This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Perhaps one of the biggest perks is scalability, which simply means that with good datalake ingestion a small business can begin to handle bigger data numbers. The reality is businesses that are collecting data will likely be doing so on several levels. Uses Powerful Algorithms. Proper Scalability.
Recently we’ve seen lots of posts about a variety of different file formats for datalakes. There’s Delta Lake, Hudi, Iceberg, and QBeast, to name a few. It can be tough to keep track of all these datalake formats — let alone figure out why (or if!) The world of data is huge.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. It’s an integral part of data analytics and plays a crucial role in data science. Each stage is crucial for deriving meaningful insights from data.
Cloud-Based IoT Platforms Cloud-based IoT platforms offer scalable storage and computing resources for handling the massive influx of IoT data. These platforms provide data engineers with the flexibility to develop and deploy IoT applications efficiently.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
Open-source datasets: Utilize publicly available data for training models. Building a datalake A datalake is a central repository that allows for the storage of vast amounts of structured and unstructured data. Testing set: Evaluates model performance against unseen data, identifying its weaknesses.
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake.
Amazon Forecast is a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts. Calculating courier requirements The first step is to estimate hourly demand for each warehouse, as explained in the Algorithm selection section.
This involves: Storing preprocessed data: Utilizing databases or datalakes to preserve data efficiently. Optimizing data formats: Ensuring that data is formatted for effective querying and analysis. Model training Model training is the phase where prepared data is used to develop machine learning models.
Helping government agencies adopt AI and ML technologies Precise works closely with AWS to offer end-to-end cloud services such as enterprise cloud strategy, infrastructure design, cloud-native application development, modern data warehouses and datalakes, AI and ML, cloud migration, and operational support.
Apache Superset remains popular thanks to how well it gives you control over your data. Algorithm-visualizer GitHub | Website Algorithm Visualizer is an interactive online platform that visualizes algorithms from code. The no-code visualization builds are a handy feature.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. AWS also offers developers the technology to develop smart apps using machine learning and complex algorithms.
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios.
With a few taps on a mobile device, riders request a ride; then, Uber’s algorithms work to match them with the nearest available driver and calculate the optimal price. Uber understood that digital superiority required the capture of all their transactional data, not just a sampling. But the simplicity ends there.
Poems penned by algorithms, paintings birthed from code – it felt like witnessing the singularity in real-time. And let’s not forget the fundamental question: what even constitutes “creativity” in the face of an algorithm? It can dredge up connections and inspirations from the depths of its datalakes.
Then the transcripts of contacts become available to CSBA to extract actionable insights through millions of customer contacts for the sellers, and the data is stored in the Seller DataLake. After the AI/ML-based analytics, all actionable insights are generated and then stored in the Seller DataLake.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
They made clear that the wealth of data being made available would be critical in creating new tools in the fight against cancer. Healthineers said, “ We strongly support the ambition to accelerate the development of algorithms by creating larger datalakes of critical medical images. ”
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. Machine learning and AI analytics: Machine learning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. This will lead to algorithm development for any machine or deep learning processes.
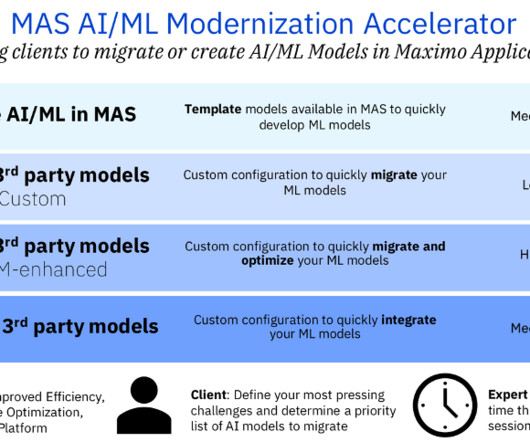
Each of these accelerators leverages state-of-the-art algorithms and machine learning techniques to identify anomalies accurately and in real-time. Solution 2: Migrate 3rd party models to MAS (Custom Model) This data science solution predicts anomalies in air compressor assets using an isolation forest model.
Business users will also perform data analytics within business intelligence (BI) platforms for insight into current market conditions or probable decision-making outcomes. Many functions of data analytics—such as making predictions—are built on machine learning algorithms and models that are developed by data scientists.
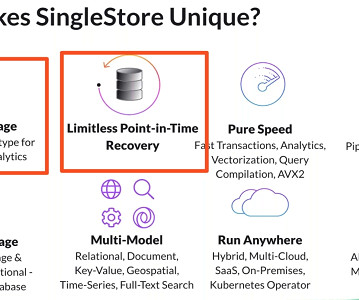
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how data models and algorithms rely on powerful and versatile data infrastructure.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
His focus was building machine learning algorithms to simulate nervous network anomalies. He joined Getir in 2019 and currently works as a Senior Data Science & Analytics Manager. His team is responsible for designing, implementing, and maintaining end-to-end machine learning algorithms and data-driven solutions for Getir.
Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, datalakes, and big data technologies to build and maintain data pipelines.
Image by the Author: AI business use cases Defining Artificial Intelligence Artificial Intelligence (AI) is a term used to describe the development of robust computer systems that can think and react like a human, possessing the ability to learn, analyze, adapt and make decisions based on the available data.
The data lakehouse is one such architecture—with “lake” from datalake and “house” from data warehouse. This modern, cloud-based data stack enables you to have all your data in one place while unlocking both backward-looking, historical analysis as well as forward-looking scenario planning and predictive analysis.
Automated Machine Learning (AutoML) : This feature automates time-consuming tasks like algorithm selection, hyperparameter tuning, and feature engineering. Simply prepare your data, define your target variable, and let AutoML explore various algorithms and hyperparameters. Learn more from the MLflow with Azure ML documentation.
Data sources, embeddings, and vector store Organizations domain-specific data, which provides context and relevance, typically resides in internal databases, datalakes, unstructured data repositories, or document stores, collectively referred to as organizational data sources or proprietary data stores.
models are trained on IBM’s curated, enterprise-focused datalake, on our custom-designed cloud-native AI supercomputer, Vela. All watsonx.ai Efficiency and sustainability are core design principles for watsonx.ai.
The data lakehouse is one such architecture—with “lake” from datalake and “house” from data warehouse. This modern, cloud-based data stack enables you to have all your data in one place while unlocking both backward-looking, historical analysis as well as forward-looking scenario planning and predictive analysis.
Ocean Protocol’s smart contracts include permissioned datatokens and data NFTs that enable IP rights management in data wallets. Ocean Protocol tools are built to extract value from data by improving its algorithmic accessibility & security. However, to gain such smart recommendations, we sacrifice our data privacy.
A novel approach to solve this complex security analytics scenario combines the ingestion and storage of security data using Amazon Security Lake and analyzing the security data with machine learning (ML) using Amazon SageMaker. SageMaker supports two built-in anomaly detection algorithms: IP Insights and Random Cut Forest.
Architecture The architecture includes two types of SQL pools: Dedicated predictable workloads and serverless for on-demand querying Support for Apache Spark for big data processing. architecture for both structured and unstructured data. The Message Passing Layer ensures efficient communication between components.
Together with data stores, foundation models make it possible to create and customize generative AI tools for organizations across industries that are looking to optimize customer care, marketing, HR (including talent acquisition) , and IT functions. models are trained on IBM’s curated, enterprise-focused datalake.
Developed by Salesforce, Einstein Discovery enables people to create powerful predictive models without needing to write algorithms. This offers everyone from data scientists to advanced analysts to business users an intuitive, no-code environment that empowers quick and confident decisions guided by ethical, transparent AI.
By harnessing the transformative potential of MongoDB’s native time series data capabilities and integrating it with the power of Amazon SageMaker Canvas , organizations can overcome these challenges and unlock new levels of agility. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
You can set up multiple such stacks to run them simultaneously, with each one analyzing the data and reporting back the anomalies. The application, once deployed, constructs an ML model using the Random Cut Forest (RCF) algorithm. Post-training, the model continues to process incoming data points from the stream.
We use data-specific preprocessing and ML algorithms suited to each modality to filter out noise and inconsistencies in unstructured data. NLP cleans and refines content for text data, while audio data benefits from signal processing to remove background noise. Such algorithms are key to enhancing data.
Sometimes, you don’t know what data a model was trained on because the creators of those models won’t tell you. It becomes difficult to ensure that the model algorithms outputs aren’t biased, or even toxic. And those massive large-scale datasets contain some of the darker corners of the internet.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























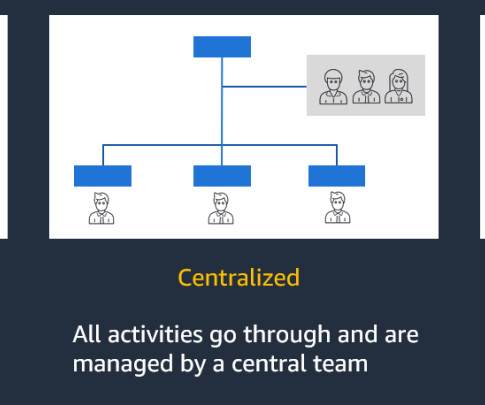

















Let's personalize your content