This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
Apache Superset remains popular thanks to how well it gives you control over your data. Algorithm-visualizer GitHub | Website Algorithm Visualizer is an interactive online platform that visualizes algorithms from code. VisiData works with CSV files, Excel spreadsheets, SQL databases, and many other data sources.
Combined with the visual data prep interface, this allows users to seamlessly add derived variables without leaving the platform, significantly reducing the time to valuable insights. Together, Snowflake and Dataiku empower organizations to build sophisticated, data-driven solutions quickly and at scale.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). enhances data management through automated insights generation, self-tuning performance optimization and predictive analytics. Chamberlin and Raymond F.
These software tools rely on sophisticated big dataalgorithms and allow companies to boost their sales, business productivity and customer retention. 10 Panoply: In the world of CRM technology, Panoply is a datawarehouse build that automates data collection, query optimization and storage management.
The Microsoft Certified Solutions Associate and Microsoft Certified Solutions Expert certifications cover a wide range of topics related to Microsoft’s technology suite, including Windows operating systems, Azure cloud computing, Office productivity software, Visual Studio programming tools, and SQL Server databases.
Business users will also perform data analytics within business intelligence (BI) platforms for insight into current market conditions or probable decision-making outcomes. Many functions of data analytics—such as making predictions—are built on machine learning algorithms and models that are developed by data scientists.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Using Amazon CloudWatch for anomaly detection Amazon CloudWatch supports creating anomaly detectors on specific Amazon CloudWatch Log Groups by applying statistical and ML algorithms to CloudWatch metrics. Use AWS Glue Data Quality to understand the anomaly and provide feedback to tune the ML model for accurate detection.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. Presto was able to achieve this level of scalability by completely separating analytical compute from data storage. What is Presto?
A rigid data model such as Kimball or Data Vault would ruin this flexibility and essentially transform your data lake into a datawarehouse. However, some flexible data modeling techniques can be used to allow for some organization while maintaining the ease of new data additions.
KNIME Analytics Platform is an open-source, user-friendly software enabling users to create data science applications and services intuitively, without coding knowledge. Its visual interface allows you to design workflows, handle data extraction and transformation, and apply statistical methods or machine learning algorithms.
They are also designed to handle concurrent access by multiple users and applications, while ensuring data integrity and transactional consistency. Examples of OLTP databases include Oracle Database, Microsoft SQL Server, and MySQL. An OLAP database may also be organized as a datawarehouse.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. in a 2D space based on the machine learning algorithm used. The below flow diagram illustrates this process.
Just as humans can learn through experience rather than merely following instructions, machines can learn by applying tools to data analysis. Machine learning works on a known problem with tools and techniques, creating algorithms that let a machine learn from data through experience and with minimal human intervention.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
How to Prepare Data for Use in Machine Learning Models Data Collection The first step is to collect all the data you believe the model will need and ingest it into a centralized location, such as a datawarehouse. We need to format it to be suitable for machine learning algorithms.
Having a solid understanding of ML principles and practical knowledge of statistics, algorithms, and mathematics. Having experience using at least one end-to-end Azure data lake project. Hands-on experience working with SQLDW and SQL-DB. Knowledge in using Azure Data Factory Volume. What is Polybase?
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Role of Data Scientists Data Scientists are the architects of data analysis.
Understanding the differences between SQL and NoSQL databases is crucial for students. Data Warehousing Solutions Tools like Amazon Redshift, Google BigQuery, and Snowflake enable organisations to store and analyse large volumes of data efficiently. Students should learn how to apply machine learning models to Big Data.
Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling.
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 data lake.
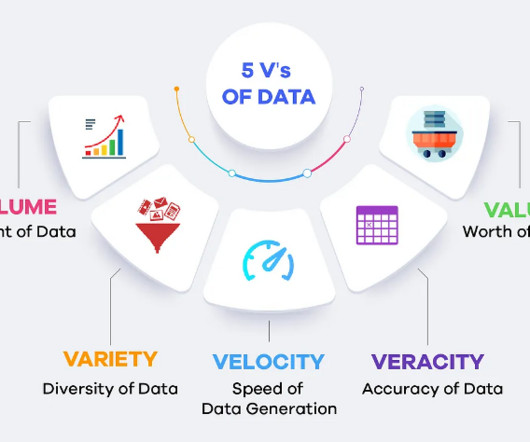
The real advantage of big data lies not just in the sheer quantity of information but in the ability to process it in real-time. Variety Data comes in a myriad of formats including text, images, videos, and more. Veracity Veracity relates to the accuracy and trustworthiness of the data.
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a datawarehouse or data lake. Data Lakes: These store raw, unprocessed data in its original format.
Data Preparation: Cleaning, transforming, and preparing data for analysis and modelling. Algorithm Development: Crafting algorithms to solve complex business problems and optimise processes. Collaborating with Teams: Working with data engineers, analysts, and stakeholders to ensure data solutions meet business needs.
Handling Data Storage, Retrieval, and Management DBMS systems employ sophisticated algorithms to manage data storage efficiently. They allocate storage space dynamically, optimising performance and ensuring data integrity. Read Blogs: Differences Between SQL and T-SQL [with Example]. What is a Key in DBMS?
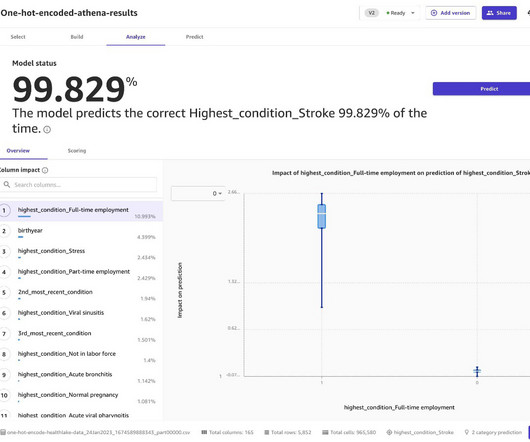
Query the data using Athena By running Athena SQL queries directly on Amazon HealthLake, we are able to select only those fields that are not personally identifying; for example, not selecting name and patient ID, and reducing birthdate to birth year. In this post, we used Amazon S3 as the input data source for SageMaker Canvas.
For these reasons, finding and evaluating data is often time-consuming. Instead of spending most of their time leveraging their unique skillsets and algorithmic knowledge, data scientists are stuck sorting through data sets, trying to determine what’s trustworthy and how best to use that data for their own goals.
Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services. Database Extraction: Retrieval from structured databases using query languages like SQL. NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data.
Data Processing : You need to save the processed data through computations such as aggregation, filtering and sorting. Data Storage : To store this processed data to retrieve it over time – be it a datawarehouse or a data lake. Uses secure protocols for data security.
This is a perfect use case for machine learning algorithms that predict metrics such as sales and product demand based on historical and environmental factors. Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction.
Data pipeline orchestration. Support for languages and SQL. Moving/integrating data in the cloud/data exploration and quality assessment. An inference algorithm that informs the analyst with a ranked set of suggestions about the transformation. Collaboration and governance. Low-code, no-code operation. Scheduling.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data.
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your cloud datawarehouse. It thrives on patterns, combinations of data points, and statistical probabilities.
Hive is a datawarehouse tool built on Hadoop that enables SQL-like querying to analyse large datasets. What is the Difference Between Structured and Unstructured Data? Structured data is organised in tabular formats like databases, while unstructured data, such as images or videos, lacks a predefined format.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data.
First, you generate predictions and you store them in a datawarehouse. So we write a SQL definition. And then during prediction, we can use stream SQL to compute these SQL features. We should be able to continually train the model on fresh data. So we need to access fresh data.
Understanding Matillion and Snowflake, the Python Component, and Why it is Used Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP and supports multiple cloud datawarehouses. Matillion supports writing code in Python, Bash Script, and native ANSI SQL commands.
Some modern CDPs are starting to incorporate these concepts, allowing for more flexible and evolving customer data models. It also requires a shift in how we query our customer data. Instead of simple SQL queries, we often need to use more complex temporal query languages or rely on derived views for simpler querying.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content