This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics. Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
It’s an integral part of data analytics and plays a crucial role in data science. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
Financial services In the financial sector, synthetic credit card transaction data is utilized for fraud detection. This approach enables companies to develop algorithms that identify suspicious patterns without exposing sensitive data during the training phase.
One of the most popular algorithms in Machine Learning are the DecisionTrees that are useful in regression and classification tasks. Decisiontrees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning. How DecisionTreeAlgorithm works?
In the world of Machine Learning and Data Analysis , decisiontrees have emerged as powerful tools for making complex decisions and predictions. These tree-like structures break down a problem into smaller, manageable parts, enabling us to make informed choices based on data. What is a DecisionTree?
Feature Engineering is a process of using domain knowledge to extract and transform features from raw data. These features can be used to improve the performance of Machine Learning Algorithms. Normalization A feature scaling technique is often applied as part of datapreparation for machine learning.
Applied Data Science However, Applied Data Science, a subset of Data Science, offers a more practical and industry-specific approach. But what are the key concepts and methodologies involved in Applied Data Science? Machine learning algorithms Machine learning forms the core of Applied Data Science.
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
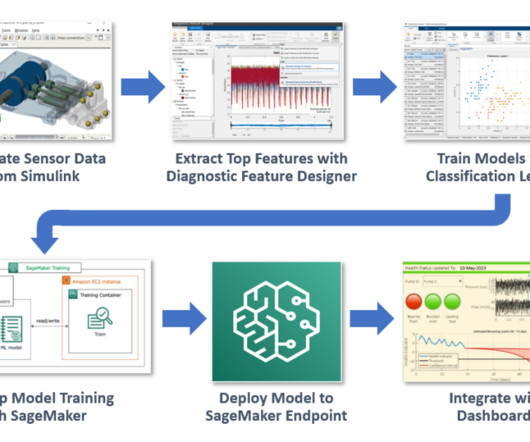
We have access to a large repository of labeled data generated from a Simulink simulation that has three possible fault types in various possible combinations (for example, one healthy and seven faulty states). The model can be tuned to match operational data from our real pump using parameter estimation techniques in MATLAB and Simulink.
Using innovative approaches and advanced algorithms, participants modeled scenarios accounting for starting grid positions, driver performance, and unpredictable race conditions like weather changes or mid-race interruptions. His focus on track-specific insights and comprehensive datapreparation set the model apart.
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In this tutorial, you will learn how to implement a predictive maintenance system using the Isolation Forest algorithm — a well-known algorithm for anomaly detection. And Why Anomaly Detection?
Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Importance of Data in AI Quality data is the lifeblood of AI models, directly influencing their performance and reliability.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data.
Summary: XGBoost is a highly efficient and scalable Machine Learning algorithm. It combines gradient boosting with features like regularisation, parallel processing, and missing data handling. Key Features of XGBoost XGBoost (eXtreme Gradient Boosting) has earned its reputation as a powerful and efficient Machine Learning algorithm.
Alteryx’s Capabilities Data Blending: Effortlessly combine data from multiple sources. Predictive Analytics: Leverage machine learning algorithms for accurate predictions. This makes Alteryx an indispensable tool for businesses aiming to glean insights and steer their decisions based on robust data.
It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. DataPreparation: Cleaning and transforming raw data to make it usable for machine learning. Model Training: Running computations to learn from the data.
Summary: Predictive analytics utilizes historical data, statistical algorithms, and Machine Learning techniques to forecast future outcomes. This blog explores the essential steps involved in analytics, including data collection, model building, and deployment. What is Predictive Analytics?
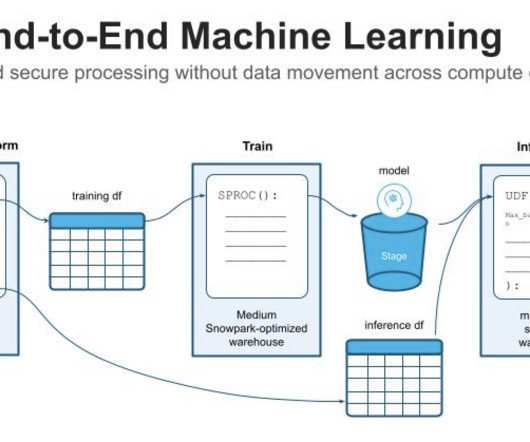
Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering. Datapreparation To extract data efficiently for training and testing, we utilize Amazon Athena and the AWS Glue Data Catalog.
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. This results in quite efficient sales data predictions. In its core, lie gradient-boosted decisiontrees.
With a modeled estimation of the applicant’s credit risk, lenders can make more informed decisions and reduce the occurrence of bad loans, thereby protecting their bottom line. These nuanced algorithms can lead to more accurate and reliable credit scores and decisions. loan default or not).
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
They provide a comprehensive environment for designing algorithms, simulating their performance, and generating code for deployment on various hardware platforms. Simulation Capabilities: Users can simulate AI algorithms within their models to evaluate performance before deployment. Model Selection : Choose appropriate algorithms (e.g.,
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Domain knowledge is crucial for effective data application in industries. What is Data Science and Artificial Intelligence? Data Science is an interdisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data.
They identify patterns in existing data and use them to predict unknown events. Techniques like linear regression, time series analysis, and decisiontrees are examples of predictive models. Popular clustering algorithms include k-means and hierarchical clustering. Datapreparation also involves feature engineering.
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform Exploratory Data Analysis to uncover patterns and insights hidden within the data. This phase entails meticulously selecting and training algorithms to ensure optimal performance.
Lesson 1: Mitigating data sparsity problems within ML classification algorithms What are the most popular algorithms used to solve a multi-class classification problem? So, the model might not have a sufficient number of data samples to learn the pattern for each class. Let’s take a look at some of them.
The Current State of Data Science Data Science today is characterised by its integration with various technologies and methodologies that enhance its capabilities. The field has evolved significantly from traditional statistical analysis to include sophisticated Machine Learning algorithms and Big Data technologies.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. It is designed to leverage hardware acceleration (e.g.,
Check out the previous post to get a primer on the terms used) Outline Dealing with Class Imbalance Choosing a Machine Learning model Measures of Performance DataPreparation Stratified k-fold Cross-Validation Model Building Consolidating Results 1. DataPreparation Photo by Bonnie Kittle […]
Machine learning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. What are machine learning algorithms? Regression: Focuses on predicting continuous values, such as forecasting sales or estimating property prices.
CatBoost is quickly becoming a go-to algorithm in the machine learning landscape, particularly for its innovative approach to handling categorical data. The algorithms efficacy in small datasets and rapid training capabilities set it apart from other models, particularly in scenarios involving categorical features.
It uses unlabeled data where only inputs are given without any predefined outputs. The ML algorithm tries to find hidden patterns and structures in this data. It groups similar data points or identifies outliers without prior guidance. Unsupervised learning deals with data that has not been labeled.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content