

Implementing Approximate Nearest Neighbor Search with KD-Trees
PyImageSearch
DECEMBER 23, 2024
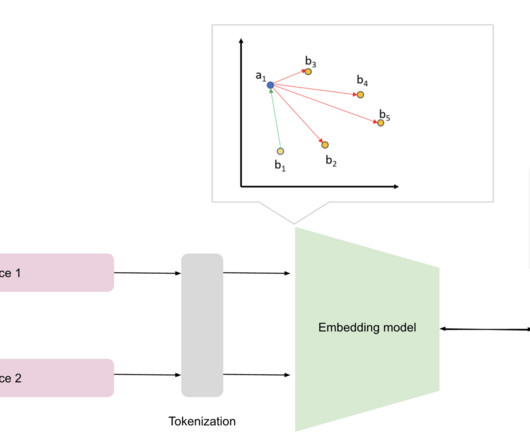
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.












































Let's personalize your content