This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
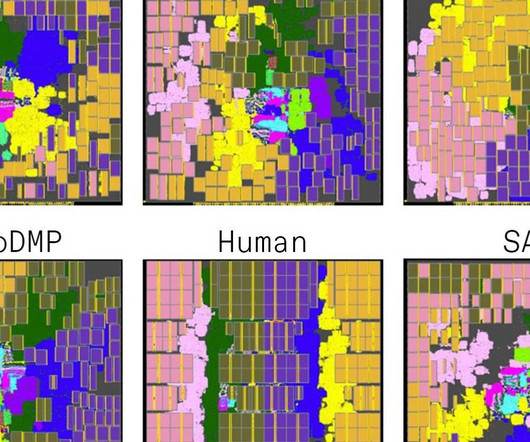
The crux of the clash was whether Google’s AI solution to one of chip design’s thornier problems was really better than humans or state-of-the-art algorithms. It pitted established male EDA experts against two young female Google computer scientists, and the underlying argument had already led to the firing of one Google researcher.
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & The Big Question we need to deal with…!)
Mathematics is critical in Data Analysis and algorithm development, allowing you to derive meaningful insights from data. Linear algebra is vital for understanding Machine Learning algorithms and data manipulation. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms.
Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
Developing predictive models using Machine Learning Algorithms will be a crucial part of your role, enabling you to forecast trends and outcomes. Also Read: Explore data effortlessly with Python Libraries for (Partial) EDA: Unleashing the Power of Data Exploration. The choice impacts the model’s performance and accuracy.
This unstructured nature poses challenges for direct analysis, as sentiments cannot be easily interpreted by traditional machine learning algorithms without proper preprocessing. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Exploratory Data Analysis (EDA): Using statistical summaries and initial visualisations (yes, visualisation plays a role within analysis!) Modeling & Algorithms: Applying statistical models (like regression, classification, clustering) or Machine Learning algorithms to identify deeper patterns, make predictions, or classify data points.
Exploratory Data Analysis (EDA) Exploratory Data Analysis (EDA) is an approach to analyse datasets to uncover patterns, anomalies, or relationships. The primary purpose of EDA is to explore the data without any preconceived notions or hypotheses. Clustering: Grouping similar data points to identify segments within the data.
Face Recognition One of the most effective Github Projects on Data Science is a Face Recognition project that makes use of Deep Learning and Histogram of Oriented Gradients (HOG) algorithm. You can make use of HOG algorithm for orientation gradients and use Python library for creating and viewing HOG representations.
For Data Analysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as Exploratory Data Analysis. First learn the basics of Feature Engineering, and EDA then take some different-different data sheets (data frames) and apply all the techniques you have learned to date.
By conducting exploratory data analysis (EDA), they will identify relationships between these variables and generate insights on how strategy impacts race outcomes. Participants will use EDA and statistical analysis to understand how tire management and pit stop decisions impact race outcomes.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, Machine Learning algorithms, and data manipulation techniques. Differentiate between supervised and unsupervised learning algorithms. Here is a brief description of the same.
This includes skills in data cleaning, preprocessing, transformation, and exploratory data analysis (EDA). Blind 75 LeetCode Questions - LeetCode Discuss Data Manipulation and Analysis Proficiency in working with data is crucial. Familiarity with libraries like pandas, NumPy, and SQL for data handling is important.
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities.
With expertise in Python, machine learning algorithms, and cloud platforms, machine learning engineers optimize models for efficiency, scalability, and maintenance. They possess a deep understanding of statistical methods, programming languages, and machine learning algorithms.
Techniques like regression analysis, time series forecasting, and machine learning algorithms are used to predict customer behavior, sales trends, equipment failure, and more. Kaggle datasets) and use Python’s Pandas library to perform data cleaning, data wrangling, and exploratory data analysis (EDA).
EDA, as it is popularly called, is the pivotal phase of the project where discoveries are made. Team collaboration Its team composition presents a great case wherein they have emphasized building robust data and model pipelines, such as the capacity expansion of prediction clusters, refining codebase, and retraining models.
By analyzing the words and phrases used in a piece of writing, sentiment analysis algorithms can determine the overall sentiment of the text and provide a more complete understanding of its meaning. Now you need to perform some EDA and cleaning on the data after loading it into the notebook.
Solvers submitted a wide range of methodologies to this end, including using open-source and third party LLMs (GPT, LLaMA), clustering (DBSCAN, K-Means), dimensionality reduction (PCA), topic modeling (LDA, BERT), sentence transformers, semantic search, named entity recognition, and more. and DistilBERT. What motivated you to participate? :
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content