This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
14 Essential Git Commands for Data Scientists • Statistics and Probability for DataScience • 20 Basic Linux Commands for DataScience Beginners • 3 Ways Understanding Bayes Theorem Will Improve Your DataScience • Learn MLOps with This Free Course • Primary Supervised Learning Algorithms Used in Machine Learning • DataPreparation with SQL Cheatsheet. (..)
This article was published as a part of the DataScience Blogathon. Introduction on AutoKeras Automated Machine Learning (AutoML) is a computerised way of determining the best combination of datapreparation, model, and hyperparameters for a predictive modelling task.
Big data and datascience in the digital age The digital age has resulted in the generation of enormous amounts of data daily, ranging from social media interactions to online shopping habits. quintillion bytes of data are created. This is where datascience plays a crucial role. What is datascience?
In the modern digital era, this particular area has evolved to give rise to a discipline known as DataScience. DataScience offers a comprehensive and systematic approach to extracting actionable insights from complex and unstructured data.
As datascience evolves and grows, the demand for skilled data scientists is also rising. A data scientist’s role is to extract insights and knowledge from data and to use this information to inform decisions and drive business growth.
With its decoupled compute and storage resources, Snowflake is a cloud-native data platform optimized to scale with the business. Dataiku is an advanced analytics and machine learning platform designed to democratize datascience and foster collaboration across technical and non-technical teams.
It’s an integral part of data analytics and plays a crucial role in datascience. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
Feature Engineering is a process of using domain knowledge to extract and transform features from raw data. These features can be used to improve the performance of Machine Learning Algorithms. In the world of datascience and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results.
This is because decision intelligence platforms can use machine learning algorithms to identify patterns and trends in data. Let’s imagine that, a manufacturing company uses decision intelligence to track data on machine performance. This training should cover the basics of datascience, analytics, and machine learning.
Today’s question is, “What does a data scientist do.” ” Step into the realm of datascience, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of data scientists.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
The process of building a machine learning pipeline with a drag-and-drop tool usually starts with selecting the data source. Once the data source is selected, the user can then add preprocessing steps to clean and prepare the data. The next step is to select the machine learning algorithm to be used for the model.
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Be sure to check out her talk, “ Hands-on Data-Centric AI: Datapreparation tuning — why and how? Given that data has higher stakes , it only means that you should invest most of your development investment in improving your data quality.
Data scientists dedicate a significant chunk of their time to datapreparation, as revealed by a survey conducted by the datascience platform Anaconda. This process involves rectifying or discarding abnormal or non-standard data points and ensuring the accuracy of measurements.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
Summary: The future of DataScience is shaped by emerging trends such as advanced AI and Machine Learning, augmented analytics, and automated processes. As industries increasingly rely on data-driven insights, ethical considerations regarding data privacy and bias mitigation will become paramount.
Step 4: Retrieval of text chunks After storing the data, preparing the LLM model, and constructing the pipeline, we need to retrieve the data. Lang Chain offers a variety of retriever algorithms, here is the one we implement. Retrievers serve as interfaces that return documents based on a query.
Summary: DataScience and AI are transforming the future by enabling smarter decision-making, automating processes, and uncovering valuable insights from vast datasets. Introduction DataScience and Artificial Intelligence (AI) are at the forefront of technological innovation, fundamentally transforming industries and everyday life.
Each of these accelerators leverages state-of-the-art algorithms and machine learning techniques to identify anomalies accurately and in real-time. All data scientists could leverage our patterns during an engagement. We are leveraging Air Compressors data, but the solutions are generalizable.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
Summary: The DataScience and Data Analysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Understanding their life cycles is critical to unlocking their potential.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
RapidMiner RapidMiner is a commercial datascience platform that can be used for a variety of data analysis tasks. It is a powerful ai tool that can be used to automate many of the tasks involved in data analysis, and it can also help businesses to discover new insights from their data.
Machine learning practitioners tend to do more than just create algorithms all day. First, there’s a need for preparing the data, aka data engineering basics. You can also get datascience training on-demand wherever you are with our Ai+ Training platform. As the chart shows, two major themes emerged.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and datapreparation activities.
Common mistakes and misconceptions about learning AI/ML Markus Spiske on Unsplash A common misconception of beginners is that they can learn AI/ML from a few tutorials that implement the latest algorithms, so I thought I would share some notes and advice on learning AI. Trying to code ML algorithms from scratch.
PyCaret allows data professionals to build and deploy machine learning models easily and efficiently. What makes this the low-code library of choice is the range of functionaries that include datapreparation, model training, and evaluation. This means everything from datapreparation to model deployment.
The tables have the following row counts: Customers: 2 rows Orders: 4 rows Order products: 16 rows Order events: 26 rows Notifications: 10 rows Notification interactions: 15 rows Datapreparation and filtering: Datapreparation involves removing incorrect or outlier data.
Classification algorithms are some of the most useful machine learning models in use today. A confusion matrix is a chart that compares the predicted labels of a classification algorithm to their actual value. Confusion matrices do just that for classification algorithms. Many classification tasks naturally involve imbalance.
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
With data visualization capabilities, advanced statistical analysis methods and modeling techniques, IBM SPSS Statistics enables users to pursue a comprehensive analytical journey from datapreparation and management to analysis and reporting. How to integrate SPSS Statistics with R and Python?
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
It became apparent that the default Kubernetes scheduler algorithm was the culprit. The algorithm is (cpu((capacity-sum(requested))*MaxNodeScore/capacity) + memory((capacity-sum(requested))*MaxNodeScore/capacity))/weightSum. While it provided some improvements, it did not fundamentally resolve the issue.
Figure 4: The ModelOps process [Wikipedia] The Machine Learning Workflow Machine learning requires experimenting with a wide range of datasets, datapreparation, and algorithms to build a model that maximizes some target metric(s). There is no standard way to package and deploy models. References [1] J. Damji and M. 19, 2021. [2]
DataPreparation Here we use a subset of the ImageNet dataset (100 classes). You can follow command below to download the data. Data Insert This step uses an Insert Pipeline to insert image embeddings into Milvus collection. Search pipeline Preprocess the query image following the same steps as datapreparation.
Using innovative approaches and advanced algorithms, participants modeled scenarios accounting for starting grid positions, driver performance, and unpredictable race conditions like weather changes or mid-race interruptions. His focus on track-specific insights and comprehensive datapreparation set the model apart.
Unfortunately, even the datascience industry — which should recognize tabular data’s true value — often underestimates its relevance in AI. Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication.
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In this tutorial, you will learn how to implement a predictive maintenance system using the Isolation Forest algorithm — a well-known algorithm for anomaly detection. And Why Anomaly Detection?
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and datascience experience who wanted to implement MLOps. Join thousands of data leaders on the AI newsletter.
Boomi’s datascience team implemented a Markov chain model that could be applied to common integration sequences, or steps, on their platform, hence the name Step Suggest. The datascience team at Boomi applied the Markov Chain approach to the Step Suggest problem by treating integration steps as states in a state machine.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. The BlazingText algorithm expects a single preprocessed text file with space-separated tokens. If you are prompted to choose a Kernel, choose the Python 3 (DataScience 3.0) kernel and choose Select.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Summary: Demystify time complexity, the secret weapon for Data Scientists. Choose efficient algorithms, optimize code, and predict processing times for large datasets. Explore practical examples, tools, and future trends to conquer big data challenges. brute-force search algorithms).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































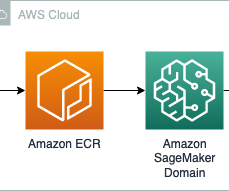









Let's personalize your content