This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithms learn from labeled data , similar to classification.
By Vatsal Saglani This article explores the creation of PDF2Pod, a NotebookLM clone that transforms PDF documents into engaging, multi-speaker podcasts. The method effectively captures both long-term trends and short-term dependencies, providing a more nuanced understanding of dynamic data compared to traditional clustering methods.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
Improve Cluster Balance with the CPD Scheduler — Part 1 The default Kubernetes (“k8s”) scheduler can be thought of as a sort of “greedy” scheduler, in that it always tries to place pods on the nodes that have the most free resources. It became apparent that the default Kubernetes scheduler algorithm was the culprit.
The model then uses a clusteringalgorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
You can then run searches for the top K documents in an index that are most similar to a given query vector, which could be a question, keyword, or content (such as an image, audio clip, or text) that has been encoded by the same ML model. A right-sized cluster will keep this compressed index in memory.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. Key components include: Orchestrated document processing with AWS Step Functions – The document processing workflow begins with AWS Step Functions , which orchestrates each step in the process.
Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets. As a result, unsupervised ML algorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes. Overall, unsupervised algorithms get to the point of unspecified data bits. Source ].
Data archiving is the systematic process of securely storing and preserving electronic data, including documents, images, videos, and other digital content, for long-term retention and easy retrieval. Lastly, data archiving allows organizations to preserve historical records and documents for future reference.
INTRODUCTION Machine Learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn and make predictions or decisions based on data, without being explicitly programmed. The algorithm learns to map the input data to the correct output based on the provided examples.
Tesla’s Automated Driving Documents Have Been Requested by The U.S. This involves collecting and analyzing data to identify insights and develop solutions, such as predictive models, visualizations, or machine learning algorithms. What Does ChatGPT Mean for Business?
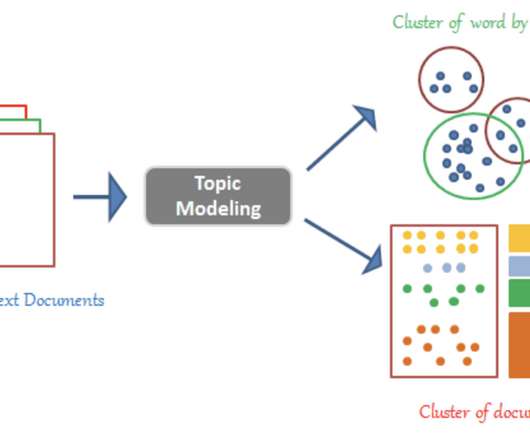
Using the topic modeling approach, a machine can sift through unlimited lists of unstructured content into similar documents. Topic Modeling In this blog, we walk you through the popular Open Source Latent Dirichlet Allocation (LDA) Topic Modeling from conventional algorithms and Watson NLP Topic Modeling.
Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
Companies across various industries create, scan, and store large volumes of PDF documents. There’s a need to find a scalable, reliable, and cost-effective solution to translate documents while retaining the original document formatting. It also uses the open-source Java library Apache PDFBox to create PDF documents.
A users question is used as the query to retrieve relevant documents from a database. The documents returned by the search are added to the prompt that is passed to the LLM together with the users question. Overview of a baseline RAG system. The LLM uses the information in the prompt to generate an answer. Source What is LangChain?
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clusteringalgorithm. The other popular clusteringalgorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering.
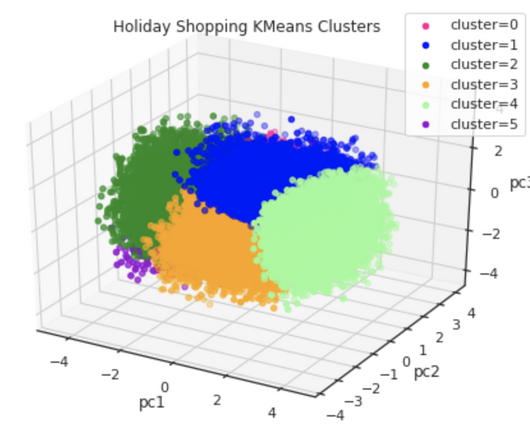
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It is also very common as well to combine K-Means with PCA for visualizing the clustering results, and many clustering applications follow that path (e.g. this link ).
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
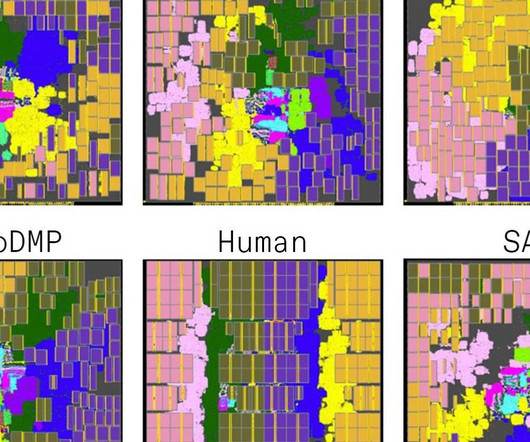
The crux of the clash was whether Google’s AI solution to one of chip design’s thornier problems was really better than humans or state-of-the-art algorithms. In Circuit Training and Morpheus, a separate algorithm fills in the gaps with the smaller parts, called standard cells. The agent places one block at a time on the chip canvas.
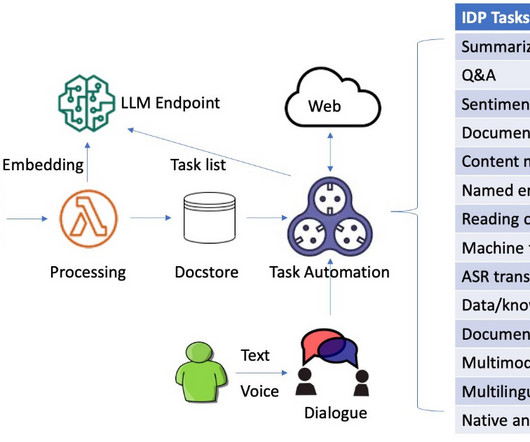
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs.
AI research startup Anthropic aims to raise as much as $5 billion over the next two years to take on rival OpenAI and enter over a dozen major industries, according to company documents obtained by TechCrunch. ” The Information reported in early March that Anthropic was seeking to raise $300 million at $4.1
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
During the iterative research and development phase, data scientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Clustering is a technique that can be used to get a sense of the data while allowing to tell a powerful story. But it can be a huge challenge, even for an expert code-centric data scientist, to understand the signal captured by the algorithm. Introducing Multimodal Clustering. Multimodal Clustering Autopilot.
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. To learn more about the SageMaker model parallel library, refer to SageMaker model parallelism library v2 documentation. You can also refer to our example notebooks to get started.
Advanced algorithms analyze voice characteristics such as pitch, tone, and cadence to differentiate between participants, even when their speech overlaps or occurs in rapid succession. Both traditional clustering methods like K-means, or more advanced algorithms employing neural networks are common.
Here are some key ways data scientists are leveraging AI tools and technologies: 6 Ways Data Scientists are Leveraging Large Language Models with Examples Advanced Machine Learning Algorithms: Data scientists are utilizing more advanced machine learning algorithms to derive valuable insights from complex and large datasets.
Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. It is a cloud-based platform, so it can be accessed from anywhere.
Machine learning is a branch of artificial intelligence that focuses on developing algorithms and models that can learn from data and make predictions or decisions without being explicitly programmed. There are various types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. The implementation included a provisioned three-node sharded OpenSearch Service cluster.
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
For more information on managing credentials securely, see the AWS Boto3 documentation. For example: aws s3 cp /Users/username/Documents/training/loafers s3://footwear-dataset/ --recursive Confirm the upload : Go back to the S3 console, open your bucket, and verify that the images have been successfully uploaded to the bucket.
For example, a health insurance company may want their question answering bot to answer questions using the latest information stored in their enterprise document repository or database, so the answers are accurate and reflect their unique business rules. Depending on the model used, there may also be additional cost for larger context.
Let us look at how the K Nearest Neighbor algorithm can be applied to geospatial analysis. A non-parametric, supervised learning classifier, the K-Nearest Neighbors (k-NN) algorithm uses proximity to classify or predict how a single data point will be grouped. What is K Nearest Neighbor? How can it Be Applied to Geospatial Analysis?
It is fast, scalable, and supports a variety of machine learning algorithms. Faiss is a library for efficient similarity search and clustering of dense vectors. Approximate nearest neighbor search uses specialized data structures and algorithms to speed up the search, but may sacrifice some recall.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, K Nearest Neighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? For example, it takes millions of images and runs them through a training algorithm.
A large language model, referred to as an LLM, is an advanced machine learning algorithm capable of identifying, condensing, translating, predicting, and generating various forms of text and content using extensive datasets. The game-changing technological marvels have got everyone talking and has to be topping the charts in 2023.
Unsupervised learning Unsupervised learning is a type of machine learning where the algorithm tries to find patterns or relationships in the data without the use of labeled data. In other words, the algorithm is not given any information about the correct output or class labels for the input data. Next, you need to select a model.
You’ll also explore centrality metrics, networking density, various layout algorithms, and strategies for interpreting and communicating graph data. Semantic Search Nils Reimers | Director of Machine Learning | cohere.ai or spelling variations/mistakes.
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. And, often, to giving up. Goodbye, Hadoop.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content