This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. Vector databases are revolutionizing healthcare data management. That’s where vector databases come in handy—they are made on purpose to handle this special kind of data.
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machine learning applications.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
A right-sized cluster will keep this compressed index in memory. Disk mode uses the HNSW algorithm to build indexes, so m is one of the algorithm parameters, and it defaults to 16. He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearchs vector database capabilities.
Databases are the unsung heroes of AI Furthermore, data archiving improves the performance of applications and databases. By removing infrequently accessed data from primary storage systems, organizations can improve the performance of their applications and databases, which can lead to increased productivity and efficiency.
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
INTRODUCTION Machine Learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn and make predictions or decisions based on data, without being explicitly programmed. The algorithm learns to map the input data to the correct output based on the provided examples.
Hash joins and sort-merge joins have been considered the algorithms of choice for analytical relational queries in most parallel database systems because of their performance robustness and ease of parallelization. In this paper, we revisit the potential of nested loop joins in a cluster environment.
Learn the what and why of vector databases and how to use Weaviate vector database with embeddings for searching and retrieving images. Motivation Conventional databases (e.g. relational databases) lead to performance issues and bottlenecks when storing high-dimensional vectors in tabular format. Enter vector databases!
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector. Its hosted on AWS Lambda.
A current barrier to effective database queries lies in the often ambiguous, inconsistent, or completely missing classification of existing data, highlighting the need for standardized, automated, and verifiable classification methods. Instead, it identifies clusters in atomistic systems by automatically recognizing common unit cells.
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification. What is Classification?
Above: Tim Fu used paper crumpled in different ways as a prompt for AI tool LookX It is trained on an architectural database called ArchiNet and has been "equipped with [the] industry's semantics and annotations," LookX said. "By
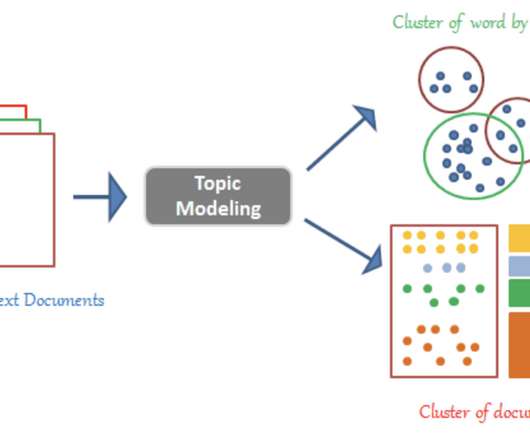
Topic Modeling In this blog, we walk you through the popular Open Source Latent Dirichlet Allocation (LDA) Topic Modeling from conventional algorithms and Watson NLP Topic Modeling. Latent Dirichlet Allocation (LDA) Topic Modeling LDA is a well-known unsupervised clustering method for text analysis.
Previously, OfferUps search engine was built with Elasticsearch (v7.10) on Amazon Elastic Compute Cloud (Amazon EC2), using a keyword search algorithm to find relevant listings. The search microservice processes the query requests and retrieves relevant listings from Elasticsearch using keyword search (BM25 as a ranking algorithm).
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Vector Databases 101: A Beginners Guide to Vector Search and Indexing Photo by Google DeepMind on Unsplash Introduction Alright, folks! The secret sauce behind all of this is vector search and vector databases, helping power similarity-based recommendations and retrieval! Traditional databases? They tap out.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
Visualizing graph data doesn’t necessarily depend on a graph database… Working on a graph visualization project? You might assume that graph databases are the way to go – they have the word “graph” in them, after all. Do I need a graph database? It depends on your project. Unstructured? Under construction?
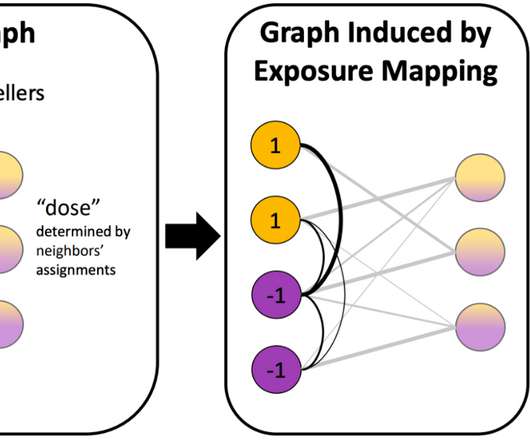
Posted by Haim Kaplan and Yishay Mansour, Research Scientists, Google Research Differential privacy (DP) machine learning algorithms protect user data by limiting the effect of each data point on an aggregated output with a mathematical guarantee. Two adjacent datasets that differ in a single outlier. are both close to a third point ?
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., Different algorithms and techniques are employed to achieve eventual consistency. XML, JSON), and unstructured data (e.g.,
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & The Big Question we need to deal with…!)
MongoDB’s robust time series data management allows for the storage and retrieval of large volumes of time-series data in real-time, while advanced machine learning algorithms and predictive capabilities provide accurate and dynamic forecasting models with SageMaker Canvas. Setup the Database access and Network access.
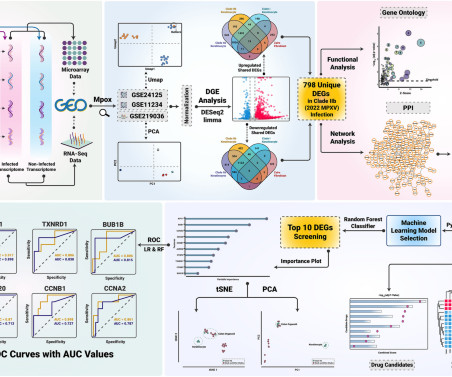
Subsequently, gene expression network analyses pinpoint the key DEGs, followed by their candidate drug assessment using the Drug SIGnatures DataBase (DSigDB) and validation by multiple machine learning algorithms. for clade IIb infection.
In our previous article on Retrieval Augmented Generation (RAG), we discussed the need for a Vector Database to retrieve additional information for our prompts. Today, we will dive into the inner workings of a Vector Database to better understand exactly how this technology functions. What is a Vector Database in Simple Terms?
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. This is where the utilization of vector databases like Pinecone becomes valuable to store all the past experiences and aids as the memory for LLMs.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Meme shared by bin4ry_d3struct0r TAI Curated section Article of the week Building a YoutubeGPT with LangChain, Gradio, and Vector Database by Yanli Liu This article discusses the GenAI Application Development Stack, a key to creating customized AI solutions. It also explores key components like LangChain, Gradio, and Vector Database.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. What is Unsupervised Machine Learning?
You can see its power in everyday applications like URL shorteners , database indexes, and password verification systems. Hashing underpins critical applications, from database indexing to secure password storage. This method distributes items more evenly, reducing clustering and improving overall efficiency. What is Hashing?
This NoSQL database is optimized for rapid access, making sure the knowledge base remains responsive and searchable. His primary focus lies in using the full potential of data, algorithms, and cloud technologies to drive innovation and efficiency.
From there, a machine learning framework like TensorFlow, H2O, or Spark MLlib uses the historical data to train analytic models with algorithms like decision trees, clustering, or neural networks. Tiered Storage enables long-term storage with low cost and the ability to more easily operate large Kafka clusters.
Is K-means clustering different from KNN? You can also use your knowledge of big data to create AI algorithms that will prevent fraud in games that involve spending money. We decided to share some of them here: How do you balance the need for variance with minimizing data bias? How does the ROC curve play a role in machine learning?
Data storage databases. Your SaaS company can automate time-consuming tasks like provisioning, patching, backup, recovery, and failure detection and repair with Amazon Aurora, a MySQL-compatible database from Amazon. AWS also offers developers the technology to develop smart apps using machine learning and complex algorithms.
Unlike the old days where data was readily stored and available from a single database and data scientists only needed to learn a few programming languages, data has grown with technology. This will enable you to leverage the right algorithms to create good, well structured, and performing software. Understand the Databases.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. in a 2D space based on the machine learning algorithm used. Are you interested in exploring Snowflake as a vector database?
A users question is used as the query to retrieve relevant documents from a database. LangChain offers a collection of open-source building blocks, including memory management , data loaders for various sources, and integrations with vector databases all the essential components of a RAG system. Overview of a baseline RAG system.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content