This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Cross-validation is a machine learning technique that evaluates a model’s performance on a new dataset. The goal is to develop a model that […] The post Guide to Cross-validation with Julius appeared first on Analytics Vidhya.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. CatBoost is part of the gradient boosting family, alongside well-known algorithms like XGBoost and LightGBM.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithms learn from labeled data , similar to classification.
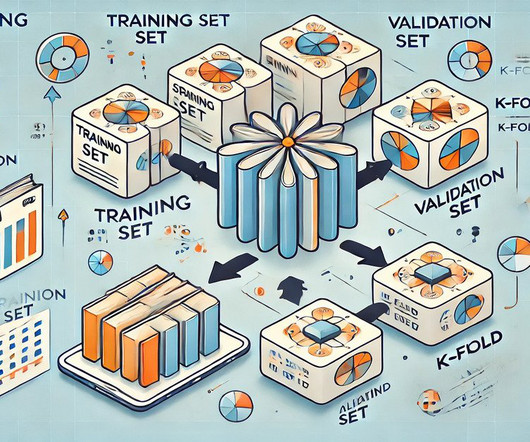
Cross-validation technique Cross-validation is a powerful technique used to ensure robust model validation by leveraging the entire dataset more effectively. This approach ensures that each data point serves both as part of the training set and as part of the validation set.
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Introduction In this article, we will explore the concept of cross-validation in Machine Learning, a crucial technique for assessing model performance and generalisation. billion by 2029.
They enable more accurate model tuning and selection, helping practitioners refine algorithms and choose the best-performing models. Importance of validation sets Model tuning: Validation sets allow data scientists to adjust model parameters and select optimal algorithms effectively.
Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. Figure 11 Model Architecture The algorithms and models used for the first three classifiers are essentially the same. K-Nearest Neighbou r: The k-Nearest Neighbor algorithm has a simple concept behind it.
Machine learning models are algorithms designed to identify patterns and make predictions or decisions based on data. The torchvision package includes datasets and transformations for testing and validating computer vision models. These models are trained using historical data to recognize underlying patterns and relationships.
They dive deep into artificial neural networks, algorithms, and data structures, creating groundbreaking solutions for complex issues. Describe the backpropagation algorithm and its role in neural networks. Backpropagation is an algorithm used to train neural networks. What are some ethical considerations in AI development?
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Unlocking the Power of KNN Algorithm in Machine Learning Machine learning algorithms are significantly impacting diverse fields.
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. The cross-validations for all winners were reproduced by the DrivenData team. Lower is better. Unsurprisingly, the 0.10 quantile was easier to predict than the 0.90
Algorithmic bias can result in unfair outcomes, necessitating careful management. ML algorithms can efficiently identify patterns and trends in large datasets, significantly reducing the time and effort needed for analysis. Key Takeaways Data quality is crucial; poor data leads to unreliable Machine Learning models.
Summary: Support Vector Machine (SVM) is a supervised Machine Learning algorithm used for classification and regression tasks. Among the many algorithms, the SVM algorithm in Machine Learning stands out for its accuracy and effectiveness in classification tasks. What is the SVM Algorithm in Machine Learning?
Using the Categorical Boosting (CatBoost) algorithm with Bayesian optimization for hyperparameter selection and k-fold cross-validation to mitigate overfitting, we analyzed model-feature relationships with SHapley Additive exPlanations (SHAP) values.
He received his PhD in Electrical Engineering from Stanford University, completing a dissertation on the “ Approximate message passing algorithms for compressed sensing.” Prior to his work at Columbia, Arian was a postdoctoral scholar at Rice University. He has taught various calculus and statistics courses from PhD to BSc levels.
It is a popular clustering algorithm used in machine learning and data mining to group points in a dataset that are closely packed together, based on their distance to other points. To understand how the algorithm works, we will walk through a simple example. algorithm: The algorithm used to compute the nearest neighbors of each point.
Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. To avoid leakage during cross-validation, we grouped all plays from the same game into the same fold. For more information on how to use GluonTS SBP, see the following demo notebook.
Indeed, the most robust predictive trading algorithms use machine learning (ML) techniques. On the optimistic side, algorithmically trading assets with predictive ML models can yield enormous gains à la Renaissance Technologies… Yet algorithmic trading gone awry can yield enormous losses as in the latest FTX scandal. Easy peasy.
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. The field of machine learning, known for its algorithmic complexity, has undergone a significant transformation in recent years. Why do you need Python machine learning packages?
The resulting structured data is then used to train a machine learning algorithm. Cross-validation Divide the dataset into smaller batches for large projects and have different annotators work on each batch independently. Then, cross-validate their annotations to identify discrepancies and rectify them.
Unlocking Predictive Power: How Bayes’ Theorem Fuels Naive Bayes Algorithm to Solve Real-World Problems [link] Introduction In the constantly shifting realm of machine learning, we can see that many intricate algorithms are rooted in the fundamental principles of statistics and probability. Take the Naive Bayes algorithm, for example.
We can apply a data-centric approach by using AutoML or coding a custom test harness to evaluate many algorithms (say 20–30) on the dataset and then choose the top performers (perhaps top 3) for further study, being sure to give preference to simpler algorithms (Occam’s Razor).
Then, how to essentially eliminate training, thus speeding up algorithms by several orders of magnitude? My NoGAN algorithm, probably for the first time, comes with the full multivariate KS distance to evaluate results. There are two aspects to this problem of synthesizing data. It is adjusted for dimension.
A brute-force search is a general problem-solving technique and algorithm paradigm. Figure 1: Brute Force Search It is a cross-validation technique. Figure 2: K-fold CrossValidation On the one hand, it is quite simple. Big O notation is a mathematical concept to describe the complexity of algorithms.
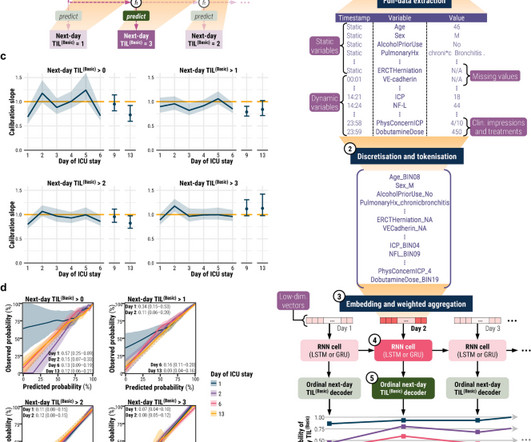
With 20 repeats of fivefold cross-validation, we trained TILTomorrow on different variable sets and applied the TimeSHAP (temporal extension of SHapley Additive exPlanations) algorithm to estimate variable contributions towards predictions of next-day changes in TIL(Basic).
Gradient-boosted trees were popular modeling algorithms among the teams that submitted model reports, including the first- and third-place winners. Final Prize Stage : Refined models are being evaluated once again on historical data but using a more robust cross-validation procedure.
This could involve tuning hyperparameters and combining different algorithms in order to leverage their strengths and come up with a better-performing model. Additionally, I will use StratifiedKFold cross-validation to perform multiple train-test splits.
Using innovative approaches and advanced algorithms, participants modeled scenarios accounting for starting grid positions, driver performance, and unpredictable race conditions like weather changes or mid-race interruptions. Firepig refined predictions using detailed feature engineering and cross-validation.
Team Just4Fun ¶ Qixun Qu Hongwei Fan Place: 2nd Place Prize: $2,000 Hometown: Chengdu, Sichuan, China (Qixun Qu) and Nanjing Jiangsu, China (Hongwei Fan) Username: qqggg , HongweiFan Background: I (qqggg, Qixun Qu in real name) am a vision algorithm developer and focus on image and signal analysis.
Use cross-validation and regularisation to prevent overfitting and pick an appropriate polynomial degree. You can detect and mitigate overfitting by using cross-validation, regularisation, or carefully limiting polynomial degrees. It offers flexibility for capturing complex trends while remaining interpretable.
Several additional approaches were attempted but deprioritized or entirely eliminated from the final workflow due to lack of positive impact on the validation MAE. We chose to compete in this challenge primarily to gain experience in the implementation of machine learning algorithms for data science.
This is in contrast to other parameters, whose values are obtained algorithmically via training. I wished to assess just how much of a performance gain could be had per algorithm by employing a performant tuning method. Moreover, my experience has shown it to be fairly easy to set up.
RFE works effectively with algorithms like Support Vector Machines (SVMs) and linear regression. Embedded Methods Embedded methods integrate feature selection directly into the training process of the Machine Learning algorithm. However, they are model-dependent, which can limit their applicability across different algorithms.
Introduction Hyperparameters in Machine Learning play a crucial role in shaping the behaviour of algorithms and directly influence model performance. Understanding these model-specific hyperparameters helps practitioners focus on the most important settings for a given algorithm.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, Machine Learning algorithms, and data manipulation techniques. Differentiate between supervised and unsupervised learning algorithms.
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. EDA, imputation, encoding, scaling, extraction, outlier handling, and cross-validation ensure robust models. What is Feature Engineering?
Today, as machine learning algorithms continue to shape our world, the integration of Bayesian principles has become a hallmark of advanced predictive modeling. Machine learning algorithms are like tools that help computers learn from data and make informed decisions or predictions. This is where machine learning comes in.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Below, we explore some of the most widely used algorithms in ML.
image from lexica.art Machine learning algorithms can be used to capture gender detection from sound by learning patterns and features in the audio data that are indicative of gender differences. Various algorithms can be employed, such as Support Vector Machines (SVM), Random Forests, Gradient Boosting, or Neural Networks.
This can be done by training machine learning algorithms such as logistic regression, decision trees, random forests, and support vector machines on a dataset containing categorical outputs. This can be done by training continuous data over algorithms like linear regression, logistic regression, random forests, and neural networks.
it’s possible to build a robust image recognition algorithm with high accuracy. Just like for any other project, DataRobot will generate training pipelines and models with validation and cross-validation scores and rate them based on performance metrics. Deep learning makes the process efficient.
Parameters are updated by the learning algorithm during training, based on the training data and optimization algorithm, while hyperparameters are set by the practitioner and are not learned from the data. B) Cross-Validation (CV): CV in “GridSearchCV” stands for Cross-Validation.
K-Nearest Neighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance. To mitigate variance in machine learning, techniques like regularization, cross-validation, early stopping, and using more diverse and balanced datasets can be employed.
Key steps involve problem definition, data preparation, and algorithm selection. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data. Types of Machine Learning Machine Learning algorithms can be categorised based on how they learn and the data type they use.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content