This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
Business users will also perform data analytics within business intelligence (BI) platforms for insight into current market conditions or probable decision-making outcomes. Many functions of data analytics—such as making predictions—are built on machine learning algorithms and models that are developed by data scientists.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Embrace Data-Centric AI The key to unlocking value in AI lies in a data-centric approach, according to Andrew Ng.
Data Engineering Career: Unleashing The True Potential of Data Problem-Solving Skills Data Engineers are required to possess strong analytical and problem-solving skills to navigate complex data challenges. Understanding these fundamentals is essential for effective problem-solving in data engineering.
Definitions: Foundation Models, Gen AI, and LLMs Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements: Foundation Models (FMs) - Large deep learning models that are pre-trained with attention mechanisms on massive datasets. Typically, foundation models are used.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. Microsoft Azure Synapse Analytics Microsoft Azure Synapse Analytics is an integrated analytics service that combines data warehousing and big data capabilities into a unified platform.
DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Multi-Stage Pipeline - Ensures correct model behavior and incorporates feedback loops.
MLOps helps these organizations to continuously monitor the systems for accuracy and fairness, with automated processes for model retraining and deployment as new data becomes available. You can consider this stage as the most code-intensive stage of the entire ML pipeline. It is designed to leverage hardware acceleration (e.g.,
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Team composition The team comprises datapipeline engineers, ML engineers, full-stack engineers, and data scientists. Organization Acquia Industry Software-as-a-service Team size Acquia built an ML team five years ago in 2017 and has a team size of 6.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources.
Data can change a lot, models may also quickly evolve and dependencies become old-fashioned which makes it hard to maintain consistency or reproducibility. With weak version control, teams could face problems like inconsistent data, model drift , and clashes in their code. The Need For Reproducibility and Traceability.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages. Model deployment.
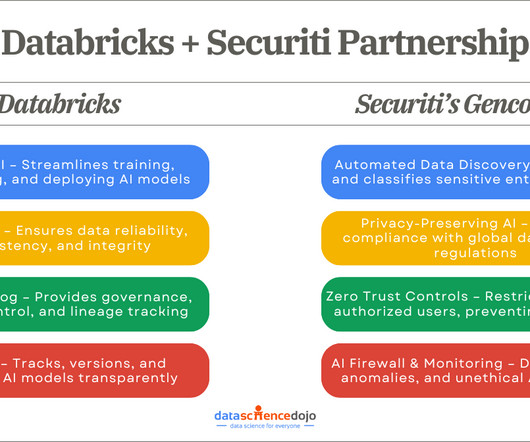
You can also read about algorithmic biases and their challenges in fair AI A Strategic Partnership: Databricks and Securitis Gencore AI In the face of these challenges, enterprises strive to balance innovation with security and compliance. Optimized DataPipelines for AI Readiness AI models are only as good as the data they process.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content