This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By understanding machine learningalgorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithmslearn from labeled data , similar to classification.
Signs of overfitting Common signs of overfitting include a significant disparity between training and validation performance metrics. If a model achieves high accuracy on the training set but poor performance on a validation set, it likely indicates overfitting.
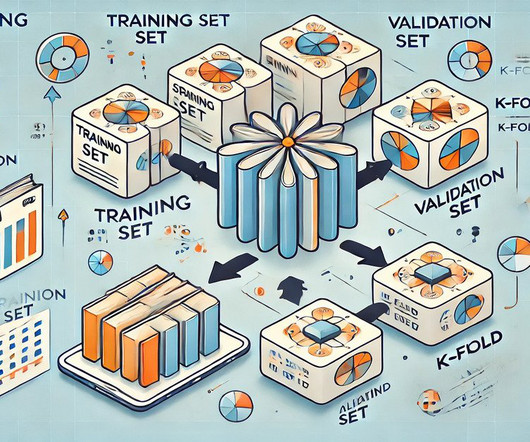
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Introduction In this article, we will explore the concept of cross-validation in Machine Learning, a crucial technique for assessing model performance and generalisation.
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learningalgorithms. These libraries, with their rich functionalities and comprehensive toolsets, have become the backbone of data science and machine learning practices.
Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. Figure 11 Model Architecture The algorithms and models used for the first three classifiers are essentially the same. K-Nearest Neighbou r: The k-Nearest Neighbor algorithm has a simple concept behind it.
The resulting structured data is then used to train a machine learningalgorithm. There are a lot of image annotation techniques that can make the process more efficient with deeplearning. Then, cross-validate their annotations to identify discrepancies and rectify them.
Image recognition is one of the most relevant areas of machine learning. Deeplearning makes the process efficient. it’s possible to build a robust image recognition algorithm with high accuracy. We embedded best practices and various deeplearning models to support image data. DataRobot Visual AI.
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. The SVM algorithm requires the tuning of several parameters to achieve optimal performance.
I am involved in an educational program where I teach machine and deeplearning courses. Machine learning is my passion and I often take part in competitions. Before my PhD, I completed a Masters degree in biomedical engineering at Tsinghua University and worked as an algorithm engineer at SenseTime.
In the Kelp Wanted challenge, participants were called upon to develop algorithms to help map and monitor kelp forests. Winning algorithms will not only advance scientific understanding, but also equip kelp forest managers and policymakers with vital tools to safeguard these vulnerable and vital ecosystems.
This could involve tuning hyperparameters and combining different algorithms in order to leverage their strengths and come up with a better-performing model. Additionally, I will use StratifiedKFold cross-validation to perform multiple train-test splits. We pay our contributors, and we don’t sell ads.
In this tutorial, you will learn the magic behind the critically acclaimed algorithm: XGBoost. But all of these algorithms, despite having a strong mathematical foundation, have some flaws or the other. The goal is to nullify the abstraction created by packages as much as possible. What Is XGBoost?
As with any research dataset like this one, initial algorithms may pick up on correlations that are incidental to the task. The third-place winner combined both feature engineering and neural network feature learning. All winners who used deeplearning fine-tuned pre-trained models.
Today, as machine learningalgorithms continue to shape our world, the integration of Bayesian principles has become a hallmark of advanced predictive modeling. This is where machine learning comes in. Machine learningalgorithms are like tools that help computers learn from data and make informed decisions or predictions.
Several additional approaches were attempted but deprioritized or entirely eliminated from the final workflow due to lack of positive impact on the validation MAE. Her primary interests lie in theoretical machine learning. She currently does research involving interpretability methods for biological deeplearning models.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learningalgorithms and effective data handling are also critical for success in the field.
AI-generated image ( craiyon ) In machine learning (ML), a hyperparameter is a parameter whose value is given by the user and used to control the learning process. This is in contrast to other parameters, whose values are obtained algorithmically via training. Optuna has many uses, both in machine learning and in deeplearning.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
This summary explores hyperparameter categories, tuning techniques, and tools, emphasising their significance in the growing Machine Learning landscape. Introduction Hyperparameters in Machine Learning play a crucial role in shaping the behaviour of algorithms and directly influence model performance.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, Machine Learningalgorithms, and data manipulation techniques. Differentiate between supervised and unsupervised learningalgorithms.
For example, if you are using regularization such as L2 regularization or dropout with your deeplearning model that performs well on your hold-out-cross-validation set, then increasing the model size won’t hurt performance, it will stay the same or improve. The only drawback of using a bigger model is computational cost.
MLOps emphasizes the need for continuous integration and continuous deployment (CI/CD) in the ML workflow, ensuring that models are updated in real-time to reflect changes in data or ML algorithms. Examples include: Cross-validation techniques for better model evaluation.
The Role of Data Scientists and ML Engineers in Health Informatics At the heart of the Age of Health Informatics are data scientists and ML engineers who play a critical role in harnessing the power of data and developing intelligent algorithms.
K-Nearest Neighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance. To mitigate variance in machine learning, techniques like regularization, cross-validation, early stopping, and using more diverse and balanced datasets can be employed.
Key Takeaways Machine Learning Models are vital for modern technology applications. Types include supervised, unsupervised, and reinforcement learning. Key steps involve problem definition, data preparation, and algorithm selection. Ethical considerations are crucial in developing fair Machine Learning solutions.
So I will pick the MLPClassifier algorithm for the next model. So we will write our code as follows: #our new better performing algorithm model1 = MLPClassifier(max_iter=1000, random_state = 0) #fitting model model1.fit(X, Have you tried Comet? fit(X, y) #exporting model to desired location dump(model1, "model1.joblib")
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science?
These reference guides condense complex concepts, algorithms, and commands into easy-to-understand formats. Expertise in mathematics and statistical fields is essential for deciding algorithms, drawing conclusions, and making predictions. Machine Learning Machine learning is at the heart of Data Science.
Selection of Recommender System Algorithms: When selecting recommender system algorithms for comparative study, it's crucial to incorporate various methods encompassing different recommendation approaches. This diversity ensures a comprehensive understanding of each algorithm's performance under various scenarios.
Summary: XGBoost is a highly efficient and scalable Machine Learningalgorithm. Key Features of XGBoost XGBoost (eXtreme Gradient Boosting) has earned its reputation as a powerful and efficient Machine Learningalgorithm. XGBoost excels in finance, healthcare, marketing, and fraud detection.
What Is the Difference Between Artificial Intelligence, Machine Learning, And DeepLearning? Artificial Intelligence (AI) is a broad field that encompasses the development of systems capable of performing tasks that typically require human intelligence, such as learning, problem-solving, and decision-making.
List of Python Libraries and Their Uses Given below are the Python Libraries that can be identified to be important working Python Libraries used by programmers in the industry: TensorFlow It is a computational library useful for writing new algorithms involving large number of tensor operations.
By extracting key features, you allow the Machine Learningalgorithm to focus on the most critical aspects of the data, leading to better generalisation. Numerical Features (Continuous vs. Discrete) Numerical features represent data quantitatively, making them the most straightforward for Machine Learningalgorithms to process.
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. And with machine learning, time series forecasting becomes faster, more precise, and more efficient in the long run.
BERT model architecture; image from TDS Hyperparameter tuning Hyperparameter tuning is the process of selecting the optimal hyperparameters for a machine learningalgorithm. Batch size and learning rate are two important hyperparameters that can significantly affect the training of deeplearning models, including LLMs.
Summary: Machine Learning Engineer design algorithms and models to enable systems to learn from data. Introduction Machine Learning is rapidly transforming industries. A Machine Learning Engineer plays a crucial role in this landscape, designing and implementing algorithms that drive innovation and efficiency.
Use the crossvalidation technique to provide a more accurate estimate of the generalization error. This phenomenon was observed through some algorithms such as linear regression and neural networks [4] and remains an active area of research in the field of Machine Learning/DeepLearning.
Machine LearningAlgorithms Basic understanding of Machine Learning concepts and algorithm s, including supervised and unsupervised learning techniques. Students should learn how to apply machine learning models to Big Data. Students should learn how to train and evaluate models using large datasets.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. Advanced algorithms recognize patterns in temporal data effectively. Key Takeaways AI automates complex forecasting processes for improved efficiency.
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities.
Moving the machine learning models to production is tough, especially the larger deeplearning models as it involves a lot of processes starting from data ingestion to deployment and monitoring. It provides different features for building as well as deploying various deeplearning-based solutions. What is MLOps?
Originally used in Data Mining, clustering can also serve as a crucial preprocessing step in various Machine Learningalgorithms. By applying clustering algorithms, distinct clusters or groups can be automatically identified within a dataset. The optimal value for K can be found using ideas like CrossValidation (CV).
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. We perform a five-fold cross-validation to select the best model during training, and perform hyperparameter optimization to select the best settings on multiple model architecture and training parameters.
Learning about perceptrons is important for building a foundation in neural network concepts and understanding the potential of more advanced models for solving complex problems. Read More Linear Regression from Scratch with Gradient Descent Smart Aspects of CatBoost Algorithm How Fast Is Your Light GBM?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content