This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
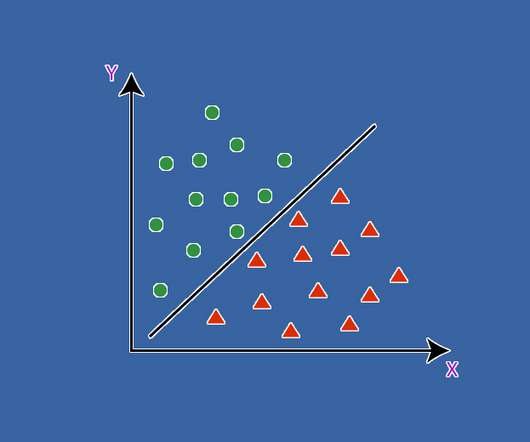
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction In this article, we will be discussing SupportVectorMachines. The post SupportVectorMachine: Introduction appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction to SupportVectorMachine(SVM) SVM is a powerful supervised algorithm that works best on smaller datasets but on complex ones.
This article was published as a part of the DataScience Blogathon Introduction Hello Everyone, I hope you are doing well. Ever wondered, how great would it be, if we could predict, whether our request for a loan, will be approved or not, simply by the use of machine learning, from the ease and comfort […].
This article was published as a part of the DataScience Blogathon. The post The Mathematics Behind SupportVectorMachineAlgorithm (SVM) appeared first on Analytics Vidhya. Introduction One of the classifiers that we come across while learning about.
This article was published as a part of the DataScience Blogathon. The post Understanding Naïve Bayes and SupportVectorMachine and their implementation in Python appeared first on Analytics Vidhya. Introduction In this digital world, spam is the most troublesome challenge that.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Source Overview In this article, we will learn the working of. The post Start Learning SVM (SupportVectorMachine) Algorithm Here! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Classification problems are often solved using supervised learning algorithms such as Random Forest Classifier, SupportVectorMachine, Logistic Regressor (for binary class classification) etc. One-Class […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction SupportVectorMachine (SVM) is one of the Machine Learning. The post The A-Z guide to SupportVectorMachine appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Supportvectormachine is one of the most famous and decorated machine learning algorithms in classification problems.
Datascience techniques are the backbone of modern analytics, enabling professionals to transform raw data into meaningful insights. By employing various methodologies, analysts uncover hidden patterns, predict outcomes, and supportdata-driven decision-making. What are datascience techniques?
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Before the sudden rise of neural networks, SupportVectorMachines. The post Top 15 Questions to Test your DataScience Skills on SVM appeared first on Analytics Vidhya.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithms learn from labeled data , similar to classification.
Top statistical techniques – DataScience Dojo Counterfactual causal inference: Counterfactual causal inference is a statistical technique that is used to evaluate the causal significance of historical events. These algorithms are often used to solve optimization problems, such as gradient descent and conjugate gradient.
Machine learning practices are the guiding principles that transform raw data into powerful insights. By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machine learning and pave the way for innovation and success.
In contemporary times, datascience has emerged as a substantial and progressively expanding domain that has an impact on virtually every sphere of human ingenuity: be it commerce, technology, healthcare, education, governance, and beyond. This piece will concentrate on the elemental constituents constituting datascience.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) datascience. This week, we continue that metaphorical (learning) journey with a fun fact. Better yet, a riddle. IoT, Web 3.0,
Feature Engineering is a process of using domain knowledge to extract and transform features from raw data. These features can be used to improve the performance of Machine Learning Algorithms. Here, we can observe a drastic improvement in our model accuracy when we apply the same algorithm to standardized features.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
R has simplified the most complex task of geospatial machine learning and datascience. As GIS is slowly embracing datascience, mastery of programming is very necessary regardless of your perception of programming. data = trainData) 5.
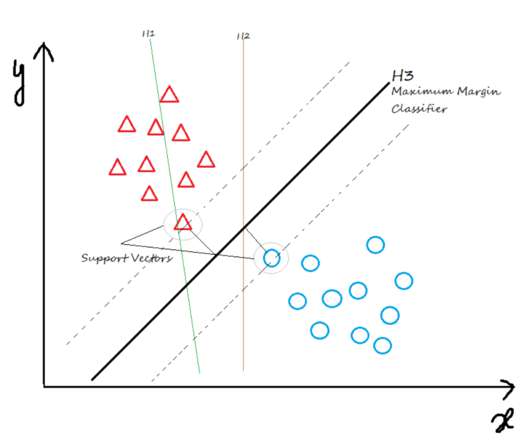
SupportVectorMachine: A Comprehensive Guide — Part1 SupportVectorMachines (SVMs) are a type of supervised learning algorithm used for classification and regression analysis. Submission Suggestions SupportVectorMachine: A Comprehensive Guide — Part1 was originally published in MLearning.ai
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. In DataScience, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset.
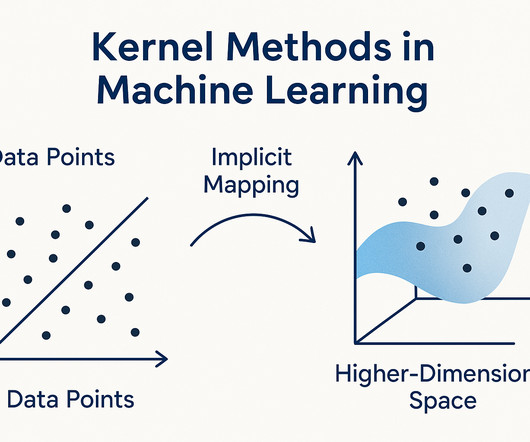
SupportVectorMachine: A Comprehensive Guide — Part2 In my last article, we discussed SVMs, the geometric intuition behind SVMs, and also Soft and Hard margins. So we can use SVM kernels here to transform the data into higher dimensions. But the model can create only 1 best-fit line. BECOME a WRITER at MLearning.ai.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? What is machine learning?
For instance, a classification algorithm could predict whether a transaction is fraudulent or not based on various features. Role of Algorithms in Associative Classification Algorithms play a crucial role in associative classification by automating the rule generation, evaluation, and classification process.
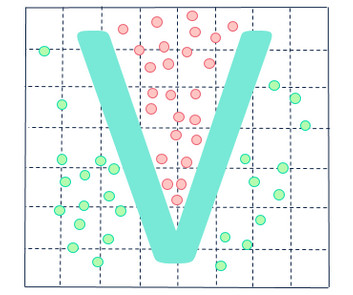
Learn how they work and how to apply them in real-world projects through Pickl.AIs datascience courses. Introduction Machine learning often struggles when the data isnt in a straight lineliterally! This is where kernel methods in machine learning come in like superheroes.
Selecting the right algorithm There are several data mining algorithms available, each with its strengths and weaknesses. When selecting an algorithm, consider factors such as the size and type of your dataset, the problem you’re trying to solve, and the computational resources available.
The field of datascience changes constantly, and some frameworks, tools, and algorithms just can’t get the job done anymore. Machine Learning for Beginners Learn the essentials of machine learning including how SupportVectorMachines, Naive Bayesian Classifiers, and Upper Confidence Bound algorithms work.
ML models often require numerical input, so categorical data must be converted into a numerical format for effective processing and analysis. Here are some key points highlighting the importance of categorical data in machine learning: 1. This conversion allows models to process the data and extract valuable information.
The articles cover a range of topics, from the basics of Rust to more advanced machine learning concepts, and provide practical examples to help readers get started with implementing ML algorithms in Rust. Rust has several libraries and frameworks for machine learning, lets talk about a few of them!
DataScience interviews are pivotal moments in the career trajectory of any aspiring data scientist. Having the knowledge about the datascience interview questions will help you crack the interview. DataScience skills that will help you excel professionally.
Summary: In the tech landscape of 2024, the distinctions between DataScience and Machine Learning are pivotal. DataScience extracts insights, while Machine Learning focuses on self-learning algorithms. DataScience enhances ML accuracy through preprocessing and feature engineering expertise.
Machine learning is playing a very important role in improving the functionality of task management applications. In January, Towards DataScience published an article on this very topic. “In Project managers should be aware of the changes that machine learning has brought to task management applications. Final Thoughts.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Understanding the Principles, Challenges, and Applications of Gradient Descent Image by Author with @MidJourney Introduction to Gradient Descent Gradient descent is a fundamental optimization algorithm used in machine learning and datascience to find the optimal values of the parameters in a model.
With the expanding field of DataScience, the need for efficient and skilled professionals is increasing. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience.
Photo by Andy Kelly on Unsplash Choosing a machine learning (ML) or deep learning (DL) algorithm for application is one of the major issues for artificial intelligence (AI) engineers and also data scientists. Explore algorithms: Research and explore different algorithms that are desired for your problem.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
However, with a wide range of algorithms available, it can be challenging to decide which one to use for a particular dataset. will my data help in this ? If you can understand the data then you even do not need to use all algorithms. Let's understand this in detail.
In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations. However, typical algorithms do not produce a binary result but instead, provide a relevancy score for which labels are the most appropriate. Thus tail labels have an inflated score in the metric.
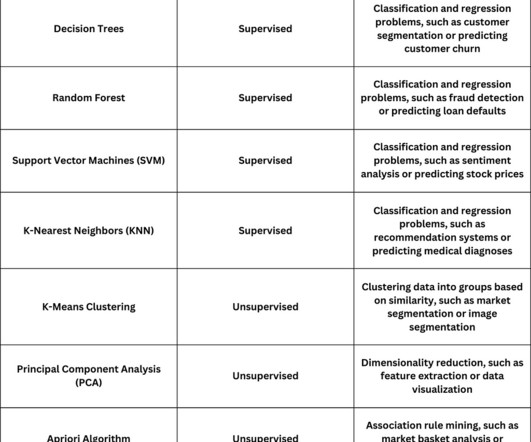
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. What is machine learning? ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. The SVM algorithm requires the tuning of several parameters to achieve optimal performance.
This ongoing process straddles the intersection between evidence-based medicine, datascience, and artificial intelligence (AI). As the capabilities of high-powered computers and ML algorithms have grown, so have opportunities to improve the SLR process.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content