This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Explainable AI is no longer just an optional add-on when using MLalgorithms for corporate decision making. While there are a lot of techniques that have been developed for supervised algorithms, […]. The post Adding Explainability to Clustering appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, I’m gonna explain about DBSCAN algorithm. The post Understand The DBSCAN ClusteringAlgorithm! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Agglomerative Clustering using Single Linkage (Source) As we all know, The post Single-Link Hierarchical Clustering Clearly Explained! appeared first on Analytics Vidhya.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. For this post we’ll use a provisioned Amazon Redshift cluster.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
This is why businesses are looking to leverage machine learning (ML). In this article, we will share some best practices for improving your analytics with ML. Top ML approaches to improve your analytics. Clustering. ?lustering They need a more comprehensive analytics strategy to achieve these business goals.
Let’s discuss two popular MLalgorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both MLAlgorithms, and we’ll explore them more in detail in a bit. They are both MLAlgorithms, and we’ll explore them more in detail in a bit.
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
Machine learning is a branch of artificial intelligence that focuses on developing algorithms and models that can learn from data and make predictions or decisions without being explicitly programmed. There are various types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning.
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Hence, developing algorithms with improved efficiency, performance and speed remains a high priority as it empowers services ranging from Search and Ads to Maps and YouTube. You can find other posts in the series here.)
Unsupervised ML: The Basics. Unlike supervised ML, we do not manage the unsupervised model. Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets. As a result, unsupervised MLalgorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes.
cuML brings GPU-acceleration to UMAP and HDBSCAN , in addition to scikit-learn algorithms. It dramatically improves algorithm performance for data-intensive tasks involving tens to hundreds of millions of records. To test drive cuML, try this notebook in Colab, and make sure to select a GPU runtime before getting started.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. We use the Time Series Clustering using TSFresh + KMeans notebook, which is available on our GitHub repo.
That world is not science fiction—it’s the reality of machine learning (ML). In this blog post, we’ll break down the end-to-end ML process in business, guiding you through each stage with examples and insights that make it easy to grasp. Formatting the data in a way that MLalgorithms can understand.
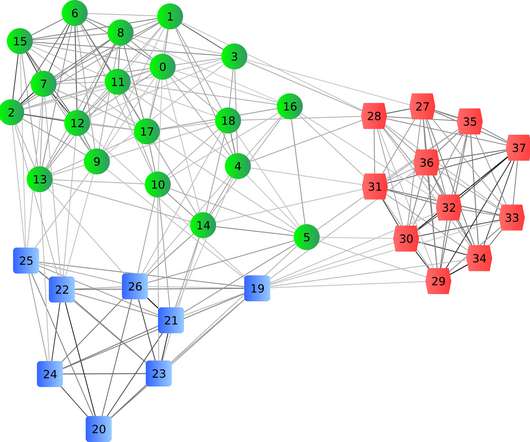
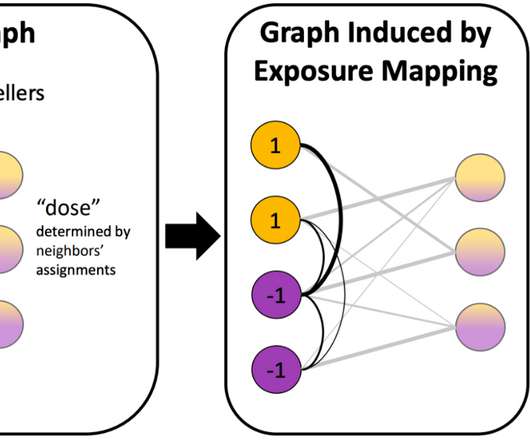
Posted by Vincent Cohen-Addad and Alessandro Epasto, Research Scientists, Google Research, Graph Mining team Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. When clustering is applied to personal data (e.g.,
It usually comprises parsing log data into vectors or machine-understandable tokens, which you can then use to train custom machine learning (ML) algorithms for determining anomalies. You can adjust the inputs or hyperparameters for an MLalgorithm to obtain a combination that yields the best-performing model.
Machine learning (ML) is the technology that automates tasks and provides insights. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It provides a large cluster of clusters on a single machine. It also has MLalgorithms built into the platform.
Featured Community post from the Discord Aman_kumawat_41063 has created a GitHub repository for applying some basic MLalgorithms. It offers pure NumPy implementations of fundamental machine learning algorithms for classification, clustering, preprocessing, and regression. Meme of the week!
The rise of generative AI has significantly increased the complexity of building, training, and deploying machine learning (ML) models. It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters. Builders can use built-in ML tools within SageMaker HyperPod to enhance model performance.
The embedding projector is a powerful visualization tool that helps data scientists and researchers understand complex, high-dimensional data often encountered in machine learning (ML) and natural language processing (NLP). By revealing these clusters, the tool provides important insights that can inform model refinement processes.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The AML feature store standardizes variable definitions using scientifically validated algorithms.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Pyspark MLlib | Classification using Pyspark ML In the previous sections, we discussed about RDD, Dataframes, and Pyspark concepts. In this article, we will discuss about Pyspark MLlib and Spark ML. using PySpark we can run applications parallelly on the distributed cluster… blog.devgenius.io
The Ranking team at Booking.com plays a pivotal role in ensuring that the search and recommendation algorithms are optimized to deliver the best results for their users. Essential ML capabilities such as hyperparameter tuning and model explainability were lacking on premises.
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
Their expertise lies in designing algorithms, optimizing models, and integrating them into real-world applications. They possess a deep understanding of machine learning algorithms, data structures, and programming languages.
These experiences are made possible by our machine learning (ML) backend engine, with ML models built for video understanding, search, recommendation, advertising, and novel visual effects. By using sophisticated MLalgorithms, the platform efficiently scans billions of videos each day.
This involves collecting and analyzing data to identify insights and develop solutions, such as predictive models, visualizations, or machine learning algorithms. Video of the Week: Data-Planning to Implementation Data planning to implementation is the process of using data to develop and deploy a project or initiative.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. This is where ML CoPilot enters the scene. In this paper, the authors suggest the use of LLMs to make use of past ML experiences to suggest solutions for new ML tasks.
Amazon SageMaker is a fully managed machine learning (ML) service providing various tools to build, train, optimize, and deploy ML models. ML insights facilitate decision-making. To assess the risk of credit applications, ML uses various data sources, thereby predicting the risk that a customer will be delinquent.
During the iterative research and development phase, data scientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
You can hear more details in the webinar this article is based on, straight from Kaegan Casey, AI/ML Solutions Architect at Seagate. from local or virtual machine to K8s cluster) and the need for bespoke deployments. from local or virtual machine to K8s cluster) and the need for bespoke deployments.
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification. What is Classification?
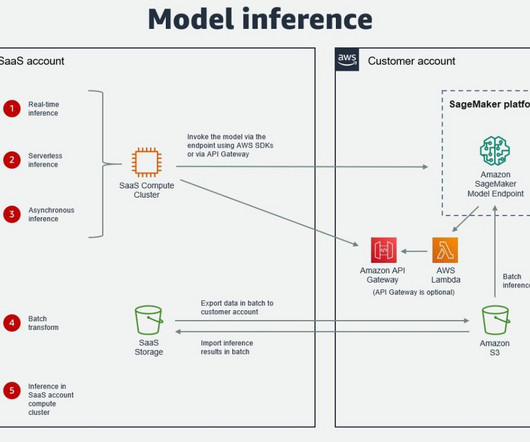
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. There are a few different ways in which authentication across AWS accounts can be achieved when data in the SaaS platform is accessed from SageMaker and when the ML model is invoked from the SaaS platform.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
Their impact on ML tasks has made them a cornerstone of AI advancements. It allows ML models to work with data but in a limited manner. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
By automating repetitive tasks, SuperAcc enhances both operational efficiency and accuracy, using Apoideas self-trained machine learning (ML) models to deliver consistent, high-accuracy results in live production environments. Creating robust ML models is challenging due to the scarcity of clean training data.
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clusteringalgorithm. The other popular clusteringalgorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. It is a cloud-based platform, so it can be accessed from anywhere.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content