This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Augmented analytics is the integration of ML and NLP technologies aimed at automating several aspects of datapreparation and analysis. It enhances traditional data analytics by allowing users to derive actionable insights quickly and efficiently. This leads to better business planning and resource allocation.
We exist in a diversified era of data tools up and down the stack – from storage to algorithm testing to stunning business insights. appeared first on DATAVERSITY.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Be sure to check out her talk, “ Hands-on Data-Centric AI: Datapreparation tuning — why and how? Given that data has higher stakes , it only means that you should invest most of your development investment in improving your dataquality.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization.
With the increasing reliance on technology in our personal and professional lives, the volume of data generated daily is expected to grow. This rapid increase in data has created a need for ways to make sense of it all. The post DataPreparation and Raw Data in Machine Learning: Why They Matter appeared first on DATAVERSITY.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. We start from creating a data flow.
Machine learning practitioners tend to do more than just create algorithms all day. First, there’s a need for preparing the data, aka data engineering basics. Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building. These activities play a crucial role in extracting meaningful insights from raw data and improving model performance, leading to more robust and insightful results.
No Free Lunch Theorem: Any two algorithms are equivalent when their performance is averaged across all possible problems. MLOps is the intersection of Machine Learning, DevOps, and Data Engineering. Dataquality: ensuring the data received in production is processed in the same way as the training data.
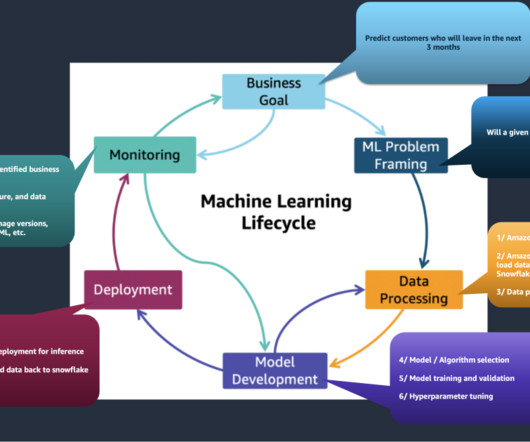
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Datapreparation For this example, you will use the South German Credit dataset open source dataset.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML. Choose Create.
Key Takeaways: Trusted AI requires data integrity. For AI-ready data, focus on comprehensive data integration, dataquality and governance, and data enrichment. Building data literacy across your organization empowers teams to make better use of AI tools. The impact?
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, datapreparation, and algorithm selection. Dataquality significantly impacts model performance.
Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Importance of Data in AI Qualitydata is the lifeblood of AI models, directly influencing their performance and reliability.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. Why Are Data Transformation Tools Important?
Summary: Predictive analytics utilizes historical data, statistical algorithms, and Machine Learning techniques to forecast future outcomes. This blog explores the essential steps involved in analytics, including data collection, model building, and deployment. What is Predictive Analytics?
In the world of artificial intelligence (AI), data plays a crucial role. It is the lifeblood that fuels AI algorithms and enables machines to learn and make intelligent decisions. And to effectively harness the power of data, organizations are adopting data-centric architectures in AI. text, images, videos).
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform Exploratory Data Analysis to uncover patterns and insights hidden within the data. This crucial stage involves data cleaning, normalisation, transformation, and integration.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality.
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
For many years, Philips has been pioneering the development of data-driven algorithms to fuel its innovative solutions across the healthcare continuum. Also in patient monitoring, image guided therapy, ultrasound and personal health teams have been creating ML algorithms and applications.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Ensuring dataquality, governance, and security may slow down or stall ML projects. Conduct exploratory analysis and datapreparation. Determine the ML algorithm, if known or possible. You may often select low-value use cases as proof of concept rather than solving a meaningful business or customer problem.
They use advanced algorithms to proactively identify and resolve network issues, reducing downtime and improving service to their subscribers. All that time spent on datapreparation has an opportunity cost associated with it. Data Governance Drives Insights Data governance provides an important framework.
ML uses massive amounts of data to learn, which was not economically possible until the last ten years. All Machine Learning uses “algorithms,” many of which are no different from those used by statisticians and data scientists. Many have heralded ML as a promising new frontier. Conclusion.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few. You can find more details about training datapreparation and understand the custom classifier metrics.
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. This results in quite efficient sales data predictions. In its core, lie gradient-boosted decision trees.
It provides high-quality, curated data, often with associated tasks and domain-specific challenges, which helps bridge the gap between theoretical ML algorithms and real-world problem-solving. The data can then be explored, cleaned, and processed to be used in Machine Learning models.
Ultimately, polynomial regression offers a flexible means to model complex data without jumping to advanced Machine Learning algorithms. You begin with thorough datapreparation, proceed to feature engineering to capture curvature, train your chosen model on these enhanced features, and evaluate its accuracy using appropriate metrics.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering. However, generalizing feature engineering is challenging.
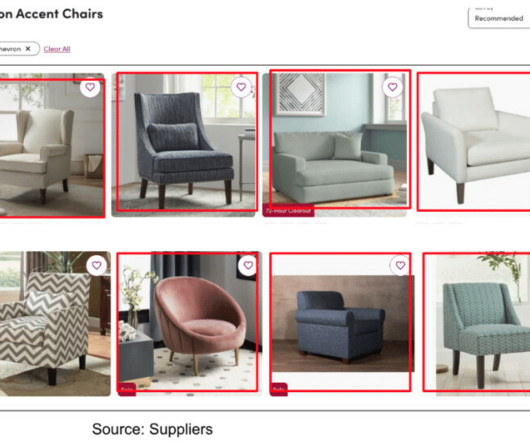
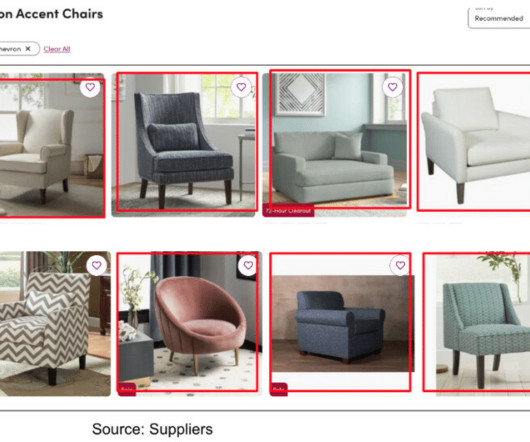
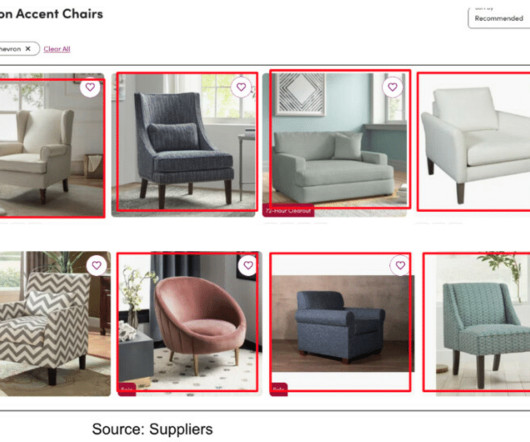
We use machine learning algorithms to analyze and understand the descriptive information (e.g. Example above shows results for “modern yellow sofa” We develop machine learning algorithms to extract product tags from images which are available when suppliers upload products to our catalog. What are product tags?
This is brought on by various developments, such as the availability of data, the creation of more potent computer resources, and the development of machine learning algorithms. Data Management Data management in LLMOps entails handling massive datasets for pre-training and fine-tuning large language models.
We use machine learning algorithms to analyze and understand the descriptive information (e.g. Example above shows results for “modern yellow sofa” We develop machine learning algorithms to extract product tags from images which are available when suppliers upload products to our catalog. What are product tags?
We use machine learning algorithms to analyze and understand the descriptive information (e.g. Example above shows results for “modern yellow sofa” We develop machine learning algorithms to extract product tags from images which are available when suppliers upload products to our catalog. What are product tags?
Source: [link] Data annotation involves labeling data points, such as images or text, with relevant information, enabling the algorithms to learn and make sense of the patterns within the data. Source: Author SuperAnnotate helps annotate data with a wide range of tools like bounding boxes, polygons, and speech tagging.
These models do not rely on predefined labels; instead, they discover the inherent structure in the data by identifying clusters based on similarities. Popular clustering algorithms include k-means and hierarchical clustering. Qualitydata is essential, as poor or incomplete data can lead to inaccurate models.
With these set up, you can move to the key LLMOps activities: Data Handling and Management - The organization, storage and pre-processing of the vast data needed for training language models. This includes versioning, ingestion and ensuring dataquality. How Does MLOps Work?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content