This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
Overview Introduction to Natural Language Generation (NLG) and related things- DataPreparation Training Neural Language Models Build a Natural Language Generation System using PyTorch. The post Build a Natural Language Generation (NLG) System using PyTorch appeared first on Analytics Vidhya.
Financial services In the financial sector, synthetic credit card transaction data is utilized for fraud detection. This approach enables companies to develop algorithms that identify suspicious patterns without exposing sensitive data during the training phase.
Introduction to DeepLearningAlgorithms: Deeplearningalgorithms are a subset of machine learning techniques that are designed to automatically learn and represent data in multiple layers of abstraction. This process is known as training, and it relies on large amounts of labeled data.
It’s an integral part of data analytics and plays a crucial role in data science. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
Applied Data Science However, Applied Data Science, a subset of Data Science, offers a more practical and industry-specific approach. But what are the key concepts and methodologies involved in Applied Data Science? Machine learningalgorithms Machine learning forms the core of Applied Data Science.
The process of building a machine learning pipeline with a drag-and-drop tool usually starts with selecting the data source. Once the data source is selected, the user can then add preprocessing steps to clean and prepare the data. The next step is to select the machine learningalgorithm to be used for the model.
Source: Author Introduction Deeplearning, a branch of machine learning inspired by biological neural networks, has become a key technique in artificial intelligence (AI) applications. Deeplearning methods use multi-layer artificial neural networks to extract intricate patterns from large data sets.
The scope of LLMOps within machine learning projects can vary widely, tailored to the specific needs of each project. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. This includes tokenizing the data, removing stop words, and normalizing the text.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization.
They are effective in face recognition, image similarity, and one-shot learning but face challenges like high computational costs and data imbalance. Introduction Neural networks form the backbone of DeepLearning , allowing machines to learn from data by mimicking the human brain’s structure.
Instead, we use pre-trained deeplearning models like VGG or ResNet to extract feature vectors from the images. Image retrieval search architecture The architecture follows a typical machine learning workflow for image retrieval. DataPreparation Here we use a subset of the ImageNet dataset (100 classes).
By leveraging machine learning techniques, businesses can significantly reduce downtime and maintenance costs, ensuring smoother and more efficient operations. One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. Let’s understand the Isolation Forest algorithm in detail.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
Common mistakes and misconceptions about learning AI/ML Markus Spiske on Unsplash A common misconception of beginners is that they can learn AI/ML from a few tutorials that implement the latest algorithms, so I thought I would share some notes and advice on learning AI. Trying to code ML algorithms from scratch.
The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. Deeplearning model architecture design We design a Triple Tower Deep Pointwise (TTDP) model using a triple-tower deeplearning architecture and the pointwise pair modeling approach.
Machine learning practitioners tend to do more than just create algorithms all day. First, there’s a need for preparing the data, aka data engineering basics. As the chart shows, two major themes emerged.
Random Projection The first step in the algorithm is to sample random vectors in the same -dimensional space as input vector. We will start by setting up libraries and datapreparation. Setting Up Baseline with the k-NN Algorithm With our word embeddings ready, let’s implement a -Nearest Neighbors (k-NN) search. -NN
Companies that work on machine learning for health care, like Google, create large groups of medical images selected by physicians. Machine learningalgorithms use these sets of visual data to look for statistical patterns to identify which image features allow you to assume that it is worthy of a particular label or diagnosis.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms.
First, we have data scientists who are in charge of creating and training machine learning models. They might also help with datapreparation and cleaning. The machine learning engineers are in charge of taking the models developed by data scientists and deploying them into production.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
Feature engineering activities frequently focus on single-table data transformations, leading to the infamous “yawn factor.” Let’s be honest — one-hot-encoding isn’t the most thrilling or challenging task on a data scientist’s to-do list. One might say that tabular data modeling is the original data-centric AI!
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work.
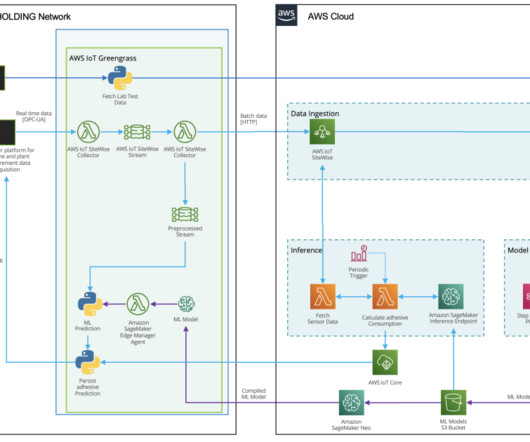
Data ingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Model training and optimization with SageMaker automatic model tuning Prior to the model training, a set of datapreparation activities are performed.
However, the underlying algorithm for Step Suggest is complicated and proprietary. SageMaker has built-in support for several popular ML algorithms, but Boomi already had a working solution. The exact steps to replicate this process are outlined Train and deploy deeplearning models using JAX with Amazon SageMaker.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
The two most common types of supervised learning are classification , where the algorithm predicts a categorical label, and regression , where the algorithm predicts a numerical value. Unsupervised Learning In this type of learning, the algorithm is trained on an unlabeled dataset, where no correct output is provided.
They provide a comprehensive environment for designing algorithms, simulating their performance, and generating code for deployment on various hardware platforms. Simulation Capabilities: Users can simulate AI algorithms within their models to evaluate performance before deployment. Model Selection : Choose appropriate algorithms (e.g.,
Recent years have shown amazing growth in deeplearning neural networks (DNNs). Another way can be to use an AllReduce algorithm. For example, in the ring-allreduce algorithm, each node communicates with only two of its neighboring nodes, thereby reducing the overall data transfers.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
RapidMiner RapidMiner, a renowned player in the realm of machine learning tools, offers an all-encompassing platform for a myriad of operations. Its functionalities span from deeplearning to text mining, datapreparation, and predictive analytics, ensuring a versatile utility for developers and data scientists alike.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Looking for the source code to this post?
Thirdly, the presence of GPUs enabled the labeled data to be processed. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deeplearning. In order to train transformer models on internet-scale data, huge quantities of PBAs were needed.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learningalgorithms and effective data handling are also critical for success in the field.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML. Choose Create.
For many years, Philips has been pioneering the development of data-driven algorithms to fuel its innovative solutions across the healthcare continuum. Also in patient monitoring, image guided therapy, ultrasound and personal health teams have been creating ML algorithms and applications.
MMPose is a member of the OpenMMLab Project and contains a rich set of algorithms for 2D multi-person human pose estimation, 2D hand pose estimation, 2D face landmark detection, and 133 keypoint whole-body human pose estimations. This instance will be used for various tasks such as video processing and datapreparation.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
The Ranking team at Booking.com plays a pivotal role in ensuring that the search and recommendation algorithms are optimized to deliver the best results for their users. Training optimization The rise of deeplearning (DL) has led to ML becoming increasingly reliant on computational power and vast amounts of data.
Understanding LLM chatbots Back to basics: Understanding Large Language Models LLM, standing for Large Language Model, represents an advanced language model that undergoes training on an extensive corpus of text data. The Fine-tuning Workflow with LangChain DataPreparation Customize your dataset to fine-tune an LLM for your specific task.
Summary: Demystify time complexity, the secret weapon for Data Scientists. Choose efficient algorithms, optimize code, and predict processing times for large datasets. Explore practical examples, tools, and future trends to conquer big data challenges. brute-force search algorithms).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content