This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines. One of the standout features of Dataiku is its focus on collaboration.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Using innovative approaches and advanced algorithms, participants modeled scenarios accounting for starting grid positions, driver performance, and unpredictable race conditions like weather changes or mid-race interruptions. His focus on track-specific insights and comprehensive datapreparation set the model apart.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Embrace Data-Centric AI The key to unlocking value in AI lies in a data-centric approach, according to Andrew Ng.
It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. DataPreparation: Cleaning and transforming raw data to make it usable for machine learning. Model Training: Running computations to learn from the data.
Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data. MLOps prioritizes end-to-end management of machine learning models, encompassing datapreparation, model training, hyperparameter tuning and validation.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
Sagemaker provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects. What is MLOps?
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Algorithm Development: Crafting algorithms to solve complex business problems and optimise processes. Data Visualization: Ability to create compelling visualisations to communicate insights effectively.
This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. Parallelism is suited for workloads that are repetitive, fixed tasks, involving little conditional branching and often large amounts of data.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
Role of Data Transformation in Analytics, Machine Learning, and BI In Data Analytics, transformation helps preparedata for various operations, including filtering, sorting, and summarisation, making the data more accessible and useful for Analysts. Why Are Data Transformation Tools Important?
Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Collecting feedback for further tuning.
Using various algorithms and tools, a computer vision model can extract valuable information and make decisions by analyzing digital content like images and videos. Preprocess data to mirror real-world deployment conditions. What is a Computer Vision Project?
Snowpark Use Cases Data Science Streamlining datapreparation and pre-processing: Snowpark’s Python, Java, and Scala libraries allow data scientists to use familiar tools for wrangling and cleaning data directly within Snowflake, eliminating the need for separate ETL pipelines and reducing context switching.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production.
Elements of a machine learning pipeline Some pipelines will provide high-level abstractions for these components through three elements: Transformer : an algorithm able to transform one dataset into another. Estimator : an algorithm trained on a dataset to produce a transformer. Data preprocessing. Model scoring.
David: My technical background is in ETL, data extraction, data engineering and data analytics. I spent over a decade of my career developing large-scale datapipelines to transform both structured and unstructured data into formats that can be utilized in downstream systems.
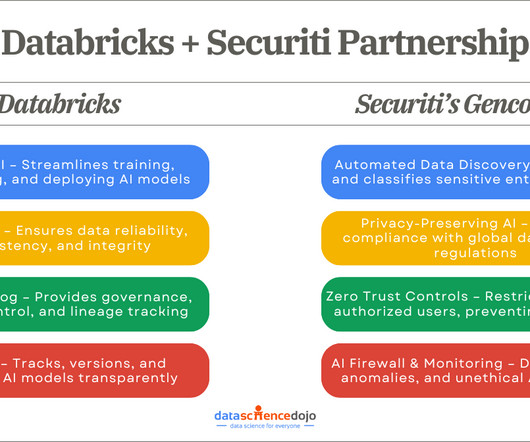
You can also read about algorithmic biases and their challenges in fair AI A Strategic Partnership: Databricks and Securitis Gencore AI In the face of these challenges, enterprises strive to balance innovation with security and compliance. Optimized DataPipelines for AI Readiness AI models are only as good as the data they process.
Overview of core disciplines Data science encompasses several key disciplines including data engineering, datapreparation, and predictive analytics. Data engineering lays the groundwork by managing data infrastructure, while datapreparation focuses on cleaning and processing data for analysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content