This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction on AutoKeras Automated Machine Learning (AutoML) is a computerised way of determining the best combination of datapreparation, model, and hyperparameters for a predictive modelling task. The AutoML model aims to automate all actions which require more time, such as algorithm selection, […].
In this article, I describe 3 alternative algorithms to select predictive features based on a feature importance score. Feature selection methodologies go beyond filter, wrapper and embedded methods.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, data modeling, and data visualization.
However, certain technical skills are considered essential for a data scientist to possess. These skills include programming languages such as Python and R, statistics and probability, machine learning, data visualization, and data modeling.
Feature Engineering is a process of using domain knowledge to extract and transform features from raw data. These features can be used to improve the performance of Machine Learning Algorithms. Python, with its extensive libraries and tools, offers a streamlined and efficient process for simplifying feature scaling.
With data visualization capabilities, advanced statistical analysis methods and modeling techniques, IBM SPSS Statistics enables users to pursue a comprehensive analytical journey from datapreparation and management to analysis and reporting. How to integrate SPSS Statistics with R and Python?
With the most recent developments in machine learning , this process has become more accurate, flexible, and fast: algorithms analyze vast amounts of data, glean insights from the data, and find optimal solutions. Given the enormous volume of information which can reach petabytes efficient data handling is crucial.
Photo by SHVETS production from Pexels As per the routine I follow every time, here I am with the Python implementation of Causal Impact. The main goal of the algorithm is to infer the expected effect a given intervention (or any action) had on some response variable by analyzing differences between expected and observed time series data.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
PyTorch PyTorch is another open-source software library for numerical computation using data flow graphs. It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 Vision models.
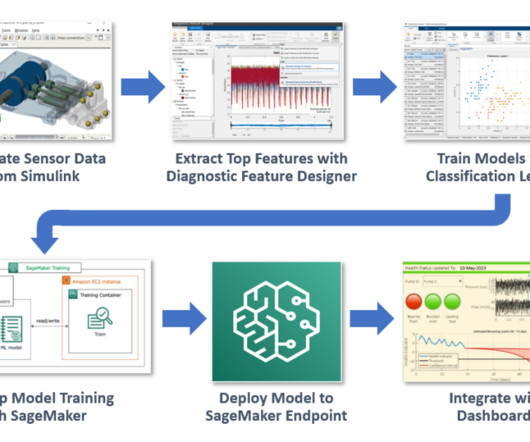
We have access to a large repository of labeled data generated from a Simulink simulation that has three possible fault types in various possible combinations (for example, one healthy and seven faulty states). The model can be tuned to match operational data from our real pump using parameter estimation techniques in MATLAB and Simulink.
DataPreparation Here we use a subset of the ImageNet dataset (100 classes). You can follow command below to download the data. Create a Milvus collection Define a schema for your collection in Milvus, specifying data types for image IDs and feature vectors (usually floats). Building the Image Search Pipeline 1.
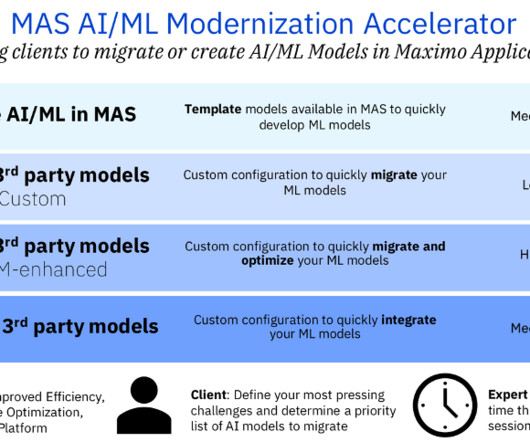
Each of these accelerators leverages state-of-the-art algorithms and machine learning techniques to identify anomalies accurately and in real-time. Solution 2: Migrate 3rd party models to MAS (Custom Model) This data science solution predicts anomalies in air compressor assets using an isolation forest model.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. The BlazingText algorithm expects a single preprocessed text file with space-separated tokens. If you are prompted to choose a Kernel, choose the Python 3 (Data Science 3.0) kernel and choose Select.
Machine learning practitioners tend to do more than just create algorithms all day. First, there’s a need for preparing the data, aka data engineering basics. As the chart shows, two major themes emerged.
While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. According to a 2019 survey by Deloitte , only 18% of businesses reported being able to take advantage of unstructured data. This will land on a data flow page. And select Python (PySpark).
Data scientists are the master keyholders, unlocking this portal to reveal the mysteries within. They wield algorithms like ancient incantations, summoning patterns from the chaos and crafting narratives from raw numbers. Model development : Crafting magic from algorithms! Work Works with larger, more complex data sets.
Tapping into these schemas and pulling out machine learning-ready features can be nontrivial as one needs to know where the data entity of interest lives (e.g., customers), what its relations are, and how they’re connected, and then write SQL, python, or other to join and aggregate to a granularity of interest.
Sagemaker provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment. FROM 246618743249.dkr.ecr.us-west-2.amazonaws.com/sagemaker-xgboost:1.5-1
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
MMPose is a member of the OpenMMLab Project and contains a rich set of algorithms for 2D multi-person human pose estimation, 2D hand pose estimation, 2D face landmark detection, and 133 keypoint whole-body human pose estimations. This instance will be used for various tasks such as video processing and datapreparation.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Its seamless integration capabilities make it highly compatible with numerous other Python libraries, which is why Scikit Learn is favored by many in the field for tackling sophisticated machine learning problems. PyTorch PyTorch, a Python-based machine learning library, stands out among its peers in the machine learning tools ecosystem.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Through the integration of Vertex AI with Google Earth Engine, users may gain access to sophisticated machine learning models and algorithms for more efficient analysis of Earth observation data. Conclusion Vertex AI is a major improvement over Google Cloud’s machine learning and data science solutions.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. Python script that serves as the entry point. client('s3') # Get the region name session = boto3.Session()
No Free Lunch Theorem: Any two algorithms are equivalent when their performance is averaged across all possible problems. MLOps is the intersection of Machine Learning, DevOps, and Data Engineering. Zero, “ How to write better scientific code in Python,” Towards Data Science, Feb. 15, 2022. [4]
Summary: Demystify time complexity, the secret weapon for Data Scientists. Choose efficient algorithms, optimize code, and predict processing times for large datasets. Explore practical examples, tools, and future trends to conquer big data challenges. brute-force search algorithms).
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. during the forecast period.
The training data used for this pipeline is made available through PrestoDB and read into Pandas through the PrestoDB Python client. The queries that are used to fetch data at training and batch inference steps are configured in the config file.
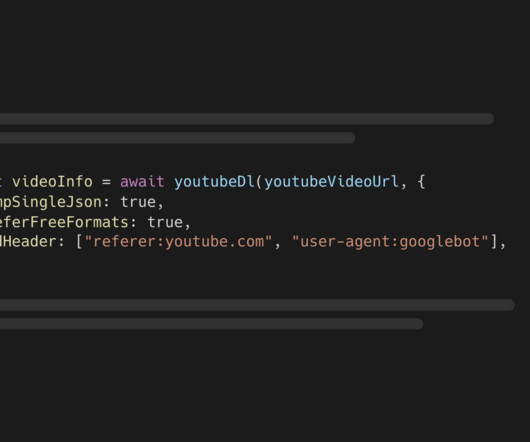
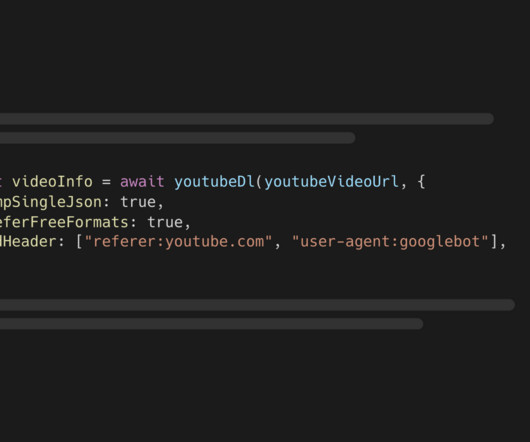
tsx lets you execute TypeScript code without additional setup npm install --save assemblyai youtube-dl-exec tsx You must also install Python 3.7 Learn Python - do a beginner and intermediate level course to get a solid base. Python skills are essential. Learn key machine learning Python libraries like NumPy, Pandas, Matplotlib.
Handle Non-Linearity: Decision trees can handle non-linear relationships between features, which many other algorithms struggle with. If a data point has a missing value for the selected attribute, the decision tree algorithm will consider the available data to make the split. time of day) for the initial split.
Building a chatbot using Python involves several steps. Install required libraries: Install the necessary Python libraries to build the chatbot. Prepare the training data: Prepare a set of training data that the chatbot can learn from. Train the chatbot: Use the training data to train the chatbot.
tsx lets you execute TypeScript code without additional setup npm install --save assemblyai youtube-dl-exec tsx You must also install Python 3.7 Learn Python - do a beginner and intermediate level course to get a solid base. Python skills are essential. Learn key machine learning Python libraries like NumPy, Pandas, Matplotlib.
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
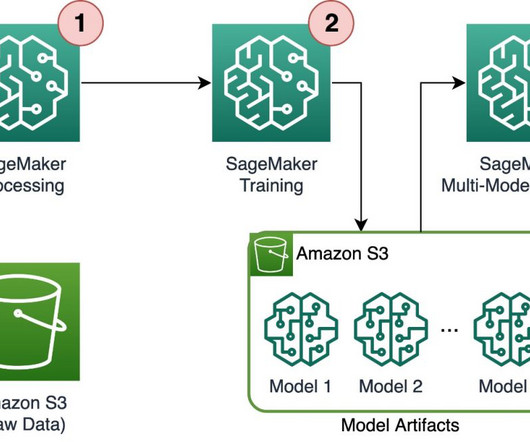
Solution overview To efficiently train and serve thousands of ML models, we can use the following SageMaker features: SageMaker Processing – SageMaker Processing is a fully managed datapreparation service that enables you to perform data processing and model evaluation tasks on your input data.
Low-Code PyCaret: Let’s start off with a low-code open-source machine learning library in Python. PyCaret allows data professionals to build and deploy machine learning models easily and efficiently. This frees up the data scientists to work on other aspects of their projects that might require a bit more attention.
Summary: XGBoost is a highly efficient and scalable Machine Learning algorithm. It combines gradient boosting with features like regularisation, parallel processing, and missing data handling. Key Features of XGBoost XGBoost (eXtreme Gradient Boosting) has earned its reputation as a powerful and efficient Machine Learning algorithm.
The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. Standard feature engineering Our datapreparation process begins with standard feature engineering. A crucial step in our datapreparation is the application of a pre-trained NER model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content