This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, datamodeling, and data visualization.
These skills include programming languages such as Python and R, statistics and probability, machine learning, data visualization, and datamodeling. This includes sourcing, gathering, arranging, processing, and modelingdata, as well as being able to analyze large volumes of structured or unstructured data.
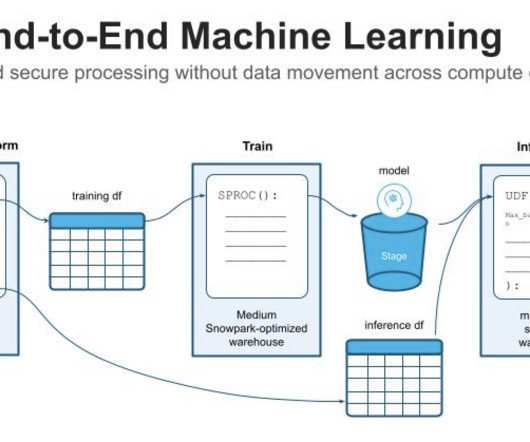
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
introduces a wide range of capabilities designed to improve every stage of data analysis—from datapreparation to dashboard consumption. In addition, the new relevance algorithm intelligently corrects for common issues like misspellings, spacing, and punctuation. Speed up and simplify data prep with parameters.
introduces a wide range of capabilities designed to improve every stage of data analysis—from datapreparation to dashboard consumption. In addition, the new relevance algorithm intelligently corrects for common issues like misspellings, spacing, and punctuation. Speed up and simplify data prep with parameters.
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
Embrace Data-Centric AI The key to unlocking value in AI lies in a data-centric approach, according to Andrew Ng. Data that has errors and is messy, is often fixed by ad hoc data engineering that relies on luck or individual data scientists’ skills. Your training data is a finite resource.
New machines are added continuously to the system, so we had to make sure our model can handle prediction on new machines that have never been seen in training. Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation.
Greater Accuracy Machine learning models can handle high-dimensional, nonlinear, and interactive relationships between variables. These nuanced algorithms can lead to more accurate and reliable credit scores and decisions. They can process large amounts of data in real time, providing instant credit scores and decisions.
In the world of artificial intelligence (AI), data plays a crucial role. It is the lifeblood that fuels AI algorithms and enables machines to learn and make intelligent decisions. And to effectively harness the power of data, organizations are adopting data-centric architectures in AI. text, images, videos).
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. This results in quite efficient sales data predictions. In its core, lie gradient-boosted decision trees.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Data science practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
You need to make that model available to the end users, monitor it, and retrain it for better performance if needed. MLOps helps these organizations to continuously monitor the systems for accuracy and fairness, with automated processes for model retraining and deployment as new data becomes available.
Data Pipeline - Manages and processes various data sources. Application Pipeline - Manages requests and data/model validations. Multi-Stage Pipeline - Ensures correct model behavior and incorporates feedback loops. ML Pipeline - Focuses on training, validation and deployment. How Does MLOps Work?
Predictive Analytics : Models that forecast future events based on historical data. Model Repository and Access Users can browse a comprehensive library of pre-trained models tailored to specific business needs, making it easy to find the right solution for various applications.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
It now allows users to clean, transform, and integrate data from various sources, streamlining the Data Analysis process. This eliminates the need to rely on separate tools for datapreparation, saving time and resources. Anomaly Detection Anomalies – those unexpected deviations in your data – can hold valuable insights.
Einstein Discovery in Tableau uses machine learning (ML) to create models and deliver predictions and recommendations within the analytics workflow. No code or algorithms needed. Einstein sifted through the data, discovered patterns, and surfaced recommendations in natural language. The best part?
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages. They include: 1 Data (or input) pipeline.
Einstein Discovery in Tableau uses machine learning (ML) to create models and deliver predictions and recommendations within the analytics workflow. No code or algorithms needed. Einstein sifted through the data, discovered patterns, and surfaced recommendations in natural language. The best part?
Customers can select relevant evaluation datasets and metrics for their scenarios and extend them with their own prompt datasets and evaluation algorithms. Data scientists can analyze detailed results with SageMaker Clarify visualizations in Notebooks, SageMaker Model Cards, and PDF reports. temperature: 0.6
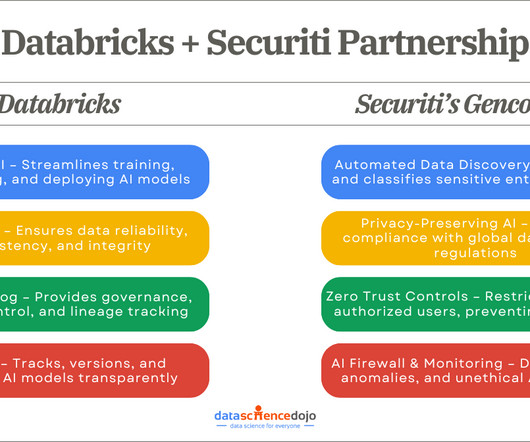
You can also read about algorithmic biases and their challenges in fair AI A Strategic Partnership: Databricks and Securitis Gencore AI In the face of these challenges, enterprises strive to balance innovation with security and compliance. This is where the Databricks and Securiti partnership creates a game-changing opportunity.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content