This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As critical data flows across an organization from various business applications, datasilos become a big issue. The datasilos, missing data, and errors make data management tedious and time-consuming, and they’re barriers to ensuring the accuracy and consistency of your data before it is usable by AI/ML.
This bias can be introduced at various stages of the AI development process, from data collection to algorithm design, and it can have far-reaching consequences. For example, a biased AI algorithm used in hiring might favor certain demographics over others, perpetuating inequalities in employment opportunities.
For people striving to rule the data integration and data management world, it should not be a surprise that companies are facing difficulty in accessing and integrating data across system or application datasilos. Not only will this increase the speed but also the accuracy of the data mapping process.
The promise of significant and measurable business value can only be achieved if organizations implement an information foundation that supports the rapid growth, speed and variety of data. This integration is even more important, but much more complex with Big Data. Variables Financial Industry Uses in its Big DataAlgorithms.
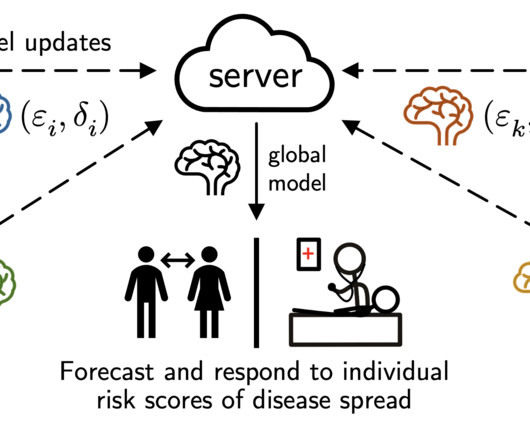
Unfortunately, while this data contains a wealth of useful information for disease forecasting, the data itself may be highly sensitive and stored in disparate locations (e.g., In this post we discuss our research on federated learning , which aims to tackle this challenge by performing decentralized learning across private datasilos.
Launched on February 1st 2023, the contestants of our Air Quality challenge were asked to use Ocean.py’s open-source tool, Compute-to-Data, to publish predictions of air pollutant concentrations in a fully decentralized manner. Contestants also submitted a report about their algorithmic approach to predictions.
Additionally, locally trained information can expose private data if reconstructed through an inference attack. To mitigate these risks, the FL model uses personalized training algorithms and effective masking and parameterization before sharing information with the training coordinator. In such scenarios, you can use FedML Octopus.
Organizations gain the ability to effortlessly modify and scale their data in response to shifting business demands, leading to greater agility and adaptability. This holistic view empowers businesses to make data-driven decisions, optimize processes and gain a competitive edge.
Launched in January 2023, contestants of the ETH price prediction data challenge were asked to engage with the Ocean.py This challenge aimed to activate relevant communities of Web3-native data scientists and guide them towards potential use cases such as community-owned algorithms via data NFTs and DeFi protocol design.
Participants are encouraged to use Ocean Protocol’s technology to decentralize access to their algorithms, and share their solutions with privacy-preserving technology. Catalonia) over the past three decades and develop algorithms to predict air pollutant concentrations. The submission deadline is February 14 @ 23:59 PM UTC.
The Ocean Protocol — Gitcoin DataBuilder hackathon seeks to protect public goods funding and data decentralization by encouraging data scientists around the globe to develop insightful anti-Sybil algorithms and implement them into composable legos while using end-to-end decentralized technologies.
Real-time data analytics helps in quick decision-making, while advanced forecasting algorithms predict product demand across diverse locations. AWS’s scalable infrastructure allows for rapid, large-scale implementation, ensuring agility and data security.
AI began back in the 1950s as a simple series of “if, then rules” and made its way into healthcare two decades later after more complex algorithms were developed. Machine Learning Machine learning (ML) focuses on training computer algorithms to learn from data and improve their performance, without being explicitly programmed.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed datasilos, lack of sufficient data at any single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
The role of digit-computers in the digital age Handle multi-user access & data integrity OLTP systems must be able to handle multiple users accessing the same data simultaneously while ensuring data integrity. Building in these characteristics at a later stage can be costly and resource-intensive.
Launched in November 2022, contestants of the ETH price prediction data challenge were asked to engage with Ocean.py This challenge aimed to activate relevant communities of Web3-native data scientists and guide them towards potential use cases such as community-owned algorithms via data NFTs and DeFi protocol design.
Assess the uniqueness and viability of the AI algorithms being used, as well as their potential applications in real-world scenarios. Its privacy-preserving features make it ideal for applications that require sensitive data, such as healthcare and financial services. Data security : Data can be vulnerable to security risks.
Modeling ¶ Most teams experimented with a variety of modeling algorithms, and many noted that the privacy techniques in their solutions could be paired with more than one family of machine learning models. We are excited to take on this challenge and continue pushing the boundaries of machine learning research.
Yet there is often lack of awareness of the trustworthiness (or lack thereof) of the data that these algorithms are being trained on. It is commonplace for a company to create an enterprise data governance strategy that fails to even consider the end user. Roadblock #3: Silos Breed Misunderstanding.
In addition, digital transformation initiatives have created the proliferation of applications, creating datasiloes. It can allow you to empower users from all areas of your business to identify and act on situations in the moment, helping them avoid getting lost in algorithms, heavy code, or disparate data sources.
She goes on to explain the one of the most beneficial features of One Data’s enabling technology, One Data Cartography , is record linkage combined with data quality. This feature enables holistic and seamless data tracking across system boundaries, based on algorithms and automatic checks for quality anomalies.
In other cases, the details of why an AI algorithm reached a certain outcome are not publicly available because the companies that developed them consider the information proprietary. Critics warn such algorithms could erode democracy. That’s often called the “black-box problem.”
Some of the key benefits of this include: Simplified data governance Data governance and data analytics support each other, and a strong data governance strategy is integral to ensuring that data analytics are reliable and actionable for decision-makers.
Efficiency emphasises streamlined processes to reduce redundancies and waste, maximising value from every data point. Common Challenges with Traditional Data Management Traditional data management systems often grapple with datasilos, which isolate critical information across departments, hindering collaboration and transparency.
They use advanced algorithms to proactively identify and resolve network issues, reducing downtime and improving service to their subscribers. Location-based data is often subject to additional regulatory requirements as well, further adding to the challenges of spatial data governance.
About Ocean Protocol Ocean Protocol is an ecosystem of open source data sharing tools for the blockchain. Ocean Protocol is spearheading the movement to unlock a New Data Economy in Web3 by breaking down datasilos and opening access to high quality data.
Insurance companies often face challenges with datasilos and inconsistencies among their legacy systems. To address these issues, they need a centralized and integrated data platform that serves as a single source of truth, preferably with strong data governance capabilities.
However, achieving success in AI projects isn’t just about deploying advanced algorithms or machine learning models. The real challenge lies in ensuring that the data powering your projects is AI-ready. Above all, you must remember that trusted AI starts with trusted data. Is it contextualized with necessary third-party data?
Integration capabilities allow businesses to connect their SolaaS solution with their existing software ecosystem, ensuring smooth data exchange and eliminating datasilos. Together, humans and algorithms collaborate to provide an effective and enduring solution.
So, what is Data Intelligence with an example? For example, an e-commerce company uses Data Intelligence to analyze customer behavior on their website. Through advanced analytics and Machine Learning algorithms, they identify patterns such as popular products, peak shopping times, and customer preferences.
For example, feeding an algorithm statistics about consumer purchasing behavior from stores in one location might lead to poor optimization in another because the data might not be applicable. A retailer must connect datasilos across the entire organization for proper consolidation. The underlying issue is quality.
Some of the key benefits of this include: Simplified data governance Data governance and data analytics support each other, and a strong data governance strategy is integral to ensuring that data analytics are reliable and actionable for decision-makers.
Introduction Machine Learning has evolved significantly, from basic algorithms to advanced models that drive today’s AI innovations. It also enables models to be trained on diverse data sources, potentially leading to better generalisation and performance. Examples include Google’s predictive text and healthcare applications.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed datasilos, lack of sufficient data at a single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
This means figuring out the best result out of many possible outcomes, which is almost impossible to hardcode in an RPA algorithm with classical automation methods. Agents will be more adaptable and robust than conventional robotic process automation (RPA) for longtail and highly extensive tasks.
These pipelines assist data scientists in saving time and effort by ensuring that the data is clean, properly formatted, and ready for use in machine learning tasks. Moreover, ETL pipelines play a crucial role in breaking down datasilos and establishing a single source of truth.
Unified Data Fabric Unified data fabric solutions enable seamless access to data across diverse environments, including multi-cloud and on-premise systems. These solutions break down datasilos, making it easier to integrate and analyse data from various sources in real-time.
The problem many companies face is that each department has its own data, technologies, and information handling processes. This causes datasilos to form, which can inhibit data visibility and collaboration, and lead to integrity issues that make it harder to share and use data.
User Experience Monitoring (UEM): User behavior data, application responsiveness Event Correlation and Anomaly Detection The collected data is a massive stream of events. It employs sophisticated algorithms to identify patterns, trends, and anomalies that deviate from established baselines.
Data growth, shrinking talent pool, datasilos – legacy & modern, hybrid & cloud, and multiple tools – add to their challenges. According to Gartner, “Through 2025, 80% of organizations seeking to scale digital business will fail because they do not take a modern approach to data and analytics governance.”.
Rules Engine This is the brain of the CDSS, employing complex algorithms to analyze patient data against the knowledge base. The rules engine acts like a tireless medical consultant, constantly evaluating patient data and recommending the most suitable course of action based on the latest medical knowledge.
Let’s break down why this is so powerful for us marketers: Data Preservation : By keeping a copy of your raw customer data, you preserve the original context and granularity. It’s like being able to go back and re-examine every piece of evidence in your customer relationship journey.
Find, curate, or contribute data to create representative and open datasets that can be used for early prediction of AD/ADRD. Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Dr. Reid also teaches Data Science at the University of California at Berkeley.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content