This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark).
Business users will also perform data analytics within business intelligence (BI) platforms for insight into current market conditions or probable decision-making outcomes. Many functions of data analytics—such as making predictions—are built on machine learning algorithms and models that are developed by data scientists.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
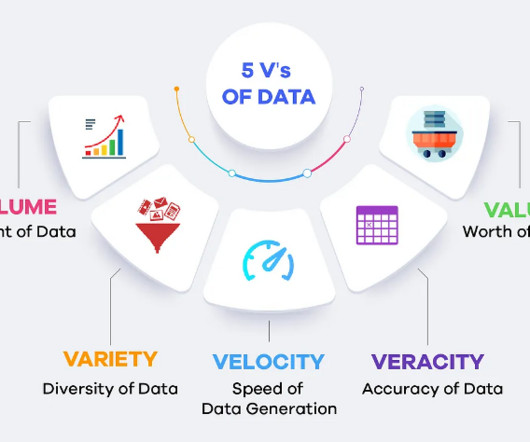
First, lets understand the basics of Big Data. Key Takeaways Understand the 5Vs of Big Data: Volume, Velocity, Variety, Veracity, Value. Familiarise yourself with essential tools like Hadoop and Spark. Practice coding skills in languages relevant to Big Data roles. What are the Main Components of Hadoop?
Just as humans can learn through experience rather than merely following instructions, machines can learn by applying tools to data analysis. Machine learning works on a known problem with tools and techniques, creating algorithms that let a machine learn from data through experience and with minimal human intervention.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
By matching landmarks on the human face or identifying patterns in speech rate, pitch range, intensity, and voice quality, AI is able to detect human emotions — some algorithms can even detect 10-different emotions. AI is not a fad, algorithmic decision-making is inevitable. Human Curation + Machine Learning.
The real advantage of big data lies not just in the sheer quantity of information but in the ability to process it in real-time. Variety Data comes in a myriad of formats including text, images, videos, and more. Veracity Veracity relates to the accuracy and trustworthiness of the data.
With a few taps on a mobile device, riders request a ride; then, Uber’s algorithms work to match them with the nearest available driver and calculate the optimal price. It can ingest data from offline batch data sources (such as Hadoop and flat files) as well as online data sources (such as Kafka).
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a datawarehouse or data lake. Data Lakes: These store raw, unprocessed data in its original format.
In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Having a solid understanding of ML principles and practical knowledge of statistics, algorithms, and mathematics. Which service would you use to create DataWarehouse in Azure?
NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data. DataWarehouses : Centralised repositories optimised for analytics and reporting. Data Lakes : Scalable storage for raw and processed data, supporting diverse data types.
We use data-specific preprocessing and ML algorithms suited to each modality to filter out noise and inconsistencies in unstructured data. NLP cleans and refines content for text data, while audio data benefits from signal processing to remove background noise. Such algorithms are key to enhancing data.
Introduction to Big Data Tools In todays data-driven world, organisations are inundated with vast amounts of information generated from various sources, including social media, IoT devices, transactions, and more. Big Data tools are essential for effectively managing and analysing this wealth of information. Use Cases : Yahoo!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content