This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images. To search against the database, you can use a vector search, which is performed using the k-nearest neighbors (k-NN) algorithm. b64encode(image_file.read()).decode('utf-8')
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
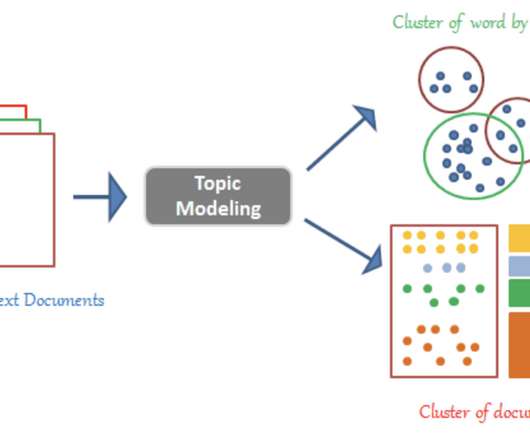
Topic Modeling In this blog, we walk you through the popular Open Source Latent Dirichlet Allocation (LDA) Topic Modeling from conventional algorithms and Watson NLP Topic Modeling. Latent Dirichlet Allocation (LDA) Topic Modeling LDA is a well-known unsupervised clustering method for text analysis.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. The following screenshot shows the top rows of the dataset.
With SageMaker training jobs, you can bring your own algorithm or choose from more than 25 built-in algorithms. SageMaker supports various data sources and access patterns, distributed training including heterogenous clusters, as well as experiment management features and automatic model tuning.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. This allows for a much richer interpretation of predictions, without sacrificing the algorithm’s power.
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. And Why Anomaly Detection?
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. And, often, to giving up. Goodbye, Hadoop.
Amazon SageMaker provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning. 16 1592 1412.2
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. Another way can be to use an AllReduce algorithm.
Mathematics is critical in Data Analysis and algorithm development, allowing you to derive meaningful insights from data. Linear algebra is vital for understanding Machine Learning algorithms and data manipulation. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms.
Rather, it is due to the fact that the algorithms are simply different. According to an expert that we spoke with from Blockport , predictive analytics technology is able to identify the types of modifications that malicious programmers make to their algorithms. This is not due to the complexity of ransomware pertaining to crypto.
Using Colab this can take 2-5 minutes to download and initialize the model. Load HuggingFace open source embeddings models Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically.
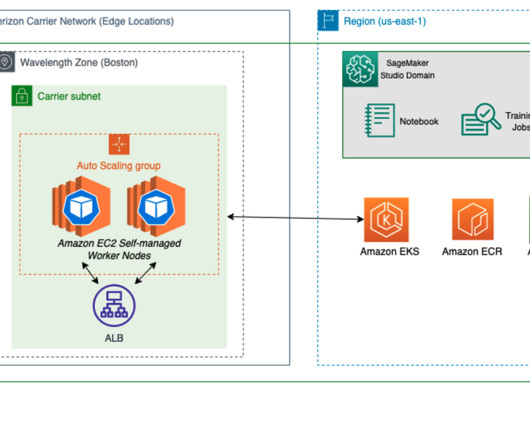
To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. Although AWS offers a number of options for model training—from AWS Marketplace models and SageMaker built-in algorithms—there are a number of techniques to deploy open-source ML models.
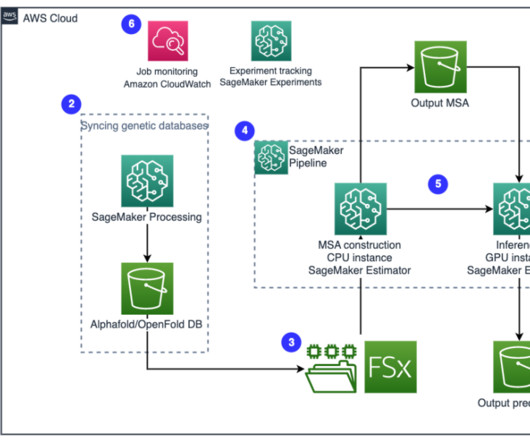
Folding algorithms like AlphaFold2 , ESMFold , OpenFold , and RoseTTAFold can be used to quickly build accurate models of protein structures. Several genetic databases are required to run AlphaFold and OpenFold algorithms, such as BFD , MGnify , PDB70 , PDB , PDB seqres , UniRef30 (FKA UniClust30) , UniProt , and UniRef90.
Using Amazon CloudWatch for anomaly detection Amazon CloudWatch supports creating anomaly detectors on specific Amazon CloudWatch Log Groups by applying statistical and ML algorithms to CloudWatch metrics. Anomalies data for each measure can be downloaded for a detector by using the Amazon Lookout for Metrics APIs for a particular detector.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
To mitigate these risks, the FL model uses personalized training algorithms and effective masking and parameterization before sharing information with the training coordinator. Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking.
The model weights are available to download, inspect and deploy anywhere. Starting June 7th, both Falcon LLMs will also be available in Amazon SageMaker JumpStart, SageMaker’s machine learning (ML) hub that offers pre-trained models, built-in algorithms, and pre-built solution templates to help you quickly get started with ML.
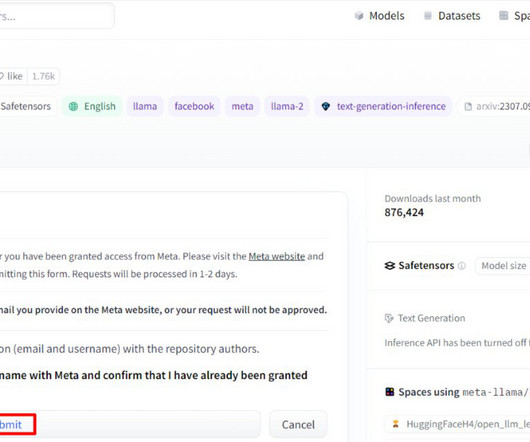
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. You can access the Meta Llama 3.2
Summary: Hash function are essential algorithms that convert input data into fixed-size outputs. A hash function is a mathematical algorithm that transforms input data into a fixed-size string of characters. For example, when downloading files, hash values can verify that the file remains unchanged. What is a Hash Function?
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. By analyzing how users have interacted with items in the past, we can use algorithms to approximate the utility function and make personalized recommendations that users will love.
Using Colab this can take 2-5 minutes to download and initialize the model. LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically.
BERTopic According to the official documentation, BERTopic “is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions”.
Download the Amazon SageMaker FAQs When performing the search, look for Answers only, so you can drop the Question column. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms.
Users can download datasets in formats like CSV and ARFF. The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more. It is a goldmine for students, researchers, and industry professionals, who use it to develop models, benchmark new algorithms, and test hypotheses.
Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deep learning models tend to develop a bias toward the data distribution on which they have been trained. Given an input image , we can run our verification algorithm times for each of the Face IDs in our database.
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. These can then by analyzed by other models (classification, clustering, etc) to produce different analyses. finaleval=outp[1]subset=outp[0]x_subset = subset.drop(columns=["rating"]).to_numpy()y_subset
With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems. Moreover, the library can be downloaded in its entirety from reliable sources such as GitHub at no cost, ensuring its accessibility to a wide range of developers.
Concurrency algorithms are used to ensure that no two users can change the same data at the same time and that all transactions are carried out in the proper order. This helps prevent issues such as double-booking the same hotel room and accidental overdrafts on joint bank accounts.
Therefore, we decided to introduce a deep learning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships. Recommendation model using NCF NCF is an algorithm based on a paper presented at the International World Wide Web Conference in 2017.
Face Recognition One of the most effective Github Projects on Data Science is a Face Recognition project that makes use of Deep Learning and Histogram of Oriented Gradients (HOG) algorithm. You can make use of HOG algorithm for orientation gradients and use Python library for creating and viewing HOG representations.
It involves feeding data to algorithms, which then generalize patterns and make inferences about unseen data. Supervised Learning In supervised learning, the algorithm is trained on a labelled dataset containing input-output pairs. Typical unsupervised learning tasks include clustering (e.g., predicting house prices).
Alternatively, you can directly download the Dockerfile.gpu from GitHub developed by ahmetoner , which includes a pre-configured RESTful API. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms.
This will create all the necessary infrastructure resources needed for this solution: SageMaker endpoints for the LLMs OpenSearch Service cluster API Gateway Lambda function SageMaker Notebook IAM roles Run the data_ingestion_to_vectordb.ipynb notebook in the SageMaker notebook to ingest data from SageMaker docs into an OpenSearch Service index.
You are responsible for reviewing and complying with any applicable license terms and making sure they are acceptable for your use case before downloading or using the content. nnIn 1996, Moret founded the ACM Journal of Experimental Algorithmics, and he remained editor in chief of the journal until 2003.
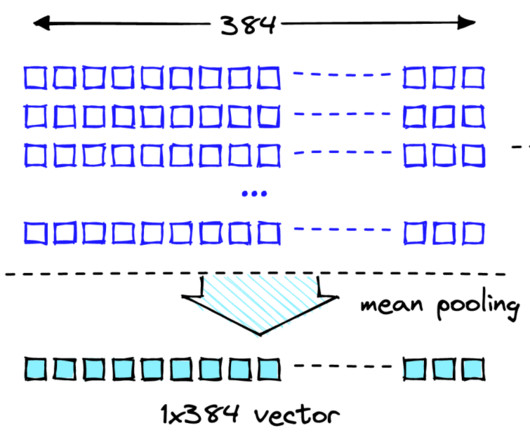
in a 2D space based on the machine learning algorithm used. However, in the real world, the embedding algorithms will generate a vector of hundreds of dimensions (as opposed to 2 dimensions in the above diagram) for any given input text. For example, a vector embedding of the word cat can be = [0.5, -0.4]
First let’s download the test, validate, and train dataset from the source S3 bucket and upload it to our S3 bucket. We choose the top three most downloaded sentence transformer models and use them in the following model fitting and HPO. In addition to HPO, model performance is also dependent on the algorithm. Data exploration.
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deep learning has achieved remarkable success in supervised tasks, especially in image recognition. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
This can be helpful for visualization, data compression, and speeding up other machine learning algorithms. Feature Learning Autoencoders can learn meaningful features from input data, which can be used for downstream machine learning tasks like classification, clustering, or regression. ✓ Access on mobile, laptop, desktop, etc.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content