This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
14 Essential Git Commands for DataScientists • Statistics and Probability for Data Science • 20 Basic Linux Commands for Data Science Beginners • 3 Ways Understanding Bayes Theorem Will Improve Your Data Science • Learn MLOps with This Free Course • Primary Supervised Learning Algorithms Used in Machine Learning • DataPreparation with SQL Cheatsheet. (..)
As data science evolves and grows, the demand for skilled datascientists is also rising. A datascientist’s role is to extract insights and knowledge from data and to use this information to inform decisions and drive business growth.
Today’s question is, “What does a datascientist do.” ” Step into the realm of data science, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of datascientists.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, data modeling, and data visualization.
By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics. Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
Applied Data Science However, Applied Data Science, a subset of Data Science, offers a more practical and industry-specific approach. But what are the key concepts and methodologies involved in Applied Data Science? An Applied DataScientist must have a solid understanding of statistics to interpret data correctly.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. And Why did it happen?). or What might be the best course of action?
These tools provide a visual interface for building machine learning pipelines, making the process easier and more efficient for datascientists. The next step is to select the machine learning algorithm to be used for the model. This is where drag-and-drop tools come in.
This is because decision intelligence platforms can use machine learning algorithms to identify patterns and trends in data. Let’s imagine that, a manufacturing company uses decision intelligence to track data on machine performance. However, there are some key differences between the two fields.
Summary: Demystify time complexity, the secret weapon for DataScientists. Choose efficient algorithms, optimize code, and predict processing times for large datasets. Explore practical examples, tools, and future trends to conquer big data challenges. brute-force search algorithms).
Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production.
Datascientists dedicate a significant chunk of their time to datapreparation, as revealed by a survey conducted by the data science platform Anaconda. This process involves rectifying or discarding abnormal or non-standard data points and ensuring the accuracy of measurements.
By providing an integrated environment for datapreparation, machine learning, and collaborative analytics, Dataiku empowers teams to harness the full potential of their data without requiring extensive technical expertise. The platform allows datascientists, analysts, and business stakeholders to work together seamlessly.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Be sure to check out her talk, “ Hands-on Data-Centric AI: Datapreparation tuning — why and how? Given that data has higher stakes , it only means that you should invest most of your development investment in improving your data quality.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
By Carolyn Saplicki , IBM DataScientist Industries are constantly seeking innovative solutions to maximize efficiency, minimize downtime, and reduce costs. Each of these accelerators leverages state-of-the-art algorithms and machine learning techniques to identify anomalies accurately and in real-time.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
MLOps acts as the link between datascientists and the production team’s operations (a team consisting of machine learning engineers, software engineers, and IT operations professionals) as they work together to develop ML models and supervise the use of ML models in production. They might also help with datapreparation and cleaning.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together datascientists to tackle one of the most dynamic aspects of racing — pit stop strategies. Yunus secured third place by delivering a flexible, well-documented solution that bridged data science and Formula 1 strategy.
This post is co-written with Swagata Ashwani, Senior DataScientist at Boomi. However, the underlying algorithm for Step Suggest is complicated and proprietary. SageMaker has built-in support for several popular ML algorithms, but Boomi already had a working solution.
It covers everything from datapreparation and model training to deployment, monitoring, and maintenance. The MLOps process can be broken down into four main stages: DataPreparation: This involves collecting and cleaning data to ensure it is ready for analysis.
This integration of model development and sharing creates a tighter collaboration between business and data science teams and lowers time to value. Business teams can use existing models built by their datascientists or other departments to solve a business problem instead of rebuilding new models in outside environments.
With SageMaker MLOps tools, teams can easily train, test, troubleshoot, deploy, and govern ML models at scale to boost productivity of datascientists and ML engineers while maintaining model performance in production. However, innovation was hampered due to using fragmented AI development environments across teams.
IBM® SPSS Statistics is a leading comprehensive statistical software that provides predictive models and advanced statistical techniques to derive actionable insights from data. For many businesses, research institutions, datascientists, data analyst experts and statisticians, SPSS Statistics is the standard for statistical analysis.
It also enables you to evaluate the models using advanced metrics as if you were a datascientist. We explain the metrics and show techniques to deal with data to obtain better model performance. Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the datascientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. The platform’s strength lies in its ability to abstract away the complexities of infrastructure management, allowing you to focus on innovation rather than operational overhead.
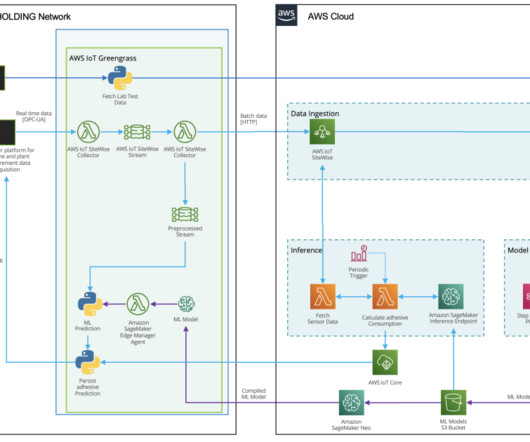
Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage. Because the data is being fetched hourly, a mechanism is also required to orchestrate and schedule ingestion jobs. Data comes from disparate sources in a number of formats.
Figure 4: The ModelOps process [Wikipedia] The Machine Learning Workflow Machine learning requires experimenting with a wide range of datasets, datapreparation, and algorithms to build a model that maximizes some target metric(s).
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Data ingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Model training and optimization with SageMaker automatic model tuning Prior to the model training, a set of datapreparation activities are performed.
Datascientists and developers can quickly prototype and experiment with various ML use cases, accelerating the development and deployment of ML applications. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
Datapreparation For this example, you will use the South German Credit dataset open source dataset. After you have completed the datapreparation step, it’s time to train the classification model. An experiment collects multiple runs with the same objective.
This means empowering business analysts to use ML on their own, without depending on data science teams. Canvas helps business analysts apply ML to common business problems without having to know the details such as algorithm types, training parameters, or ensemble logic.
Vertex AI assimilates workflows from data science, data engineering, and machine learning to help your teams work together with a shared toolkit and grow your apps with the help of Google Cloud. Conclusion Vertex AI is a major improvement over Google Cloud’s machine learning and data science solutions.
The rise of advanced technologies such as Artificial Intelligence (AI), Machine Learning (ML) , and Big Data analytics is reshaping industries and creating new opportunities for DataScientists. Automated Machine Learning (AutoML) will democratize access to Data Science tools and techniques.
Business organisations worldwide depend on massive volumes of data that require DataScientists and analysts to interpret to make efficient decisions. Understanding the appropriate ways to use data remains critical to success in finance, education and commerce. What is Data Mining and how is it related to Data Science ?
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. If you have administrator access to the account, no additional action is required.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content