This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. And Why did it happen?).
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and datapreparation activities.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
We will demonstrate an example feature engineering process on an e-commerce schema and how GraphReduce deals with the complexity of feature engineering on the relational schema. Datapreparation happens at the entity-level first so errors and anomalies don’t make their way into the aggregated dataset.
Machine learning practitioners tend to do more than just create algorithms all day. First, there’s a need for preparing the data, aka dataengineering basics. As the chart shows, two major themes emerged.
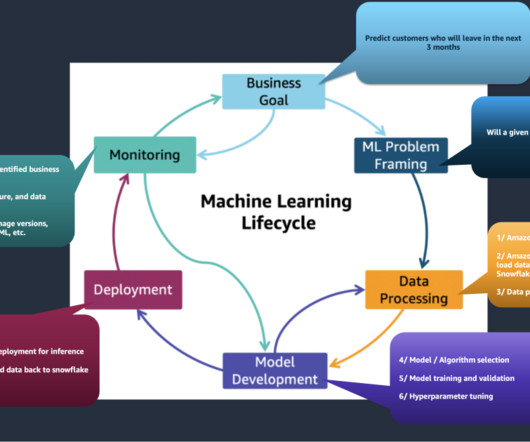
Thus, MLOps is the intersection of Machine Learning, DevOps, and DataEngineering (Figure 1). Figure 4: The ModelOps process [Wikipedia] The Machine Learning Workflow Machine learning requires experimenting with a wide range of datasets, datapreparation, and algorithms to build a model that maximizes some target metric(s).
Dataengineering – Identifies the data sources, sets up data ingestion and pipelines, and preparesdata using Data Wrangler. Data science – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation.
Vertex AI assimilates workflows from data science, dataengineering, and machine learning to help your teams work together with a shared toolkit and grow your apps with the help of Google Cloud. Conclusion Vertex AI is a major improvement over Google Cloud’s machine learning and data science solutions.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently.
No Free Lunch Theorem: Any two algorithms are equivalent when their performance is averaged across all possible problems. MLOps is the intersection of Machine Learning, DevOps, and DataEngineering. All looks good, but the (numerical) result is clearly incorrect.
Boomi’s ML and dataengineering teams needed the solution to be deployed quickly, in a repeatable and consistent way, at scale. However, the underlying algorithm for Step Suggest is complicated and proprietary. SageMaker has built-in support for several popular ML algorithms, but Boomi already had a working solution.
Datapreparation and training The datapreparation and training pipeline includes the following steps: The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time.
Such a pipeline encompasses the stages involved in building, testing, tuning, and deploying ML models, including but not limited to datapreparation, feature engineering, model training, evaluation, deployment, and monitoring. The following diagram illustrates the workflow.
In this blog, we’ll explain why you should prepare your data before use in machine learning , how to clean and preprocess the data, and a few tips and tricks about datapreparation. Why PrepareData for Machine Learning Models? We need to format it to be suitable for machine learning algorithms.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
Consequently, AIOps is designed to harness data and insight generation capabilities to help organizations manage increasingly complex IT stacks. Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data.
It brings together DataEngineering, Data Science, and Data Analytics. Thus providing a collaborative and interactive environment for teams to work on data-intensive projects. Databricks and offers a collaborative workspace where dataengineers, data scientists, and analysts can work together seamlessly.
Understanding the Session In this engaging and interactive session, we will delve into PySpark MLlib, an invaluable resource in the field of machine learning, and explore how various classification algorithms can be implemented using AWS Glue/EMR as our platform. But this session goes beyond just concepts and algorithms.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform Exploratory Data Analysis to uncover patterns and insights hidden within the data. This phase entails meticulously selecting and training algorithms to ensure optimal performance.
Tools like Apache NiFi, Talend, and Informatica provide user-friendly interfaces for designing workflows, integrating diverse data sources, and executing ETL processes efficiently. Choosing the right tool based on the organisation’s specific needs, such as data volume and complexity, is vital for optimising ETL efficiency.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects. What is MLOps?
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Algorithm Development: Crafting algorithms to solve complex business problems and optimise processes. Data Visualization: Ability to create compelling visualisations to communicate insights effectively.
Snowpark Use Cases Data Science Streamlining datapreparation and pre-processing: Snowpark’s Python, Java, and Scala libraries allow data scientists to use familiar tools for wrangling and cleaning data directly within Snowflake, eliminating the need for separate ETL pipelines and reducing context switching.
Automated development: With AutoAI , beginners can quickly get started and more advanced data scientists can accelerate experimentation in AI development. AutoAI automates datapreparation, model development, feature engineering and hyperparameter optimization.
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
Role of Data Transformation in Analytics, Machine Learning, and BI In Data Analytics, transformation helps preparedata for various operations, including filtering, sorting, and summarisation, making the data more accessible and useful for Analysts. Why Are Data Transformation Tools Important?
Dataengineers, data scientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. Activities include managing data, selecting algorithms, training models, and evaluating their performance. LLMOps is MLOps for LLMs. How Does MLOps Work?
Knowledge in these areas enables prompt engineers to understand the mechanics of language models and how to apply them effectively. Data Science Knowing the ins and outs of data science encompasses the ability to handle, analyze, and interpret data, which is required for training models and understanding their outputs.
However, achieving success in AI projects isn’t just about deploying advanced algorithms or machine learning models. The real challenge lies in ensuring that the data powering your projects is AI-ready. Above all, you must remember that trusted AI starts with trusted data.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, dataengineering and data analytics. Do you have any advice for those just getting started in data science? David, what can you tell us about your background?
Overview of core disciplines Data science encompasses several key disciplines including dataengineering, datapreparation, and predictive analytics. Dataengineering lays the groundwork by managing data infrastructure, while datapreparation focuses on cleaning and processing data for analysis.
By applying principles from both DevOps and dataengineering, MLOps facilitates smoother transitions from model development to deployment and ongoing performance monitoring. It ensures collaboration between data science teams and operational engineers. What is machine learning operations (MLOps)?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content