This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Cross-validation is a machinelearning technique that evaluates a model’s performance on a new dataset. This prevents overfitting by encouraging the model to learn underlying trends associated with the data.
This story explores CatBoost, a powerful machine-learningalgorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. Step-by-Step Guide: Predicting Student Engagement with CatBoost and Cross-Validation 1.
By understanding machinelearningalgorithms, you can appreciate the power of this technology and how it’s changing the world around you! Regression Regression, much like predicting how much popcorn you need for movie night, is a cornerstone of machinelearning. an image might contain both a cat and a dog).
Overfitting in machinelearning is a common challenge that can significantly impact a model’s performance. What is overfitting in machinelearning? The model essentially memorizes the training data rather than learning to generalize from it.
Machinelearning models are algorithms designed to identify patterns and make predictions or decisions based on data. Modern businesses are embracing machinelearning (ML) models to gain a competitive edge. What is MachineLearning Model Testing?
Sign in Sign out Contributor Portal Latest Editor’s Picks Deep Dives Contribute Newsletter Toggle Mobile Navigation LinkedIn X Toggle Search Search Data Science How I Automated My MachineLearning Workflow with Just 10 Lines of Python Use LazyPredict and PyCaret to skip the grunt work and jump straight to performance.
Grid search is a powerful technique that plays a crucial role in optimizing machinelearning models. By systematically exploring a set range of hyperparameters, grid search enables data scientists and machinelearning practitioners to significantly enhance the performance of their algorithms.
Model selection in machinelearning is a pivotal aspect that shapes the trajectory of AI projects. What is model selection in machinelearning? Importance of model selection Effective model selection is crucial in the machinelearning lifecycle for several reasons.
The bias-variance tradeoff is essential in machinelearning, impacting how accurately models predict outcomes. Each machinelearning model faces the challenge of effectively capturing data patterns while avoiding errors that stem from both bias and variance. What is bias-variance tradeoff? What is underfitting?
Summary: MachineLearning’s key features include automation, which reduces human involvement, and scalability, which handles massive data. Introduction: The Reality of MachineLearning Consider a healthcare organisation that implemented a MachineLearning model to predict patient outcomes based on historical data.
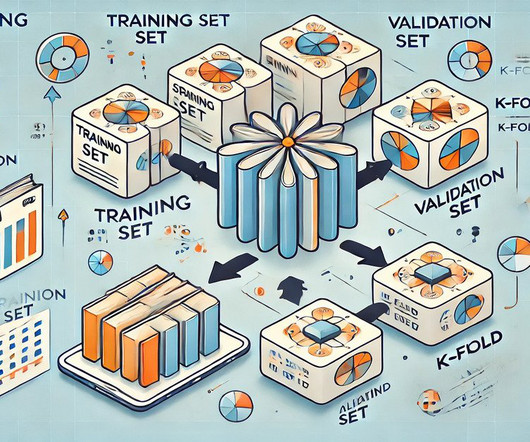
Validation set plays a pivotal role in the model training process for machinelearning. It serves as a safeguard, ensuring that models not only learn from the data they are trained on but are also able to generalize effectively to unseen examples. What is a validation set? What is a validation set?
Summary: Cross-validation in MachineLearning is vital for evaluating model performance and ensuring generalisation to unseen data. Introduction In this article, we will explore the concept of cross-validation in MachineLearning, a crucial technique for assessing model performance and generalisation.
Business Benefits: Organizations are recognizing the value of AI and data science in improving decision-making, enhancing customer experiences, and gaining a competitive edge An AI research scientist acts as a visionary, bridging the gap between human intelligence and machine capabilities. Privacy: Protecting user privacy and data security.
Why is RMSE important in machinelearning? In the realm of machinelearning, RMSE serves a crucial role in assessing the effectiveness of predictive algorithms. Artificial intelligence: Evaluates the performance of algorithms in predicting outcomes and behaviors.
Python machinelearning packages have emerged as the go-to choice for implementing and working with machinelearningalgorithms. These libraries, with their rich functionalities and comprehensive toolsets, have become the backbone of data science and machinelearning practices.
Ground truth is a fundamental concept in machinelearning, representing the accurate, labeled data that serves as a crucial reference point for training and validating predictive models. What is ground truth in machinelearning? Clarifying these aspects forms the foundation for the dataset’s design.
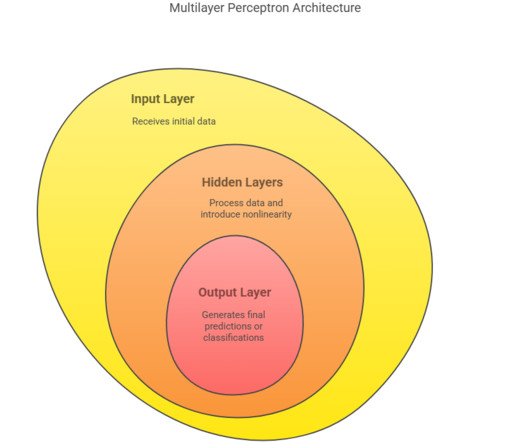
Summary: Multilayer Perceptron in machinelearning (MLP) is a powerful neural network model used for solving complex problems through multiple layers of neurons and nonlinear activation functions. mean squared error for regression, cross-entropy for classification).
Model behavior in machinelearning is a multifaceted concept that encapsulates how predictive models make decisions based on the data they process. Understanding model behavior not only sharpens our grasp of machinelearning systems but also illuminates the challenges and opportunities tied to predictive accuracy.
MLOps emphasizes the need for continuous integration and continuous deployment (CI/CD) in the ML workflow, ensuring that models are updated in real-time to reflect changes in data or ML algorithms. Examples include: Cross-validation techniques for better model evaluation.
ML model parameters significantly impact how algorithms interpret data, ultimately influencing the quality of predictions. This exploration delves into the essential aspects of ML model parameters and associated concepts, revealing their role in effective machinelearning. What are ML model parameters?
Today, as machinelearningalgorithms continue to shape our world, the integration of Bayesian principles has become a hallmark of advanced predictive modeling. This is where machinelearning comes in. What is machinelearning? Machinelearningalgorithms help you find patterns in this data.
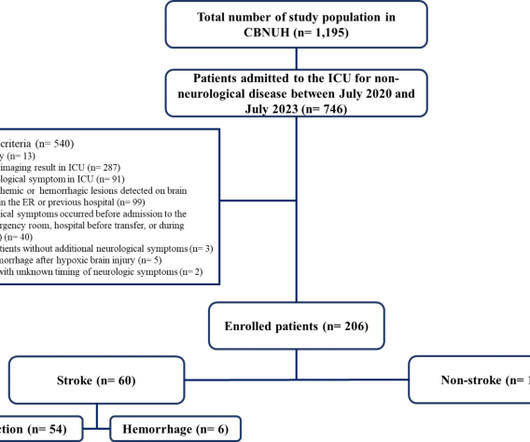
Therefore, we developed a machinelearning model to diagnose stroke in patients with acute neurological manifestations in the ICU. Internal model validation yielded an average accuracy of 0.7560, sensitivity of 0.8959, specificity of 0.7000, and area under the receiver operating characteristic curve (AUROC) of 0.8201.
By leveraging statistical techniques and machinelearning, organizations can forecast future trends based on historical data. Through various statistical methods and machinelearningalgorithms, predictive modeling transforms complex datasets into understandable forecasts.
Summary: The KNN algorithm in machinelearning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Unlocking the Power of KNN Algorithm in MachineLearningMachinelearningalgorithms are significantly impacting diverse fields.
The Gaussian process for machinelearning can be considered as an intellectual cornerstone, wielding the power to decipher intricate patterns within data and encapsulate the ever-present shroud of uncertainty. At its core, machinelearning endeavors to extract knowledge from data to illuminate the path forward.
Summary: Support Vector Machine (SVM) is a supervised MachineLearningalgorithm used for classification and regression tasks. Introduction MachineLearning has revolutionised various industries by enabling systems to learn from data and make informed decisions.
Scikit-learn stands out as a prominent Python library in the machinelearning realm, providing a versatile toolkit for data scientists and enthusiasts alike. Its comprehensive functionality caters to various tasks, making it a go-to resource for both simple and complex machinelearning projects.
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. The cross-validations for all winners were reproduced by the DrivenData team. Lower is better. Unsurprisingly, the 0.10 quantile was easier to predict than the 0.90
Currently an associate professor in the Department of Statistics at Columbia University, Arian’s research interests include high-dimensional statistics, computational imaging, compressed sensing, and machinelearning. Prior to his work at Columbia, Arian was a postdoctoral scholar at Rice University.
The NAS is investing in new ways to bring vast amounts of data together with state-of-the-art machinelearning to improve air travel for everyone. Federated learning is a technique for collaboratively training a shared machinelearning model across data from multiple parties while preserving each party's data privacy.
Summary: Hyperparameters in MachineLearning are essential for optimising model performance. They are set before training and influence learning rate and batch size. This summary explores hyperparameter categories, tuning techniques, and tools, emphasising their significance in the growing MachineLearning landscape.
Summary : Feature selection in MachineLearning identifies and prioritises relevant features to improve model accuracy, reduce overfitting, and enhance computational efficiency. Introduction Feature selection in MachineLearning is identifying and selecting the most relevant features from a dataset to build efficient predictive models.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Feature engineering in machinelearning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Embrace the benefits of feature engineering to unlock the full potential of your Machine-Learning endeavors and achieve accurate predictions in diverse real-world scenarios.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearningalgorithms and effective data handling are also critical for success in the field.
AI-generated image ( craiyon ) In machinelearning (ML), a hyperparameter is a parameter whose value is given by the user and used to control the learning process. This is in contrast to other parameters, whose values are obtained algorithmically via training.
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. The SVM algorithm requires the tuning of several parameters to achieve optimal performance.
In recent years, the field of machinelearning has gained tremendous momentum, offering powerful solutions and valuable insights from vast amounts of data. However, the process of building machinelearning models traditionally involved a time-consuming and resource-intensive approach, requiring extensive expertise.
Figure 1 Preprocessing Data preprocessing is an essential step in building a MachineLearning model. Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. For many classification applications, random forest is now one of the best-performing algorithms.
Summary: MachineLearning Engineer design algorithms and models to enable systems to learn from data. Introduction MachineLearning is rapidly transforming industries. Who is a MachineLearning Engineer? They ensure that MachineLearning solutions are accurate, scalable, and maintainable.
image from lexica.art Machinelearningalgorithms can be used to capture gender detection from sound by learning patterns and features in the audio data that are indicative of gender differences. Training a MachineLearning Model : The preprocessed features are used to train a machinelearning model.
The concepts of bias and variance in MachineLearning are two crucial aspects in the realm of statistical modelling and machinelearning. Understanding these concepts is paramount for any data scientist, machinelearning engineer, or researcher striving to build robust and accurate models.
Summary: Feature extraction in MachineLearning is essential for transforming raw data into meaningful features that enhance model performance. Introduction MachineLearning has become a cornerstone in transforming industries worldwide. The global market was valued at USD 36.73 from 2023 to 2030.
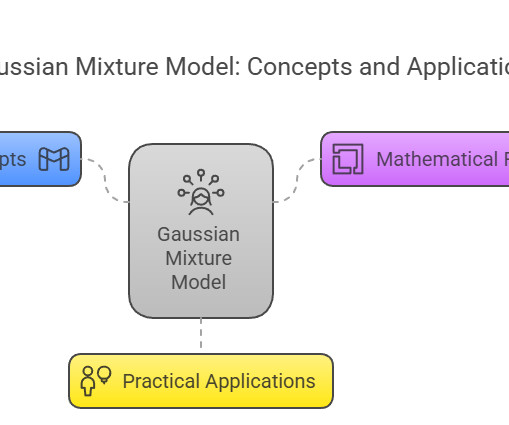
Introduction The Gaussian Mixture Model (GMM) stands as one of the most powerful and flexible tools in the field of unsupervised MachineLearning and statistics. EM algorithm iteratively optimizes GMM parameters for best data fit. Soft Clustering Unlike hard clustering algorithms (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content