This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This process is typically facilitated by document loaders, which provide a “load” method for accessing and loading documents into the memory. This involves splitting lengthy documents into smaller chunks that are compatible with the model and produce accurate and clear results.
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
The significance of RAG is underscored by its ability to reduce hallucinationsinstances where AI generates incorrect or nonsensical informationby retrieving relevant documents from a vast corpora. Document Retrieval: The retriever processes the query and retrieves relevant documents from a pre-defined corpus.
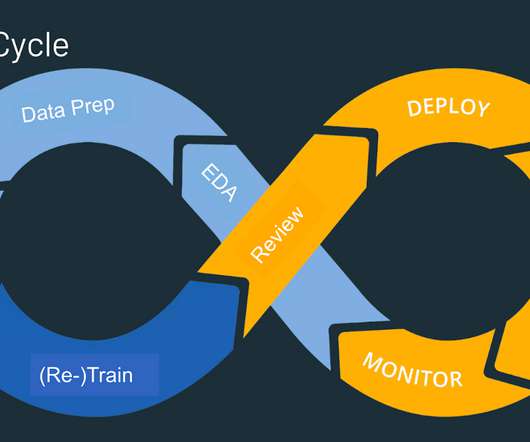
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. Dataset preparation for visual question and answering tasks The Meta Llama 3.2
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. Search for the most relevant documents given the query “Fun animal toy” search("Fun animal toy", embeddings, docs) The following screenshots show the output. jpg") or doc.endswith(".png"))
With data software pushing the boundaries of what’s possible in order to answer business questions and alleviate operational bottlenecks, data-driven companies are curious how they can go “beyond the dashboard” to find the answers they are looking for. One of the standout features of Dataiku is its focus on collaboration.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more. While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
For example, Scikit-learn can be used to: Classify customer churn Predict product sales Cluster customer segments Reduce the dimensionality of a dataset Select features for a machine learning model Notable features and capabilities Scikit-learn has a number of notable features and capabilities, including: A wide range of machine learning algorithms (..)
Another example is in the field of text document similarity. Imagine you have a vast library of documents and want to identify near-duplicate documents or find documents similar to a query document. Developed by Moses Charikar, SimHash is particularly effective for high-dimensional data (e.g.,
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. This allows for better monitoring and auditing.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. Text classification is essential for applications like web searches, information retrieval, ranking, and document classification. You now run the datapreparation step in the notebook.
It became apparent that the default Kubernetes scheduler algorithm was the culprit. The algorithm is (cpu((capacity-sum(requested))*MaxNodeScore/capacity) + memory((capacity-sum(requested))*MaxNodeScore/capacity))/weightSum. The k8s documentation on the built-in constraints is here.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Using innovative approaches and advanced algorithms, participants modeled scenarios accounting for starting grid positions, driver performance, and unpredictable race conditions like weather changes or mid-race interruptions. His focus on track-specific insights and comprehensive datapreparation set the model apart.
The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. We use the standard engineered features as input into the interaction encoder and feed the SBERT derived embedding into the query encoder and document encoder.
Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage. Because the data is being fetched hourly, a mechanism is also required to orchestrate and schedule ingestion jobs. Data comes from disparate sources in a number of formats.
For example, a use case that’s been moved from the QA stage to pre-production could be rejected and sent back to the development stage for rework because of missing documentation related to meeting certain regulatory controls. Datapreparation For this example, you will use the South German Credit dataset open source dataset.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
For many years, Philips has been pioneering the development of data-driven algorithms to fuel its innovative solutions across the healthcare continuum. Also in patient monitoring, image guided therapy, ultrasound and personal health teams have been creating ML algorithms and applications.
Community Support and Documentation A strong community around the platform can be invaluable for troubleshooting issues, learning new techniques, and staying updated on the latest advancements. Assess the quality and comprehensiveness of the platform's documentation. In finance, it's applied for fraud detection and algorithmic trading.
First, we have data scientists who are in charge of creating and training machine learning models. They might also help with datapreparation and cleaning. The machine learning engineers are in charge of taking the models developed by data scientists and deploying them into production.
Datapreparation and training The datapreparation and training pipeline includes the following steps: The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time. Get started today by referring to the GitHub repository.
Another way can be to use an AllReduce algorithm. For example, in the ring-allreduce algorithm, each node communicates with only two of its neighboring nodes, thereby reducing the overall data transfers. For training data, we used the MNIST dataset of handwritten digits. alpha – L1 regularization term on weights.
Data Which Fuels AI is Derived through Image Annotation A computer program or algorithm that interprets data, analyzes patterns or recognizes trends is known as artificial intelligence. In order to achieve this, one must understand the algorithms and be able to apply them to real-world challenges through AI.
Gather data from various sources, such as Confluence documentation and PDF reports. The Fine-tuning Workflow with LangChain DataPreparation Customize your dataset to fine-tune an LLM for your specific task. Step 1: Organizing knowledge base Break down your knowledge base into smaller, manageable chunks.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. This includes features for data labeling, data versioning, data augmentation, and integration with popular data storage systems.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Implementing best practices can improve performance, reduce costs, and improve data quality. This section outlines key practices focused on automation, monitoring and optimisation, scalability, documentation, and governance. By adopting these best practices, organisations can significantly enhance the efficiency of their ETL processes.
This helps with datapreparation and feature engineering tasks and model training and deployment automation. In both LSA and LDA, each document is treated as a collection of words only and the order of the words or grammatical role does not matter, which may cause some information loss in determining the topic.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. With Amazon Kendra, you can find relevant answers to your questions quickly, without sifting through documents.
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Data science practitioners experiment with algorithms, data, and hyperparameters to develop a model that generates business insights.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
Summary: XGBoost is a highly efficient and scalable Machine Learning algorithm. It combines gradient boosting with features like regularisation, parallel processing, and missing data handling. Key Features of XGBoost XGBoost (eXtreme Gradient Boosting) has earned its reputation as a powerful and efficient Machine Learning algorithm.
HNSW stands for Hierarchical Navigable Small World, a graph-based algorithm that excels in vector similarity search. Install Genkit: Integrate Genkit into your project by following the installation instructions provided in the Genkit documentation. Implementing HNSW Vector index What is HNSW? Then import the plugin into the file.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. An LLM’s eventual quality significantly depends on the selection and curation of the training data. Note that effective in NCCL 2.12
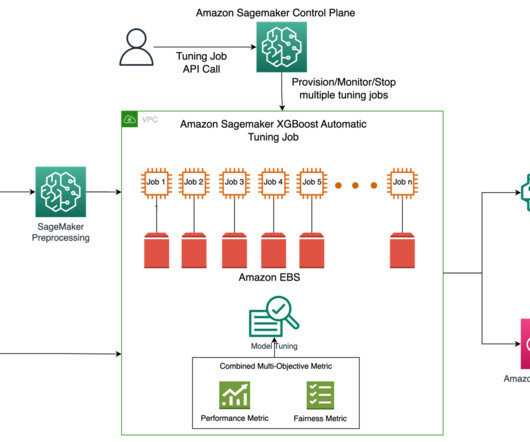
For example, Fairness – The aim here is to encourage models to mitigate bias in model outcomes between certain sub-groups in the data, especially when humans are subject to algorithmic decisions. Amazon SageMaker Clarify can detect potential bias during datapreparation, after model training, and in your deployed model.
Data management is not yet a solved problem, but modern data management is leagues ahead of prior approaches. These include tracking, documenting, monitoring, versioning, and controlling access to AI/ML models. ML uses massive amounts of data to learn, which was not economically possible until the last ten years.
The ML platform can utilize historic customer engagement data, also called “clickstream data”, and transform it into features essential for the success of the search platform. From an algorithmic perspective, Learning To Rank (LeToR) and Elastic Search are some of the most popular algorithms used to build a Seach system.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content