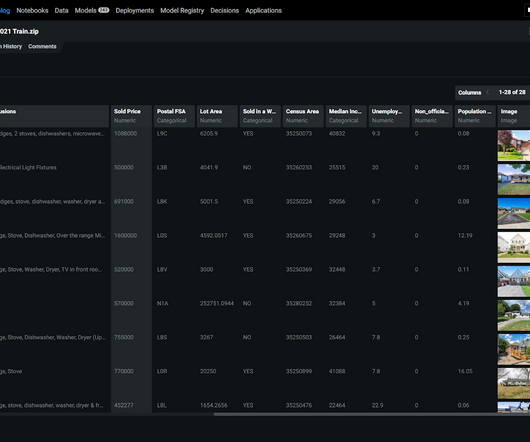
When working with location-oriented data like houses in a neighborhood, a capability that really helps within DataRobot is Automated Geospatial Feature Engineering that converts latitude and longitude into points on the map. The algorithm blueprint, including all steps taken, can be viewed for each item on the leaderboard.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content