This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. CatBoost is part of the gradient boosting family, alongside well-known algorithms like XGBoost and LightGBM.
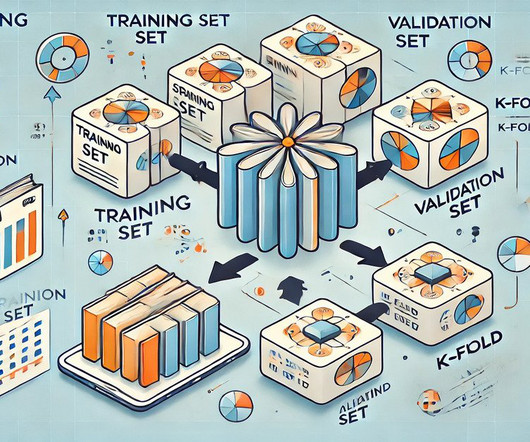
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Introduction In this article, we will explore the concept of cross-validation in Machine Learning, a crucial technique for assessing model performance and generalisation. billion by 2029.
They dive deep into artificial neural networks, algorithms, and data structures, creating groundbreaking solutions for complex issues. Describe the backpropagation algorithm and its role in neural networks. Backpropagation is an algorithm used to train neural networks. What are some ethical considerations in AI development?
Machine learning models are algorithms designed to identify patterns and make predictions or decisions based on data. The torchvision package includes datasets and transformations for testing and validating computer vision models. These models are trained using historical data to recognize underlying patterns and relationships.
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. Acquiring proficiency in Python has become essential for individuals aiming to excel in these domains. Gone are the days when developers had to painstakingly code every algorithm from scratch.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Unlocking the Power of KNN Algorithm in Machine Learning Machine learning algorithms are significantly impacting diverse fields.
Introduction One of the most widely used and highly popular programming languages in the technological world is Python. Significantly, despite being user-friendly and easy to learn, one of Python’s many advantages is that it has large collection of libraries. What is a Python Library? What version of Python are you using?
It is a popular clustering algorithm used in machine learning and data mining to group points in a dataset that are closely packed together, based on their distance to other points. To understand how the algorithm works, we will walk through a simple example. Python Implementation We can use DBSCAN class from sklearn.
Summary: Support Vector Machine (SVM) is a supervised Machine Learning algorithm used for classification and regression tasks. Among the many algorithms, the SVM algorithm in Machine Learning stands out for its accuracy and effectiveness in classification tasks. What is the SVM Algorithm in Machine Learning?
Indeed, the most robust predictive trading algorithms use machine learning (ML) techniques. On the optimistic side, algorithmically trading assets with predictive ML models can yield enormous gains à la Renaissance Technologies… Yet algorithmic trading gone awry can yield enormous losses as in the latest FTX scandal. Easy peasy.
GluonTS is a Python package for probabilistic time series modeling, but the SBP distribution is not specific to time series, and we were able to repurpose it for regression. Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. We used the SBP distribution provided by GluonTS.
A brute-force search is a general problem-solving technique and algorithm paradigm. Figure 1: Brute Force Search It is a cross-validation technique. Figure 2: K-fold CrossValidation On the one hand, it is quite simple. Big O notation is a mathematical concept to describe the complexity of algorithms.
Perceptron Implementation in Python: Understanding the Basics of Artificial Neural Networks Photo by Jeremy Perkins on Unsplash Perceptron is the most basic unit of an artificial neural network. Python Let’s code a perceptron in Python. It takes several inputs and outputs a single binary decision. A Perceptron.
This could involve tuning hyperparameters and combining different algorithms in order to leverage their strengths and come up with a better-performing model. Additionally, I will use StratifiedKFold cross-validation to perform multiple train-test splits.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. during the forecast period.
Use cross-validation and regularisation to prevent overfitting and pick an appropriate polynomial degree. You can detect and mitigate overfitting by using cross-validation, regularisation, or carefully limiting polynomial degrees. It offers flexibility for capturing complex trends while remaining interpretable.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, Machine Learning algorithms, and data manipulation techniques. Differentiate between supervised and unsupervised learning algorithms.
MLOps emphasizes the need for continuous integration and continuous deployment (CI/CD) in the ML workflow, ensuring that models are updated in real-time to reflect changes in data or ML algorithms. Examples include: Cross-validation techniques for better model evaluation.
These reference guides condense complex concepts, algorithms, and commands into easy-to-understand formats. Data Scientists use a wide range of tools and programming languages such as Python and R to extract meaningful patterns and trends from data. Let’s delve into the world of cheat sheets and understand their importance.
Key steps involve problem definition, data preparation, and algorithm selection. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data. Types of Machine Learning Machine Learning algorithms can be categorised based on how they learn and the data type they use.
Summary: XGBoost is a highly efficient and scalable Machine Learning algorithm. Key Features of XGBoost XGBoost (eXtreme Gradient Boosting) has earned its reputation as a powerful and efficient Machine Learning algorithm. It combines gradient boosting with features like regularisation, parallel processing, and missing data handling.
Algorithms like AdaBoost, XGBoost, and LightGBM power real-world finance, healthcare, and NLP applications. This blog explores how Boosting works and its popular algorithms. Popular Boosting algorithms include AdaBoost, Gradient Boosting, XGBoost, LightGBM, and CatBoost. Lets explore some of the most popular ones.
This allows scientists and model developers to focus on model development and rapid experimentation rather than infrastructure management Pipelines offers the ability to orchestrate complex ML workflows with a simple Python SDK with the ability to visualize those workflows through SageMaker Studio. tag = "latest" container_image_uri = "{0}.dkr.ecr.{1}.amazonaws.com/{2}:{3}".format(account_id,
Summary: Machine Learning Engineer design algorithms and models to enable systems to learn from data. A Machine Learning Engineer plays a crucial role in this landscape, designing and implementing algorithms that drive innovation and efficiency. In finance, they build models for risk assessment or algorithmic trading.
In this tutorial, you will learn the magic behind the critically acclaimed algorithm: XGBoost. But all of these algorithms, despite having a strong mathematical foundation, have some flaws or the other. The goal is to nullify the abstraction created by packages as much as possible. What Is XGBoost?
For example, if you are using regularization such as L2 regularization or dropout with your deep learning model that performs well on your hold-out-cross-validation set, then increasing the model size won’t hurt performance, it will stay the same or improve. The only drawback of using a bigger model is computational cost.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science?
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. Cross-Validation: A model evaluation technique that assesses how well a model will generalise to an independent dataset.
Selection of Recommender System Algorithms: When selecting recommender system algorithms for comparative study, it's crucial to incorporate various methods encompassing different recommendation approaches. This diversity ensures a comprehensive understanding of each algorithm's performance under various scenarios.
The curriculum includes Machine Learning Algorithms and prepares students for roles like Data Scientist, Data Analyst, System Analyst, and Intelligence Analyst. Gain insights using scientific methods and algorithms. It emphasises probabilistic modeling and Statistical inference for analysing big data and extracting information.
Apache Spark A fast, in-memory data processing engine that provides support for various programming languages, including Python, Java, and Scala. Machine Learning Algorithms Basic understanding of Machine Learning concepts and algorithm s, including supervised and unsupervised learning techniques.
For our Python example, we’ll use the famous Iris dataset from scikit-learn, which includes measurements of iris flowers and their species. Solution : Implement pruning techniques to limit the depth of the tree, and use cross-validation to ensure the model generalizes well to unseen data.
Techniques such as cross-validation, regularisation , and feature selection can prevent overfitting. Then, I would explore forecasting models such as ARIMA, exponential smoothing, or machine learning algorithms like random forests or gradient boosting to predict future sales. How do you handle large datasets in Python?
You can use techniques like grid search, cross-validation, or optimization algorithms to find the best parameter values that minimize the forecast error. It’s important to consider the specific characteristics of your data and the goals of your forecasting project when configuring the model.
In particular, my code is based on rospy, which, as you might guess, is a python package allowing you to write code to interact with ROS. Control algorithm. To this end, the filter also provides a second orientation, computed with a gradient descent algorithm applied to accelerometer data. The formula of the SHOE detector.
Autonomous Vehicles: Automotive companies are using ML models for autonomous driving systems including object detection, path planning, and decision-making algorithms. MLOps ensures the reliability and safety of these models through rigorous testing, validation, and continuous monitoring in real-world driving conditions.
Support Vector Machine Support Vector Machine ( SVM ) is a supervised learning algorithm used for classification and regression analysis. Machine learning algorithms rely on mathematical functions called “kernels” to make predictions based on input data. This is often done using techniques such as cross-validation or grid search.
Let’s use those fancy algorithms to make predictions from our data. There are many algorithms which can be used from this task ranging from Logistic regression to Deep learning. Later we will use another algorithm as well to see if we can further improve the result. This cross-validation results shows without regularization.
BERT model architecture; image from TDS Hyperparameter tuning Hyperparameter tuning is the process of selecting the optimal hyperparameters for a machine learning algorithm. Use a representative and diverse validation dataset to ensure that the model is not overfitting to the training data.
In this blog, we will cover what plugins are, why they are useful, and an example of how to develop one using the NeuralProphet Python package and Snowflake Data Cloud. Prophet is a time-series forecasting algorithm developed by Facebook that is popular in the data science community because of its performance and ease of use.
In this blog, we will cover what plugins are, why they are useful, and an example of how to develop one using the NeuralProphet Python package and Snowflake Data Cloud. Prophet is a time-series forecasting algorithm developed by Facebook that is popular in the data science community because of its performance and ease of use.
Using various algorithms and tools, a computer vision model can extract valuable information and make decisions by analyzing digital content like images and videos. Thorough validation procedures: Evaluate model performance on unseen data during validation, resembling real-world distribution. What is a Computer Vision Project?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content