This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SupportVectorMachines (SVM) are a cornerstone of machine learning, providing powerful techniques for classifying and predicting outcomes in complex datasets. By focusing on finding the optimal decision boundary between different classes of data, SVMs have stood out in both academic research and practical applications.
Machine learning practices are the guiding principles that transform raw data into powerful insights. By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machine learning and pave the way for innovation and success.
By employing various methodologies, analysts uncover hidden patterns, predict outcomes, and supportdata-driven decision-making. Understanding these techniques can enhance a datascientist’s toolkit, making it easier to navigate the complexities of big data. What are data science techniques?
Statistics: Unveiling the patterns within data Statistics serves as the bedrock of data science, providing the tools and techniques to collect, analyze, and interpret data. It equips datascientists with the means to uncover patterns, trends, and relationships hidden within complex datasets.
The concept of a kernel in machine learning might initially sound perplexing, but it’s a fundamental idea that underlies many powerful algorithms. There are mathematical theorems that support the working principle of all automation systems that make up a large part of our daily lives. Which type should you prefer?
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. With a hands-on approach, you will find plenty of code and plots to familiarize yourself with clustering: a must-have tool for every datascientist.
For instance, a classification algorithm could predict whether a transaction is fraudulent or not based on various features. Role of Algorithms in Associative Classification Algorithms play a crucial role in associative classification by automating the rule generation, evaluation, and classification process.
ML models often require numerical input, so categorical data must be converted into a numerical format for effective processing and analysis. Here are some key points highlighting the importance of categorical data in machine learning: 1. This conversion allows models to process the data and extract valuable information.
Photo by Andy Kelly on Unsplash Choosing a machine learning (ML) or deep learning (DL) algorithm for application is one of the major issues for artificial intelligence (AI) engineers and also datascientists. Explore algorithms: Research and explore different algorithms that are desired for your problem.
Both of these types of learning are used by machine learning algorithms in modern task management applications. Here is an overview of the supervised learning algorithms that are frequently employed by task management tools. In this way, the degree of “success” of the algorithm can be known. Final Thoughts.
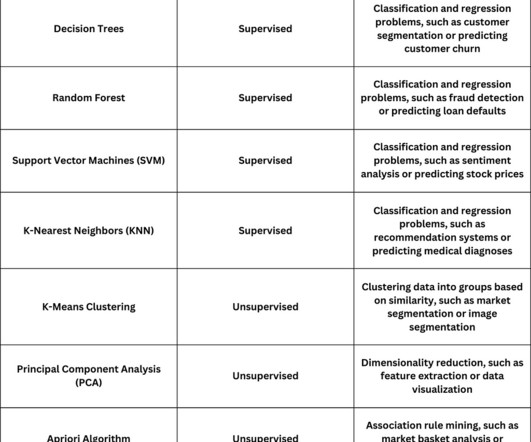
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Each algorithm is explained with its applications, strengths, and weaknesses, providing valuable insights for practitioners and enthusiasts in the field.
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. SupportVectorMachineSupportVectorMachine ( SVM ) is a supervised learning algorithm used for classification and regression analysis.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. What is machine learning? Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences.
This ongoing process straddles the intersection between evidence-based medicine, data science, and artificial intelligence (AI). As the capabilities of high-powered computers and ML algorithms have grown, so have opportunities to improve the SLR process.
This type of machine learning is useful in known outlier detection but is not capable of discovering unknown anomalies or predicting future issues. Regression modeling is a statistical tool used to find the relationship between labeled data and variable data.
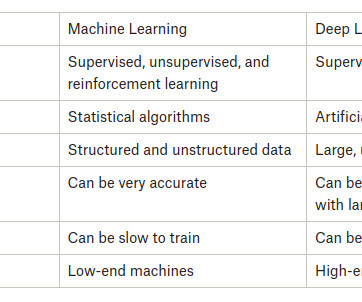
Summary: In the tech landscape of 2024, the distinctions between Data Science and Machine Learning are pivotal. Data Science extracts insights, while Machine Learning focuses on self-learning algorithms. The collective strength of both forms the groundwork for AI and Data Science, propelling innovation.
Revolutionizing Healthcare through Data Science and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machine learning, and information technology.
Data mining, text classification, and information retrieval are just a few applications. To extract themes from a corpus of text data and then use these themes as features in text classification algorithms, topic modeling can be used in text classification. Naive Bayes is commonly used for spam classification.
In the rapidly evolving world of technology, machine learning has become an essential skill for aspiring datascientists, software engineers, and tech professionals. Coursera Machine Learning Courses are an exceptional array of courses that can transform your career and technical expertise.
Just as humans can learn through experience rather than merely following instructions, machines can learn by applying tools to data analysis. Machine learning works on a known problem with tools and techniques, creating algorithms that let a machine learn from data through experience and with minimal human intervention.
Scale-Invariant Feature Transform (SIFT) This is an algorithm created by David Lowe in 1999. It’s a general algorithm that is known as a feature descriptor. After picking the set of images you desire to use, the algorithm will detect the keypoints of the images and store them in a database. It detects corners.
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification.
Empowering DataScientists and Machine Learning Engineers in Advancing Biological Research Image from European Bioinformatics Institute Introduction: In biological research, the fusion of biology, computer science, and statistics has given birth to an exciting field called bioinformatics.
Text Vectorization Techniques Text vectorization is a crucial step in text mining, where text data is transformed into numerical representations that can be processed by Machine Learning algorithms. Sentiment analysis techniques range from rule-based approaches to more advanced machine learning algorithms.
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. Differentiate between supervised and unsupervised learning algorithms.
Introduction Linear Algebra is a fundamental mathematical discipline that underpins many algorithms and techniques in Machine Learning. By understanding Linear Algebra operations, practitioners can better grasp how Machine Learning models work, optimize their performance, and implement various algorithms effectively.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decision trees, and supportvectormachines.
This technology streamlines the model-building process while simultaneously increasing productivity by determining the best algorithms for specific data sets. Moreover, it enhances the productivity of datascientists. It dramatically shortens computing times for complex algorithms.
Photo by Shahadat Rahman on Unsplash Introduction Machine learning (ML) focuses on developing algorithms and models that can learn from data and make predictions or decisions. One of the goals of ML is to enable computers to process and analyze data in a way that is similar to how humans process information.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field.
Solution overview As mentioned earlier, the AWS services that you can use for analysis of mobility data are Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend, and Amazon SageMaker geospatial capabilities. Datascientists can accomplish this process by connecting through Amazon SageMaker notebooks.
Summary: Inductive bias in Machine Learning refers to the assumptions guiding models in generalising from limited data. By managing inductive bias effectively, datascientists can improve predictions, ensuring models are robust and well-suited for real-world applications.
Key concepts in ML are: Algorithms : Algorithms are the mathematical instructions that guide the learning process. They process data, identify patterns, and adjust the model accordingly. Common algorithms include decision trees, neural networks, and supportvectormachines.
Evolution of AI The evolution of Artificial Intelligence (AI) spans several decades and has witnessed significant advancements in theory, algorithms, and applications. Techniques such as decision trees, supportvectormachines, and neural networks gained popularity.
Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. There are three main types of Machine Learning: supervised learning, unsupervised learning, and reinforcement learning.
Key Takeaways Machine Learning Models are vital for modern technology applications. Key steps involve problem definition, data preparation, and algorithm selection. Data quality significantly impacts model performance. Ethical considerations are crucial in developing fair Machine Learning solutions.
As it pertains to social media data, text mining algorithms (and by extension, text analysis) allow businesses to extract, analyze and interpret linguistic data from comments, posts, customer reviews and other text on social media platforms and leverage those data sources to improve products, services and processes.
A key component of artificial intelligence is training algorithms to make predictions or judgments based on data. This process is known as machine learning or deep learning. Two of the most well-known subfields of AI are machine learning and deep learning. What is Machine Learning?
Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many datascientists. It is easy to use, with a well-documented API and a wide range of tutorials and examples available.
Genetic algorithms [ 1 ] are one way to detect faces in a digital image, followed by the Eigenface technique to verify the fitness of the region of interest. We’re committed to supporting and inspiring developers and engineers from all walks of life. We pay our contributors, and we don’t sell ads.
Statistical Analysis Introducing statistical methods and techniques for analysing data, including hypothesis testing, regression analysis, and descriptive statistics. Students should gain a foundational understanding of statistics as it applies to data analytics. Students should learn how to apply machine learning models to Big Data.
Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among datascientists, DevOps engineers, and IT teams. Autonomous Vehicles: Automotive companies are using ML models for autonomous driving systems including object detection, path planning, and decision-making algorithms.
I was interested to see what types of problems were solved and which particular algorithms were used with the different loss functions. I decided that aggregating this data would give me a rough idea about what loss functions were commonly being used to solve the different problems. These are two separate lists).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content