This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
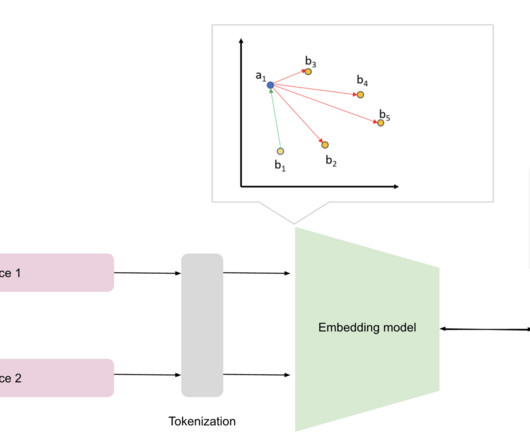
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
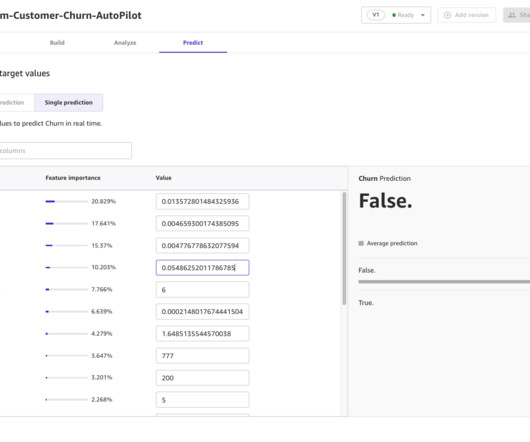
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Load the data in an Amazon SageMaker Studio notebook. Set up a SageMaker domain.
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In this tutorial, you will learn how to implement a predictive maintenance system using the Isolation Forest algorithm — a well-known algorithm for anomaly detection. And Why Anomaly Detection?
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. The platform’s strength lies in its ability to abstract away the complexities of infrastructure management, allowing you to focus on innovation rather than operational overhead.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Sagemaker provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment.
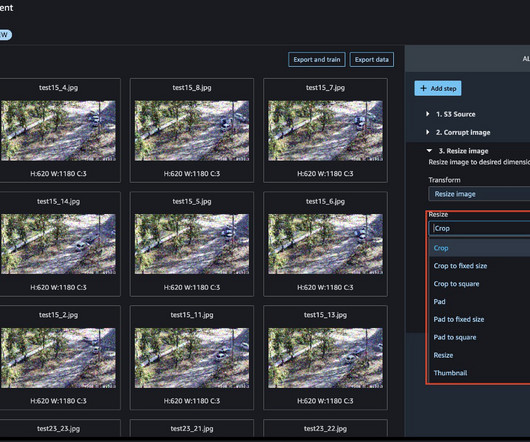
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import. This can take a few minutes.
Jump Right To The Downloads Section What Is Locality Sensitive Hashing (LSH)? Random Projection The first step in the algorithm is to sample random vectors in the same -dimensional space as input vector. We will start by setting up libraries and datapreparation. Looking for the source code to this post?
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
DataPreparation Here we use a subset of the ImageNet dataset (100 classes). You can follow command below to download the data. Data Insert This step uses an Insert Pipeline to insert image embeddings into Milvus collection. Search pipeline Preprocess the query image following the same steps as datapreparation.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
MMPose is a member of the OpenMMLab Project and contains a rich set of algorithms for 2D multi-person human pose estimation, 2D hand pose estimation, 2D face landmark detection, and 133 keypoint whole-body human pose estimations. You can download and install Docker from Docker’s official website. AWS SAM CLI – Install the AWS SAM CLI.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing.
introduces a wide range of capabilities designed to improve every stage of data analysis—from datapreparation to dashboard consumption. In addition, the new relevance algorithm intelligently corrects for common issues like misspellings, spacing, and punctuation. To learn more, read View Underlying Data in Tableau Help.
introduces a wide range of capabilities designed to improve every stage of data analysis—from datapreparation to dashboard consumption. In addition, the new relevance algorithm intelligently corrects for common issues like misspellings, spacing, and punctuation. To learn more, read View Underlying Data in Tableau Help.
This means empowering business analysts to use ML on their own, without depending on data science teams. Canvas helps business analysts apply ML to common business problems without having to know the details such as algorithm types, training parameters, or ensemble logic.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection?
Now let’s assume the role of a data scientist who is looking to train, build, deploy, and share ML models with a business analyst for each of these three architectural patterns. Download the abalone dataset from Kaggle. In this example, we use the abalone dataset downloaded from LIBSVM.
Moreover, the library can be downloaded in its entirety from reliable sources such as GitHub at no cost, ensuring its accessibility to a wide range of developers. Its functionalities span from deep learning to text mining, datapreparation, and predictive analytics, ensuring a versatile utility for developers and data scientists alike.
Another way can be to use an AllReduce algorithm. For example, in the ring-allreduce algorithm, each node communicates with only two of its neighboring nodes, thereby reducing the overall data transfers. For training data, we used the MNIST dataset of handwritten digits. alpha – L1 regularization term on weights.
Users can download datasets in formats like CSV and ARFF. It provides high-quality, curated data, often with associated tasks and domain-specific challenges, which helps bridge the gap between theoretical ML algorithms and real-world problem-solving. CSV, ARFF) to begin the download.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
I then decide to build a machine learning algorithm that is capable of naming some Yoruba traditional textiles which are Ankara, Aso oke, Atiku, and lace textiles using their images. I downloaded 50 samples from each, but something unfortunate happened — all the images I collected got deleted! In total, I downloaded about 200 images.
Typically, dense vector embeddings and similarity search algorithms (e.g., Instead of relying on static datasets, it uses GPT-4 to generate instruction-following data across diverse scenarios. It searches a structured or unstructured knowledge base to find the most relevant pieces of information related to a user query.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. For more information, refer to Granting Data Catalog permissions using the named resource method. amazonaws.com docker build -t.
They use advanced algorithms to proactively identify and resolve network issues, reducing downtime and improving service to their subscribers. All that time spent on datapreparation has an opportunity cost associated with it. Data Governance Drives Insights Data governance provides an important framework.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML.
Step 1: Clone Repository and Download Requirements To begin with, you need to clone the official YoloV7 repository as follows: $ git clone [link] Note: If you do not have Git installed in your system, then you can download and install it from here and then run the above command, or you can download the code in zip format from here.
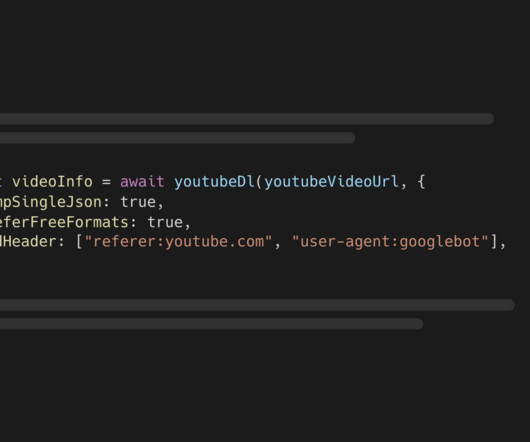
youtube-dl-exec wraps the yt-dlp CLI tool which lets you retrieve information about YouTube videos and download them. Implement some algorithms from scratch in Python to better understand concepts. Do Kaggle's intro and intermediate ML courses to learn more datapreparation with Pandas.
Solution overview In this solution, we start with datapreparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the Amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors.
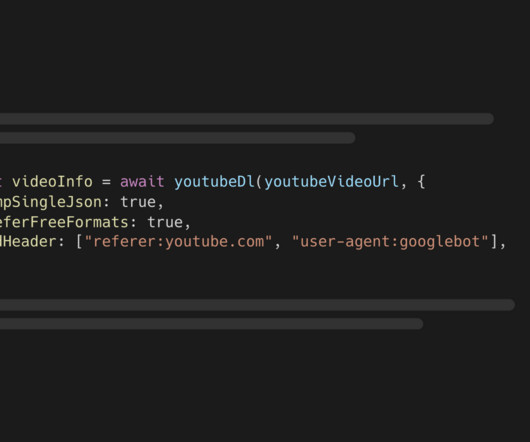
youtube-dl-exec wraps the yt-dlp CLI tool which lets you retrieve information about YouTube videos and download them. Implement some algorithms from scratch in Python to better understand concepts. Do Kaggle's intro and intermediate ML courses to learn more datapreparation with Pandas.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. An LLM’s eventual quality significantly depends on the selection and curation of the training data. Note that effective in NCCL 2.12
Understanding Embedding Models Embedding models are generally neural network algorithms that generate embeddings when an input is provided. Specifically, we will be looking into how to fine-tune an embedding model for retrieving relevant data and queries. The dataset must be well must be well curated.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
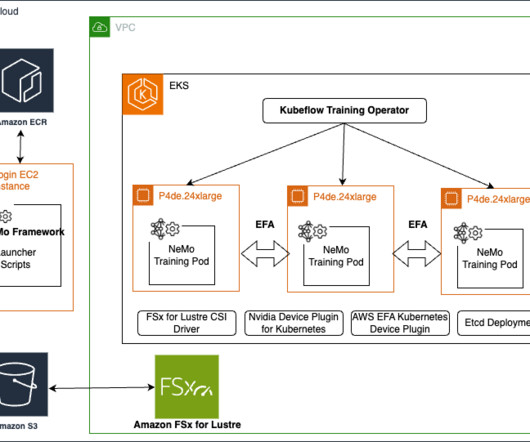
These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. To get around this, you can put the launcher scripts in the head node and the results and data folder in the file system that the compute nodes have access to.
DataPreparation The Training dataset is labeled as per Pascal VOC format (XML files) PASCAL-VOC Format. Installation Installation is quite simple* Clone the library* Run installation script Support available for▹ Python — 3.6▹ Cuda — 9.0, Runs on colab too!!!
At its core, NeMo Framework provides model builders with: Comprehensive development tools : A complete ecosystem of tools, scripts, and proven recipes that guide users through every phase of the LLM lifecycle, from initial datapreparation to final deployment. SageMaker HyperPod uses lifecycle scripts to bootstrap a cluster.
After you download the code base, you can deploy the project following the instructions outlined in the GitHub repo. Dataset preparation consists of the following key steps: Data acquisition – We begin by downloading a collection of games in PGN format from publicly available PGN files on the PGN mentor program website.
Autoencoders as Anomaly Detection Algorithms Why Choose Variational Autoencoders (VAEs)? Jump Right To The Downloads Section Understanding Network Intrusion and the Role of Anomaly Detection Imagine a scenario where a large financial institution suddenly notices an unusual spike in network traffic late at night.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
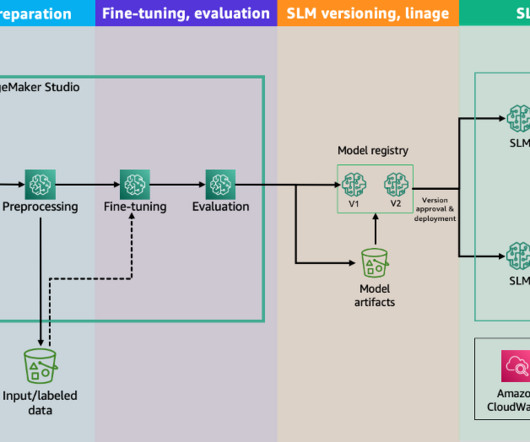
Solution overview This solution uses multiple features of SageMaker and Amazon Bedrock, and can be divided into four main steps: Data analysis and preparation – In this step, we assess the available data, understand how it can be used to develop solution, select data for fine-tuning, and identify required datapreparation steps.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content