This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. Step-by-Step Guide: Predicting Student Engagement with CatBoost and Cross-Validation 1.
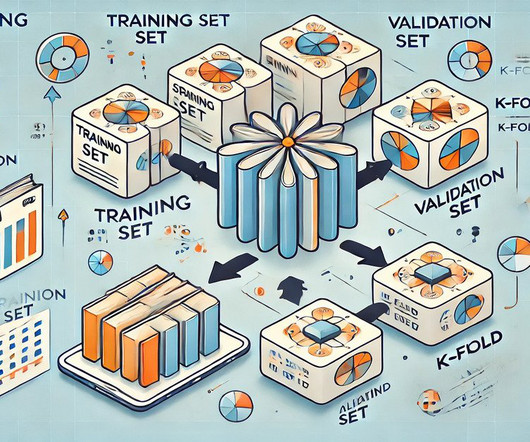
Definition of validation dataset A validation dataset is a separate subset used specifically for tuning a model during development. By evaluating performance on this dataset, datascientists can make informed adjustments to enhance the model without compromising its integrity.
They enable more accurate model tuning and selection, helping practitioners refine algorithms and choose the best-performing models. Importance of validation sets Model tuning: Validation sets allow datascientists to adjust model parameters and select optimal algorithms effectively.
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Various methods, like K-Fold and Stratified K-Fold, cater to different Data Scenarios. Various methods, like K-Fold and Stratified K-Fold, cater to different Data Scenarios.
Machine learning models are algorithms designed to identify patterns and make predictions or decisions based on data. These models are trained using historical data to recognize underlying patterns and relationships. Once trained, they can be used to make predictions on new, unseen data.
By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics. Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
A cheat sheet for DataScientists is a concise reference guide, summarizing key concepts, formulas, and best practices in Data Analysis, statistics, and Machine Learning. It serves as a handy quick-reference tool to assist data professionals in their work, aiding in data interpretation, modeling , and decision-making processes.
Key Takeaways GMM uses multiple Gaussian components to model complex data distributions effectively. EM algorithm iteratively optimizes GMM parameters for best data fit. Soft Clustering Unlike hard clustering algorithms (e.g., This contrasts with algorithms like K-Means that assume spherical clusters of equal size.
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. The cross-validations for all winners were reproduced by the DrivenData team. Lower is better. Unsurprisingly, the 0.10 quantile was easier to predict than the 0.90
DataScientists are highly in demand across different industries for making use of the large volumes of data for analysisng and interpretation and enabling effective decision making. One of the most effective programming languages used by DataScientists is R, that helps them to conduct data analysis and make future predictions.
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Nevertheless, its applications across classification, regression, and anomaly detection tasks highlight its importance in modern data analytics methodologies.
Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. To avoid leakage during cross-validation, we grouped all plays from the same game into the same fold. Marc van Oudheusden is a Senior DataScientist with the Amazon ML Solutions Lab team at Amazon Web Services.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together datascientists to tackle one of the most dynamic aspects of racing — pit stop strategies. Firepig refined predictions using detailed feature engineering and cross-validation.
Datascientists train multiple ML algorithms to examine millions of consumer data records, identify anomalies, and evaluate if a person is eligible for credit. This is a common problem that datascientists face when training their models. About the Authors Tristan Miller is a Lead DataScientist at Best Egg.
Currently pursuing graduate studies at NYU's center for data science. Alejandro Sáez: DataScientist with consulting experience in the banking and energy industries currently pursuing graduate studies at NYU's center for data science. What motivated you to compete in this challenge?
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. Support Vector Machine Support Vector Machine ( SVM ) is a supervised learning algorithm used for classification and regression analysis. What are kernels?
Other data sources were experimented with, and teams expressed that they would continue to experiment with data sources in the following competition stages. Gradient-boosted trees were popular modeling algorithms among the teams that submitted model reports, including the first- and third-place winners.
This could involve tuning hyperparameters and combining different algorithms in order to leverage their strengths and come up with a better-performing model. Model Extraction and Registration For the first version, I want to fit a KNeighborsClassifier to fit the data. We pay our contributors, and we don’t sell ads.
Team Just4Fun ¶ Qixun Qu Hongwei Fan Place: 2nd Place Prize: $2,000 Hometown: Chengdu, Sichuan, China (Qixun Qu) and Nanjing Jiangsu, China (Hongwei Fan) Username: qqggg , HongweiFan Background: I (qqggg, Qixun Qu in real name) am a vision algorithm developer and focus on image and signal analysis.
Revolutionizing Healthcare through Data Science and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machine learning, and information technology.
MLOps emphasizes the need for continuous integration and continuous deployment (CI/CD) in the ML workflow, ensuring that models are updated in real-time to reflect changes in data or ML algorithms. Collaboration tools within the team to share and manage data sources effectively.
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory Data Analysis , imputation, and outlier handling, robust models are crafted. Time features Objective: Extracting valuable information from time-related data.
RFE works effectively with algorithms like Support Vector Machines (SVMs) and linear regression. Embedded Methods Embedded methods integrate feature selection directly into the training process of the Machine Learning algorithm. However, they are model-dependent, which can limit their applicability across different algorithms.
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. Differentiate between supervised and unsupervised learning algorithms.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
The results of this GCMS challenge could not only support NASA scientists to more quickly analyze data, but is also a proof-of-concept of the use of data science and machine learning techniques on complex GCMS data for future missions. This motivated me to use weight averaging which stabilized validation loss.
Democratizing Machine Learning Machine learning entails a complex series of steps, including data preprocessing, feature engineering, algorithm selection, hyperparameter tuning, and model evaluation. AutoML leverages the power of artificial intelligence and machine learning algorithms to automate the machine learning pipeline.
Summary: Machine Learning Engineer design algorithms and models to enable systems to learn from data. A Machine Learning Engineer plays a crucial role in this landscape, designing and implementing algorithms that drive innovation and efficiency. In finance, they build models for risk assessment or algorithmic trading.
Were using Bayesian optimization for hyperparameter tuning and cross-validation to reduce overfitting. The data set contains features like opportunity name, opportunity details, needs, associated product name, product details, product groups. This helps make sure that the clustering is accurate and relevant.
Sometimes this is a good thing as it may be beneficial to the outcome that a datascientist or machine learning practitioner may desire. So I will pick the MLPClassifier algorithm for the next model. Picking either of them could allow for a better-performing model in comparison to the one that we had in the previous article.
Understanding these concepts is paramount for any datascientist, machine learning engineer, or researcher striving to build robust and accurate models. K-Nearest Neighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance.
In the Kelp Wanted challenge, participants were called upon to develop algorithms to help map and monitor kelp forests. The challenge supplied Landsat satellite imagery and labels generated by citizen scientists as part of the Floating Forests project. Above: Overhead drone footage of giant kelp canopy.
programs offer comprehensive Data Analysis and Statistical methods training, providing a solid foundation for Statisticians and DataScientists. It emphasises probabilistic modeling and Statistical inference for analysing big data and extracting information. You will learn by practising DataScientists.
Key steps involve problem definition, data preparation, and algorithm selection. Data quality significantly impacts model performance. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data.
Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Importance of Data in AI Quality data is the lifeblood of AI models, directly influencing their performance and reliability.
Summary: XGBoost is a highly efficient and scalable Machine Learning algorithm. It combines gradient boosting with features like regularisation, parallel processing, and missing data handling. Key Features of XGBoost XGBoost (eXtreme Gradient Boosting) has earned its reputation as a powerful and efficient Machine Learning algorithm.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Data science has become an integral part of many industries, and as a result, the demand for skilled datascientists is soaring. What is Data Science? It further performs badly on the test data set.
Data Science is the art and science of extracting valuable information from data. It encompasses data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and insights that can drive decision-making and innovation.
Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among datascientists, DevOps engineers, and IT teams. Autonomous Vehicles: Automotive companies are using ML models for autonomous driving systems including object detection, path planning, and decision-making algorithms.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. Advanced algorithms recognize patterns in temporal data effectively. These tools empower analysts and datascientists to create sophisticated models efficiently.
Selection of Recommender System Algorithms: When selecting recommender system algorithms for comparative study, it's crucial to incorporate various methods encompassing different recommendation approaches. This diversity ensures a comprehensive understanding of each algorithm's performance under various scenarios.
Statistical Analysis Introducing statistical methods and techniques for analysing data, including hypothesis testing, regression analysis, and descriptive statistics. Students should gain a foundational understanding of statistics as it applies to data analytics. Students should learn how to apply machine learning models to Big Data.
Introduction The French Fiscal AI Innovation and Prediction Challenge invited datascientists from around the globe to analyze an extensive dataset encompassing 40 years of French tax information. Datascientists retain their intellectual property rights while we offer assistance in monetizing their creations.
This deployed hyperparameters tuning and cross-validation to ensure an effective and generalizable model. Include details such as the choice of algorithms, feature engineering techniques, model training methodology, and any considerations for handling potential challenges, such as data imbalance or overfitting.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content