This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
We exist in a diversified era of data tools up and down the stack – from storage to algorithm testing to stunning business insights. appeared first on DATAVERSITY.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? This ensures that the data which will be used for ML is accurate, reliable, and consistent.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Their expertise lies in designing algorithms, optimizing models, and integrating them into real-world applications. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on data analysis and interpretation to extract meaningful insights.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Data Observability and DataQuality are two key aspects of data management. The focus of this blog is going to be on Data Observability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data. What is Data Observability?
Apache Superset remains popular thanks to how well it gives you control over your data. Algorithm-visualizer GitHub | Website Algorithm Visualizer is an interactive online platform that visualizes algorithms from code. The no-code visualization builds are a handy feature. You can watch it on demand here.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Challenges in rectifying biased data: If the data is biased from the beginning, “ the only way to retroactively remove a portion of that data is by retraining the algorithm from scratch.” This may cause the model to exclude entire areas, departments, demographics, industries or sources from the conversation.
” For example, synthetic data represents a promising way to address the data crisis. This data is created algorithmically to mimic the characteristics of real-world data and can serve as an alternative or supplement to it. In this context, dataquality often outweighs quantity.
Some of our most popular in-person sessions were: MLOps: Monitoring and Managing Drift: Oliver Zeigermann | Machine Learning Architect ODSC Keynote: Human-Centered AI: Peter Norvig, PhD | Engineering Director, Education Fellow | Google, Stanford Institute for Human-Centered Artificial Intelligence (HAI) The Cost of AI Compute and Why AI Clouds Will (..)
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Summary : This comprehensive guide delves into data anomalies, exploring their types, causes, and detection methods. It highlights the implications of anomalies in sectors like finance and healthcare, and offers strategies for effectively addressing them to improve dataquality and decision-making processes.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. Why Are Data Transformation Tools Important?
Researchers rely on its rich content to experiment with novel architectures, fine-tune domain-specific applications, and benchmark new algorithms. The dataset has also been instrumental in advancing multilingual NLP models and enhancing AI ethics research by exposing biases in training data.
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. Implementation of metadata-driven datapipelines for governance and reporting. This is where AI truly shines.
Artificial intelligence (AI) algorithms are trained to detect anomalies. It synthesizes all the metadata around your organization’s data assets and arranges the information into a simple, easy-to-understand format. Today’s enterprises need real-time or near-real-time performance, depending on the specific application. Timing matters.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. Advanced algorithms recognize patterns in temporal data effectively. This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g.,
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
Impact of duplicate data on model performance Duplicate data often impact the model performance unless they are specially augmented ones to improve the model performance or increase minority class representation. Let’s look into potential issues caused by duplicate data. . you can identify similar or duplicate images.
Key challenges include data storage, processing speed, scalability, and security and compliance. What is the Role of Zookeeper in Big Data? How Do You Ensure DataQuality in a Big Data Project? Data validation, cleansing techniques, and monitoring tools are used to maintain accuracy and consistency.
Artificial intelligence (AI) algorithms are trained to detect anomalies. It synthesizes all the metadata around your organization’s data assets and arranges the information into a simple, easy-to-understand format. Today’s enterprises need real-time or near-real-time performance, depending on the specific application. Timing matters.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Collecting feedback for further tuning.
Using various algorithms and tools, a computer vision model can extract valuable information and make decisions by analyzing digital content like images and videos. Incompatibility between the Data & Model Domains Choosing the appropriate model depends on your data's complexity, size, and nature.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. The datapipelines can be scheduled as event-driven or be run at specific intervals the users choose.
Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources.
Modern AI, on the other hand, is built on machine learning and artificial neural networks – algorithms that can learn their behavior from examples in data. As computational power increased and data became more abundant, AI evolved to encompass machine learning and data analytics.
Let’s break down why this is so powerful for us marketers: Data Preservation : By keeping a copy of your raw customer data, you preserve the original context and granularity. DataQuality Management : Persistent staging provides a clear demarcation between raw and processed customer data.
Elements of a machine learning pipeline Some pipelines will provide high-level abstractions for these components through three elements: Transformer : an algorithm able to transform one dataset into another. Estimator : an algorithm trained on a dataset to produce a transformer. Data preprocessing.
Key Takeaways By deploying technologies that can learn and improve over time, companies that embrace AI and machine learning can achieve significantly better results from their dataquality initiatives. Here are five dataquality best practices which business leaders should focus.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. And when the platform automates the entire process, it’ll likely produce and deploy a bad-quality model.
From insurance claims management to supply chain optimization and fraud detection, AI: Discovers correlations Assesses potential outcomes Automates routine decisions Despite the advances such technologies make possible, data practitioners are keenly aware that the problem of poor data integrity may be magnified by large-scale automation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























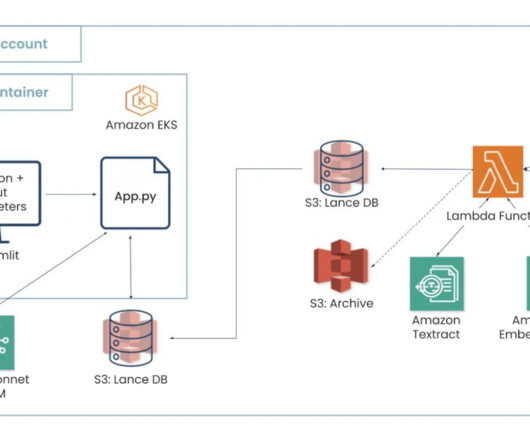








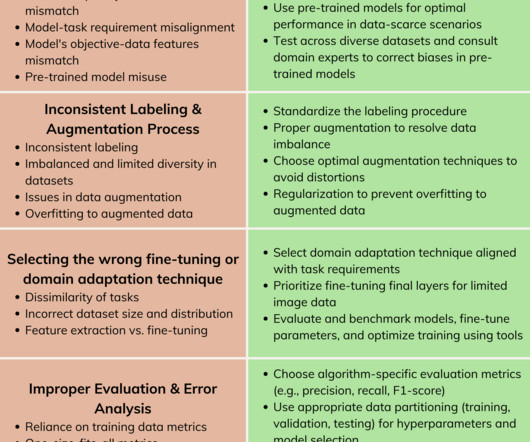
















Let's personalize your content