This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
14 Essential Git Commands for Data Scientists • Statistics and Probability for Data Science • 20 Basic Linux Commands for Data Science Beginners • 3 Ways Understanding Bayes Theorem Will Improve Your Data Science • Learn MLOps with This Free Course • Primary Supervised Learning Algorithms Used in Machine Learning • DataPreparation with SQL Cheatsheet. (..)
Introduction on AutoKeras Automated Machine Learning (AutoML) is a computerised way of determining the best combination of datapreparation, model, and hyperparameters for a predictive modelling task. The AutoML model aims to automate all actions which require more time, such as algorithm selection, […].
Overview Introduction to Natural Language Generation (NLG) and related things- DataPreparation Training Neural Language Models Build a Natural Language Generation System using PyTorch. The post Build a Natural Language Generation (NLG) System using PyTorch appeared first on Analytics Vidhya.
In this article, I describe 3 alternative algorithms to select predictive features based on a feature importance score. Feature selection methodologies go beyond filter, wrapper and embedded methods.
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
It’s an integral part of data analytics and plays a crucial role in data science. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, data modeling, and data visualization.
Feature Engineering is a process of using domain knowledge to extract and transform features from raw data. These features can be used to improve the performance of Machine Learning Algorithms. Normalization A feature scaling technique is often applied as part of datapreparation for machine learning.
Financial services In the financial sector, synthetic credit card transaction data is utilized for fraud detection. This approach enables companies to develop algorithms that identify suspicious patterns without exposing sensitive data during the training phase.
This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data. The goal of datapreparation is to present data in the best forms for decision-making and problem-solving.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
With the increasing reliance on technology in our personal and professional lives, the volume of data generated daily is expected to grow. This rapid increase in data has created a need for ways to make sense of it all. The post DataPreparation and Raw Data in Machine Learning: Why They Matter appeared first on DATAVERSITY.
With the most recent developments in machine learning , this process has become more accurate, flexible, and fast: algorithms analyze vast amounts of data, glean insights from the data, and find optimal solutions. Given the enormous volume of information which can reach petabytes efficient data handling is crucial.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Be sure to check out her talk, “ Hands-on Data-Centric AI: Datapreparation tuning — why and how? Given that data has higher stakes , it only means that you should invest most of your development investment in improving your data quality.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
Data scientists dedicate a significant chunk of their time to datapreparation, as revealed by a survey conducted by the data science platform Anaconda. This process involves rectifying or discarding abnormal or non-standard data points and ensuring the accuracy of measurements.
Ryan Cairnes Senior Manager, Product Management, Tableau Hannah Kuffner July 28, 2020 - 10:43pm March 20, 2023 Tableau Prep is a citizen datapreparation tool that brings analytics to anyone, anywhere. With Prep, users can easily and quickly combine, shape, and clean data for analysis with just a few clicks.
Ryan Cairnes Senior Manager, Product Management, Tableau Hannah Kuffner July 28, 2020 - 10:43pm March 20, 2023 Tableau Prep is a citizen datapreparation tool that brings analytics to anyone, anywhere. With Prep, users can easily and quickly combine, shape, and clean data for analysis with just a few clicks.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
Describe any datapreparation and feature engineering steps that you have done. If you are having coding issues, it is best to share a link to the code/algorithm source and say that you are having problems with the implementation rather than posting code snippets and asking “what is wrong with my code?” Describe the problem.
One of the most popular algorithms in Machine Learning are the Decision Trees that are useful in regression and classification tasks. In Supervised Learning, Decision Trees are the Machine Learning algorithms where you can split data continuously based on a specific parameter. How Decision Tree Algorithm works?
Introduction to Deep Learning Algorithms: Deep learning algorithms are a subset of machine learning techniques that are designed to automatically learn and represent data in multiple layers of abstraction. This process is known as training, and it relies on large amounts of labeled data. How Deep Learning Algorithms Work?
Classification algorithms are some of the most useful machine learning models in use today. A confusion matrix is a chart that compares the predicted labels of a classification algorithm to their actual value. Confusion matrices do just that for classification algorithms. Many classification tasks naturally involve imbalance.
Step 4: Retrieval of text chunks After storing the data, preparing the LLM model, and constructing the pipeline, we need to retrieve the data. Lang Chain offers a variety of retriever algorithms, here is the one we implement. Retrievers serve as interfaces that return documents based on a query.
Common mistakes and misconceptions about learning AI/ML Markus Spiske on Unsplash A common misconception of beginners is that they can learn AI/ML from a few tutorials that implement the latest algorithms, so I thought I would share some notes and advice on learning AI. Trying to code ML algorithms from scratch.
For example, Scikit-learn can be used to: Classify customer churn Predict product sales Cluster customer segments Reduce the dimensionality of a dataset Select features for a machine learning model Notable features and capabilities Scikit-learn has a number of notable features and capabilities, including: A wide range of machine learning algorithms (..)
The process of building a machine learning pipeline with a drag-and-drop tool usually starts with selecting the data source. Once the data source is selected, the user can then add preprocessing steps to clean and prepare the data. The next step is to select the machine learning algorithm to be used for the model.
This is because decision intelligence platforms can use machine learning algorithms to identify patterns and trends in data. Let’s imagine that, a manufacturing company uses decision intelligence to track data on machine performance.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. The BlazingText algorithm expects a single preprocessed text file with space-separated tokens. You now run the datapreparation step in the notebook. For instructions, see Create your first S3 bucket.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
Data scientists are the master keyholders, unlocking this portal to reveal the mysteries within. They wield algorithms like ancient incantations, summoning patterns from the chaos and crafting narratives from raw numbers. Model development : Crafting magic from algorithms!
The tables have the following row counts: Customers: 2 rows Orders: 4 rows Order products: 16 rows Order events: 26 rows Notifications: 10 rows Notification interactions: 15 rows Datapreparation and filtering: Datapreparation involves removing incorrect or outlier data.
While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. This will land on a data flow page. Choose your domain.
We can apply a data-centric approach by using AutoML or coding a custom test harness to evaluate many algorithms (say 20–30) on the dataset and then choose the top performers (perhaps top 3) for further study, being sure to give preference to simpler algorithms (Occam’s Razor).
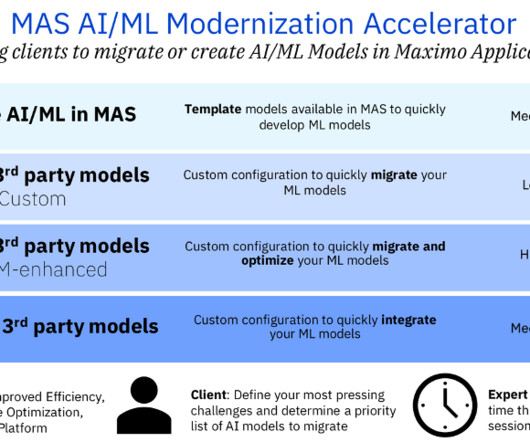
Each of these accelerators leverages state-of-the-art algorithms and machine learning techniques to identify anomalies accurately and in real-time. Solution 2: Migrate 3rd party models to MAS (Custom Model) This data science solution predicts anomalies in air compressor assets using an isolation forest model.
It became apparent that the default Kubernetes scheduler algorithm was the culprit. The algorithm is (cpu((capacity-sum(requested))*MaxNodeScore/capacity) + memory((capacity-sum(requested))*MaxNodeScore/capacity))/weightSum. While it provided some improvements, it did not fundamentally resolve the issue.
With data visualization capabilities, advanced statistical analysis methods and modeling techniques, IBM SPSS Statistics enables users to pursue a comprehensive analytical journey from datapreparation and management to analysis and reporting. The advantages of using SPSS Statistics with R or Python together are many.
DataPreparation Here we use a subset of the ImageNet dataset (100 classes). You can follow command below to download the data. Data Insert This step uses an Insert Pipeline to insert image embeddings into Milvus collection. Search pipeline Preprocess the query image following the same steps as datapreparation.
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In this tutorial, you will learn how to implement a predictive maintenance system using the Isolation Forest algorithm — a well-known algorithm for anomaly detection. And Why Anomaly Detection?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content