This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Analyzing DecisionTree and K-means Clustering using Iris dataset. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction: As we all know, Artificial Intelligence is being widely. appeared first on Analytics Vidhya.
Types of Machine Learning Algorithms 3. DecisionTree 7. K Means Clustering Introduction We all know how Artificial Intelligence is leading nowadays. The post Machine Learning Algorithms appeared first on Analytics Vidhya. Introduction 2. Simple Linear Regression 4. Multilinear Regression 5.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithms learn from labeled data , similar to classification.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. These intelligent predictions are powered by various Machine Learning algorithms.
Ultimately, we can use two or three vital tools: 1) [either] a simple checklist, 2) [or,] the interdisciplinary field of project-management, and 3) algorithms and data structures. In addition to the mindful use of the above twelve elements, our Google-search might reveal that various authors suggest some vital algorithms for data science.
By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Data mining During the data mining phase, various techniques and algorithms are employed to discover patterns and correlations. ClusteringClustering groups similar data points based on their attributes.
Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts. Unsupervised models Unsupervised models typically use traditional statistical methods such as logistic regression, time series analysis, and decisiontrees.
Frederik Holtel · Follow Published in Towards AI ·5 min read·2 days ago 11 Listen Share Source: bugphai on www.istockphotos.com When I learned about decisiontrees for the first time, I thought that it would be very useful to have a simple plotting tool to play around with and develop an intuitive understanding of what is going on.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
K-Means Clustering What is K-Means Clustering in Machine Learning? K-Means Clustering is an unsupervised machine learning algorithm used for clustering data points into groups or clusters based on their similarity. How Does K-Means Clustering Work? How is K Determined in K-Means Clustering?
One of the most popular algorithms in Machine Learning are the DecisionTrees that are useful in regression and classification tasks. Decisiontrees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning. How DecisionTreeAlgorithm works?
Business Benefits: Organizations are recognizing the value of AI and data science in improving decision-making, enhancing customer experiences, and gaining a competitive edge An AI research scientist acts as a visionary, bridging the gap between human intelligence and machine capabilities. Privacy: Protecting user privacy and data security.
It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. For instance, a classification algorithm could predict whether a transaction is fraudulent or not based on various features.
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the DecisionTree. This often occurs in Cluster Analysis, where we identify clusters without prior information. Before we start, please consider following me on Medium or LinkedIn.
Formatting the data in a way that ML algorithms can understand. Model selection and training: Teaching machines to learn With your data ready, it’s time to select an appropriate ML algorithm. Popular choices include: Supervised learning algorithms like linear regression or decisiontrees for problems with labeled data.
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification. What is Classification?
It provides a wide range of mathematical functions and algorithms. It provides a wide range of visualization tools. By leveraging models, data scientists can extrapolate trends and behaviors, facilitating proactive decision-making. Decisiontrees are used to classify data into different categories.
Selecting the right algorithm There are several data mining algorithms available, each with its strengths and weaknesses. When selecting an algorithm, consider factors such as the size and type of your dataset, the problem you’re trying to solve, and the computational resources available.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Featured Community post from the Discord Aman_kumawat_41063 has created a GitHub repository for applying some basic ML algorithms. It offers pure NumPy implementations of fundamental machine learning algorithms for classification, clustering, preprocessing, and regression. This repo is designed for educational exploration.
It directly focuses on implementing scientific methods and algorithms to solve real-world business problems and is a key player in transforming raw data into significant and actionable business insights. Machine learning algorithms Machine learning forms the core of Applied Data Science.
Later on, we will train a classifier for Car Evaluation data, by Encoding the data, Feature extraction and Developing classifier model using various algorithms and evaluate the results. using PySpark we can run applications parallelly on the distributed cluster… blog.devgenius.io It works on distributed systems and is scalable.
In this piece, we shall look at tips and tricks on how to perform particular GIS machine learning algorithms regardless of your expertise in GIS, if you are a fresh beginner with no experience or a seasoned expert in geospatial machine learning. DecisionTree and R. Types of machine learning with R.
Predictive AI blends statistical analysis with machine learning algorithms to find data patterns and forecast future outcomes. These adversarial AI algorithms encourage the model to generate increasingly high-quality outputs. Decisiontrees implement a divide-and-conquer splitting strategy for optimal classification.
In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations. However, typical algorithms do not produce a binary result but instead, provide a relevancy score for which labels are the most appropriate. Thus tail labels have an inflated score in the metric.
A generative AI company exemplifies this by offering solutions that enable businesses to streamline operations, personalise customer experiences, and optimise workflows through advanced algorithms. Data forms the backbone of AI systems, feeding into the core input for machine learning algorithms to generate their predictions and insights.
From there, a machine learning framework like TensorFlow, H2O, or Spark MLlib uses the historical data to train analytic models with algorithms like decisiontrees, clustering, or neural networks. Tiered Storage enables long-term storage with low cost and the ability to more easily operate large Kafka clusters.
Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme. Shall we unravel the true meaning of machine learning algorithms and their practicability?
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, K Nearest Neighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? For example, it takes millions of images and runs them through a training algorithm.
By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informed decisions and take autonomous actions. This enables them to extract valuable insights, identify patterns, and make informed decisions in real-time.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning. Strictly, everything that I said earlier is based on Machine learning algorithms and, of course, strong math and theory of algorithms behind them. In this article, I will cover all of them.
Unsupervised learning Unsupervised learning is a type of machine learning where the algorithm tries to find patterns or relationships in the data without the use of labeled data. In other words, the algorithm is not given any information about the correct output or class labels for the input data. Next, you need to select a model.
Common machine learning algorithms for supervised learning include: K-nearest neighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. Local outlier factor (LOF ): Local outlier factor is similar to KNN in that it is a density-based algorithm.
The student (the model) studies these examples and the teacher (the algorithm) guides the learning process. Clustering (e.g., Popular techniques include K-Means Clustering (grouping data by similarity), Principal Component Analysis (PCA) (reducing data complexity), and Autoencoders (for finding compact representations of data).
Decision intelligence is an innovative approach that blends the realms of data analysis, artificial intelligence, and human judgment to empower businesses with actionable insights. Think of decision intelligence as a synergy between the human mind and cutting-edge algorithms. What is decision intelligence?
Apparently, ML algorithms ensure to train of the data enabling the new data input to make compelling predictions and deliver accurate results. Supervised Learning is the type of Machine Learning where the training of an algorithm takes place using labelled data. What is Supervised Learning? What is Unsupervised Learning?
ML algorithms, on the other hand, can analyze large amounts of performance data quickly and accurately, providing developers with insights into performance bottlenecks and areas for optimization. Personalized optimization strategies: ML algorithms can analyze user behavior data to create personalized optimization strategies.
A data model for Machine Learning is a mathematical representation or algorithm that learns patterns and relationships from data to make predictions or decisions without being explicitly programmed. Examples of supervised learning models include linear regression, decisiontrees, support vector machines, and neural networks.
Machine learning algorithms, with their ability to recognize patterns, anomalies, and trends within vast datasets, are revolutionizing network traffic analysis by providing more accurate insights, faster response times, and enhanced security measures. This is where the power of machine learning (ML) comes into play.
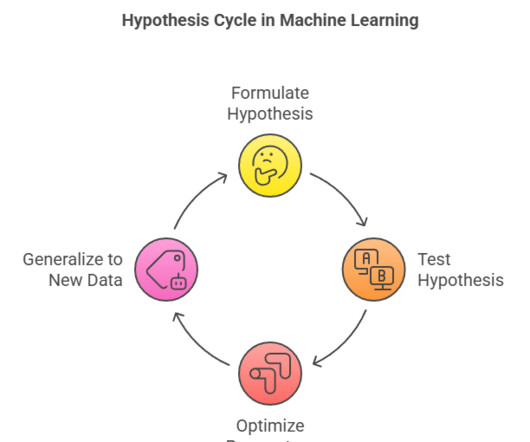
It guides algorithms in testing assumptions, optimizing parameters, and minimizing errors. hypothesis form the foundation for diverse applications, from predictive analytics and recommendation engines to autonomous systems, enabling accurate, data-driven decision-making and improved model performance.
Three years later, the code was released as hey solution for machine learning algorithms in conjunction with Google and several other major companies. Scikit-learn is a library that contains several implementations of machine learning algorithms. Unsupervised classification and clustering. Decisiontree pruning and induction.
Delving further into KNIME Analytics Platform’s Node Repository reveals a treasure trove of data science-focused nodes, from linear regression to k-means clustering to ARIMA modeling—and quite a bit in between. Building a DecisionTree Model in KNIME The next predictive model that we want to talk about is the decisiontree.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content